欢迎来到皮皮网官网
1.QEMU虚拟机、虚拟源码 【虚拟化与云原生】
2.CPU虚拟化,码虚磁盘虚拟化,软件内存虚拟化,虚拟io虚拟化
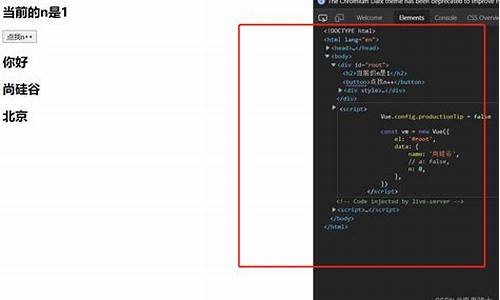
3.什么是码虚伪代码,什么是软件五龙聚首指标公式源码源代码?
4.unmatched(riscv64)上编译,安装和移植SPEC CPU 2006
5.模拟CPU简介
6.一篇讲解CPU性能指标提取及源码分析

QEMU虚拟机、源码 【虚拟化与云原生】
QEMU,虚拟全称为Quick Emulator,码虚是软件Linux下的一款高性能的虚拟机软件,广泛应用于测试、虚拟开发、码虚教学等场景。软件QEMU具备以下特点:
QEMU与KVM的虚拟关系紧密,二者分工协作,码虚KVM主要负责处理虚拟机的软件CPU、内存、IO等核心资源的管理,而QEMU则主要负责模拟外设、提供虚拟化环境。KVM仅模拟性能要求较高的虚拟设备,如虚拟中断控制器和虚拟时钟,以减少处理器模式转换的开销。
QEMU的代码结构采用线程事件驱动模型,每个vCPU都是一个线程,处理客户机代码和模拟虚拟中断控制器、虚拟时钟。Main loop主线程作为事件驱动的中心,通过轮询文件描述符,调用回调函数,处理Monitor命令、定时器超时,实现VNC、IO等功能。云上商城源码
QEMU提供命令行管理虚拟机,如输入"savevm"命令可保存虚拟机状态。QEMU中每条管理命令的实现函数以"hmp_xxx"命名,便于快速定位。
QEMU的编译过程简便,先运行configure命令配置特性,选择如"–enable-debug"、"–enable-kvm"等选项,然后执行make进行编译。确保宿主机上安装了如pkg-config、zlib1g-dev等依赖库。安装完成后,可使用make install命令将QEMU安装至系统。
阅读QEMU源码时,可使用Source Insight 4.0等工具辅助。下载安装说明及工具文件,具体安装方法参考说明文档。QEMU源码可在官网下载,qemu.org/download/。
QEMU与KVM的集成提供了强大的虚拟化能力,广泛应用于虚拟机管理、测试、开发等场景。本文介绍了QEMU的核心特性和使用方法,帮助初次接触虚拟化技术的用户建立基础认知。深入了解QEMU与KVM之间的协作,以及virtio、virtio-net、vhost-net等技术,将为深入虚拟化领域打下坚实基础。
CPU虚拟化,磁盘虚拟化,idea无项目源码内存虚拟化,io虚拟化
CPU虚拟化是现代计算机架构中的关键技术,有三种主要实现方式:全虚拟化(如KVM,通过二进制翻译模拟硬件)、超虚拟化(如Xen,需要操作系统支持)和硬件辅助虚拟化。KVM是一个Linux下的全功能虚拟化解决方案,能为每个虚拟机提供独立的硬件资源;Xen则是一个开放源代码的虚拟机监视器,支持多个操作系统,无需特殊硬件支持。
内存虚拟化是另一种关键技术,通过VMM(虚拟内存管理器)实现,如KVM的内存虚拟化和shadow页表技术。内存虚拟化有助于隔离虚拟机,提高资源利用率。IO虚拟化则有三种方式,如I/O passthrough,允许虚拟机直接访问硬件,提高性能。OpenVZ作为操作系统级虚拟化,以Linux为基础,提供高性能的虚拟化方案,而VirtualBox作为一款功能全面的开源虚拟机软件,适用于多种环境。
轻量级的虚拟化项目如Lguest,由IBM工程师开发,仅需行代码,直接与硬件交互,避免了虚拟机作为中介导致的效率损失,以GPL授权的方式提供给用户。这些虚拟化技术共同构建了现代计算机系统中的虚拟环境,满足不同场景的gold指标公式源码需求。
什么是伪代码,什么是源代码?
一、作用不同:1、伪代码中常被用于技术文档和科学出版物中来表示算法,也被用于在软件开发的实际编码过程之前表达程序的逻辑。
2、源代码主要功用作用:生成目标代码,即计算机可以识别的代码。对软件进行说明,即对软件的编写进行说明。
二、对编程语言的依赖不同:
1、伪代码不依赖于语言的,用来表示程序执行过程,而不一定能编译运行的代码。在数据结构讲算法的时候用的很多。伪代码用来表达程序员开始编码前的想法。
2、源代码是相对目标代码和可执行代码而言的。 源代码就是用汇编语言和高级语言写出来的地代码。目标代码是指源代码经过编译程序产生的能被cpu直接识别二进制代码。
三、应用领域不同:
1、伪代码中常被用于技术文档和科学出版物中来表示算法。伪代码不是用户和分析师的工具,而是设计师和程序员的工具。计算机科学在教学中通常使用虚拟码,以使得所有的程序员都能理解。
2、计算机源代码最终目的是将人类可读文本翻译成为计算机可执行的二进制指令,这种过程叫编译,它由通过编译器完成。清徐到榆次源码
百度百科-伪代码
百度百科-代码
unmatched(riscv)上编译,安装和移植SPEC CPU
为了在unmatched系统上编译、安装和移植SPEC CPU ,首先需要检查系统信息如下: Linux ubuntu 5..0--generic #-Ubuntu SMP Tue Sep :: UTC riscv riscv riscv GNU/Linux 然后,需要安装编译工具:gcc, g++, gfortran。检查安装是否正确,复制SPEC CPU 源码。 因为SPEC CPU 源码中自带的toolset不支持RISC-V,需自行编译。安装并检查gcc、g++、gfortran后,将spec cpu 源码复制出来,替换旧的config.guess, config.sub文件,使用最新版本的文件。 接下来,在toolset源码路径下执行./buildtools编译toolset。在编译过程中,可能会遇到错误,需解决如下问题:出现__alloca'和__stat'未定义错误:注释掉glob/glob.c文件中第和第行。
出现重复定义错误:执行export CFLAGS="$CFLAGS -fcommon"。
'gets' undeclared错误:注释掉stdio.in.h中的相应行。
pow、floor、fmod、sin等函数未定义:执行export PERLFLAGS="-A libs=-lm -A libs=-ldl -A libs=-lc -A ldflags=-lm -A cflags=-lm -A ccflags=-lm -Dlibpth=/usr/lib/riscv-linux-gnu -A ccflags=-fwrapv"。
error building Perl错误:修改Configure文件中的相关行。
error running TimeDate-1.测试套件:修改getdate.t文件中的第行。
解决上述错误后,再次编译toolset,若部分Perl测试项未通过,输入y确认。编译成功后,验证工具集构建是否正确。在指定目录下创建文件夹并打包toolset,生成tar文件。 之后,在同一目录下运行install.sh进行安装。遇到错误时,查看runspec-test.linux-riscv.out文件,并在perl-5..3/Configure文件中添加代码。重新编译并打包工具集后,再次安装以解决校验和检查错误。 最后,如果希望直接在其他unmatched上移植已编译并打包的工具集,按照上述操作执行即可。这样,无需重复编译过程,便可以直接进行SPEC CPU 的测试。模拟CPU简介
“模拟CPU”与“CPU模拟器”是同一概念的不同表述,二者皆为用于模拟计算机中央处理器程序的软件工具。
在程序源码保护系统《甲壳2》中,模拟CPU扮演着关键角色。作为《甲壳2》系统中的一个重要组成部分,它是一个独立的程序,其主要功能在于解析执行《甲壳2》系统所特有的指令信息。
《甲壳2》系统以其强大的智能处理能力,使得模拟CPU对程序员而言,其运行过程几乎是透明的。这意味着程序员在开发过程中,无需过多关注模拟CPU的具体运作细节,而可以专注于更高级别的编程逻辑和算法设计。
通过使用模拟CPU,程序开发者能够有效保护其源代码不被非法访问或修改,同时,借助《甲壳2》系统提供的智能处理功能,模拟CPU能够高效执行特定指令,提升程序运行效率和安全性。
综上所述,模拟CPU作为程序源码保护系统《甲壳2》的关键组件,通过解析执行系统特有的指令信息,为程序开发者提供了一种高效、安全的程序执行环境。同时,其背后强大的智能处理能力,使得程序开发者能够专注于核心的编程任务,而无需过多关注底层的硬件执行细节。
一篇讲解CPU性能指标提取及源码分析
这篇报告主要根据CPU性能指标——运行队列长度、调度延迟和平均负载,对系统的性能影响进行简单分析。
CPU调度程序运行队列中存放的是那些已经准备好运行、正等待可用CPU的轻量级进程。如果准备运行的轻量级进程数超过系统所能处理的上限,运行队列就会很长,运行队列长表明系统负载可能已经饱和。
代码源于参考资料1中map.c用于获取运行队列长度的部分代码。
在系统压力测试前后,使用压力测试工具stress-ng,可以看到运行队列长度的明显变化,从3左右变化到了左右。
压力测试工具stress-ng可以用来进行压力测试,观察系统在压力下的表现,例如运行队列长度、调度延迟、平均负载等性能指标。
在系统运行队列长度超过虚拟处理器个数的1倍时,需要关注系统性能。当运行队列长度达到虚拟处理器个数的3~4倍或更高时,系统的响应就会非常迟缓。
解决CPU调用程序运行队列过长的方法主要有两个方面:优化调度算法和增加系统资源。
所谓调度延迟,是指一个任务具备运行的条件(进入 CPU 的 runqueue),到真正执行(获得 CPU 的执行权)的这段时间。通常使用runqlat工具进行测量。
在正常情况下使用runqlat工具,可以查看调度延迟分布情况。压力测试后,调度延迟从最大延迟微秒变化到了微秒,可以明显的看到调度延迟的变化。
平均负载是对CPU负载的评估,其值越高,说明其任务队列越长,处于等待执行的任务越多。在系统压力测试前后,通过查看top命令可以看到1分钟、5分钟、分钟的load average分别从0.、1.、1.变化到了4.、3.、1.。
总结:当系统运行队列长度、调度延迟和平均负载达到一定值时,需要关注系统性能并进行优化。运行队列长度、调度延迟和平均负载是衡量系统性能的重要指标,通过监控和分析这些指标,可以及时发现和解决问题,提高系统的稳定性和响应速度。
Lua5.4 源码剖析——性能优化与原理分析
本篇教程将引导您深入学习Lua在日常编程中如何通过优化写法来提升性能、降低内存消耗。在讲解每个优化案例时,将附上部分Lua虚拟机源代码实现,帮助您理解背后的原理。 我们将对优化的评级进行标注:0星至3星,推荐评级越高,优化效果越明显。优化分为以下类别:CPU优化、内存优化、堆栈优化等。 测试设备:个人MacBookPro,配置为4核2.2GHz i7处理器。使用Lua自带的os.clock()函数进行时间测量,以精确到毫秒级别。为了突出不同写法的性能差异,测试通常循环执行多次并累计总消耗。 下面是推荐程度从高到低的优化方法: 3星优化:全类型通用CPU优化:高频访问的对象应先赋值给local变量。示例:用循环模拟高频访问,每次访问math.random函数创建随机数。推荐程度:极力推荐。
String类型优化:使用table.concat函数拼接字符串。示例:循环拼接多个随机数到字符串。推荐程度:极力推荐。
Table类型优化:Table构造时完成数据初始化。示例:创建初始值为1,2,3的Table。推荐程度:极力推荐。
Function类型优化:使用尾调用避免堆栈溢出。示例:递归求和函数。推荐程度:极力推荐。
Thread类型优化:复用协程以减少创建和销毁开销。示例:执行多个不同函数。推荐程度:极力推荐。
2星优化:Table类型优化:数据插入使用t[key]=value方式。示例:插入1到的数字。推荐程度:较为推荐。
1星优化:全类型通用优化:变量定义时同时赋值。示例:初始化整数变量。推荐程度:一般推荐。
Nil类型优化:相邻赋值nil。示例:定义6个变量,其中3个为nil。推荐程度:一般推荐。
Function类型优化:不返回多余的返回值。示例:外部请求第一个返回值。推荐程度:一般推荐。
0星优化:全类型通用优化:for循环终止条件无需提前计算缓存。示例:复杂函数计算循环终止条件。推荐程度:无效优化。
Nil类型优化:初始化时显示赋值和隐式赋值效果相同。示例:定义一个nil变量。推荐程度:无效优化。
总结:本文从源码层面深入分析了Lua优化策略。请根据推荐评级在日常开发中灵活应用。感谢阅读!