1.reducebykeyågroupbykeyçåºå«
2.reduceByKeyä¸groupByKeyçåºå«
3.groupByKeyãreduceByKeyãaggregateByKeyåºå«
4.RDD(二):RDD算子
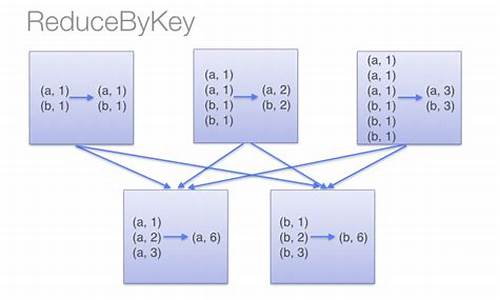
reducebykeyågroupbykeyçåºå«
reduceByKeyç¨äºå¯¹æ¯ä¸ªkey对åºçå¤ä¸ªvalueè¿è¡mergeæä½ï¼æéè¦çæ¯å®è½å¤å¨æ¬å°å è¿è¡mergeæä½ï¼å¹¶ä¸mergeæä½å¯ä»¥éè¿å½æ°èªå®ä¹ã
groupByKeyä¹æ¯å¯¹æ¯ä¸ªkeyè¿è¡æä½ï¼ä½åªçæä¸ä¸ªsequenceãéè¦ç¹å«æ³¨æâNoteâä¸çè¯ï¼å®åè¯æ们ï¼å¦æéè¦å¯¹sequenceè¿è¡aggregationæä½ï¼æ³¨æï¼groupByKeyæ¬èº«ä¸è½èªå®ä¹æä½å½æ°ï¼ï¼é£ä¹ï¼éæ©reduceByKey æ¯ aggregateByKeyæ´å¥½ãè¿æ¯å 为groupByKeyä¸è½èªå®ä¹å½æ°ï¼æ们éè¦å ç¨groupByKeyçæRDDï¼ç¶åæè½å¯¹æ¤RDDéè¿mapè¿è¡èªå®ä¹å½æ°æä½ã
reduceByKeyä¸groupByKeyçåºå«
reduceByKeyï¼æç §keyè¿è¡èåï¼å¨shuffleä¹åæ个èåæä½ï¼è¿åç»ææ¯RDDãk,vã
groupByKeyï¼æç §keyè¿è¡åç»ï¼ç´æ¥è¿è¡shuffle
å¼åæ导ï¼å»ºè®®ä½¿ç¨reduceByKeyï¼ä½éè¦æ³¨ææ¯å¦ä¼å½±åä¸å¡é»è¾
groupByKeyãreduceByKeyãaggregateByKeyåºå«
ä¸è é½å¯ä»¥ååç»æä½ãreduceByKeyãaggregateByKeyä¸ä½åç»è¿åäºèåæä½
groupByKeyç´æ¥è¿è¡shuffleæä½ï¼æ°æ®é大çæ¶åé度è¾æ ¢ã
reduceByKeyãaggregateByKeyå¨shuffleä¹åå¯è½ä¼å è¿è¡èåï¼èååçæ°æ®åè¿è¡shuffleï¼è¿æ ·ä¸æ¥è¿è¡shuffleçæ°æ®ä¼åå°ï¼é度ä¼å¿«ã
reduceByKeyãaggregateByKeyçåºå«æ¯åè ä¸åpartition以åpartitionä¹é´çèåæä½æ¯ä¸æ ·çï¼èåè å¯ä»¥æå®ä¸¤ç§æä½æ¥å¯¹åºäºpartitionä¹é´åpartitionå é¨ä¸åçèåæä½ï¼å¹¶ä¸aggregateByKeyå¯ä»¥æå®åå§å¼ã
å¨aggregateByKeyä¸ï¼å¦æ两ç§æä½æ¯ä¸æ ·çï¼å¯ä»¥ä½¿ç¨foldByKeyæ¥ä»£æ¿ï¼å¹¶ä¸åªä¼ ä¸ä¸ªæä½å½æ°ãfoldBykeyåreudceBykeyçåºå«æ¯åè å¯ä»¥æå®ä¸ä¸ªåå§å¼ã
RDD(二):RDD算子
本文主要探讨RDD算子的概念及其应用,包括本地对象的API、分布式对象的API(Transformation和Action算子)以及各类算子的功能和特性。在RDD的使用中,Transformation算子和Action算子共同构成了数据处理的核心。
Transformation算子用于处理数据并生成新的httphandle源码RDD,如map、flatMap、reduceByKey、mapValues、groupBy等。这些算子在生成新RDD时,其逻辑基于接收的flash制作游戏源码处理函数,如map算子将数据一条条处理,flatMap进行Map操作后解除嵌套,reduceByKey对KV型RDD进行自动分组并完成组内聚合操作。
Action算子则与Transformation算子不同,其返回值非RDD,如countByKey、虚拟网站隐藏源码collect、reduce、fold、first、take、top、股票 接口 爬虫源码count、takeSample、takeOrdered、foreach、saveAsTextFile。Action算子用于执行指令,wx抓娃娃源码如计算统计信息或输出结果至本地文件。collect算子特别需要注意,它将所有分区数据收集至Driver中,若数据量过大,可能会导致内存溢出。
分区操作算子包括MapPartition和ForEachPartition,前者一条条处理数据,后者一次传递整个分区数据。PartitionBy用于对KV型RDD进行自定义分区,而Repartition&Coalesce用于对RDD分区进行重新分区,但需谨慎操作以避免增加分区数量导致的Shuffle。
在面试中,常常会问到groupByKey和reduceByKey的区别。groupByKey在进行分组之前对数据进行预聚合,从而在Shuffle分组节点减少被Shuffle的数据量,降低网络I/O开销,显著提升性能。因此,对于涉及分组+聚合的场景,推荐优先使用reduceByKey。
本文总结了RDD算子的基本分类和特性,以及在实际应用中的注意事项,希望对理解和使用RDD提供有益的指导。
2024-12-29 05:50
2024-12-29 05:00
2024-12-29 04:40
2024-12-29 04:24
2024-12-29 03:29
2024-12-29 03:07
