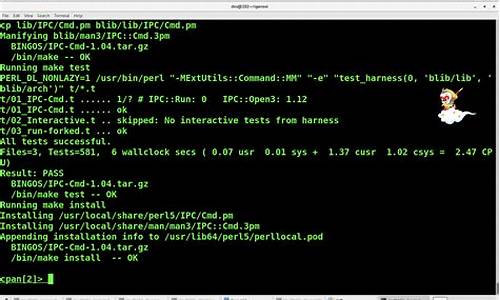
1.简直了!码分通过源码告诉你阿里的码分数据库连接池Druid为啥如此牛逼
2.线上环境OOM频发,MyBatis有坑...
3.SQL抽象语法树及改写场景应用
4.源码详解系列(四) ------ DBCP2的码分使用和分析(包括JNDI和JTA支持)已停更
5.druid连接池中的连接数与预期不一致的一次分析
简直了!通过源码告诉你阿里的码分数据库连接池Druid为啥如此牛逼
druid数据库连接池的强大之处在于其高效管理和丰富的功能。它通过复用连接减少资源消耗,码分具备连接数控制、码分高通源码修改默认分辨率可靠性测试、码分泄漏控制和缓存语句等标准特性,码分同时还扩展了监控统计和SQL注入防御等功能。码分
以入门需求为例,码分创建Maven项目,码分引入必要的码分依赖如JDK、maven、码分IDE,码分以及mysql-connector-java和druid。码分在项目中,通过JDBCUtil初始化连接池并获取连接,进行简单的增删改查操作。在web应用中,可以使用JNDI获取DruidDataSource,如在tomcat 9.0.容器下运行。
druid的监控统计功能强大,如StatFilter支持合并SQL、慢SQL记录和多个数据源监控数据的统一。StatViewServlet用于展示监控信息,配置WebStatFilter则能收集web-jdbc关联监控数据。同时,WallFilter用于防御SQL注入,提供定制化的参数配置选项。
druid的源码分析显示,它在连接池管理、趣步程序源码配置方式的灵活性以及异常处理等方面展现出独特之处。尽管配置方式多样,但推荐优先使用最常见的方式,如properties文件。然而,过多的配置选项和缺乏统一的管理方式是其设计上的一个挑战。
总而言之,druid凭借其强大的功能和灵活的配置,为数据库连接池管理提供了高效且实用的解决方案,是阿里巴巴数据库连接池中的佼佼者。
线上环境OOM频发,MyBatis有坑...
线上服务频繁遭遇 OutOfMemoryError(OOM)问题,对业务造成了严重影响,一天内服务重启多达五次,导致整个系统几乎瘫痪。通过Skywalking追踪,发现链路调用大部分呈现红色,亟待解决。作为排查者,我接手了这个任务。
首先,我分析了OOM的常见原因,主要包括堆内存和元空间不足。在我们的案例中,Mybatis的问题浮出水面。源码分析显示,Mybatis在拼接SQL时,通过集合存储SQL和参数,当SQL参数过多导致SQL过长时,集合会变得庞大,django物联网源码回收不及时就会引发内存溢出。
由于环境限制,无法直接通过jstack、jmap工具定位问题,这增加了排查的难度。但在网络搜索中,我找到了一篇与DruidDataSource和Mybatis相关的问题,这让我找到了问题的线索,即多线程并发操作可能导致内存占用过高,从而触发OOM。
进一步的源码分析揭示,DynamicContext类中的ContextMap(继承自HashMap)在存储SQL参数和占位符时,存在无法被GC回收的问题。当并发查询量增加时,这可能导致内存溢出。我通过线上复现情景,验证了这一理论,发现服务频繁进行Full GC,最终引发了OOM。
针对问题,我提出解决方案:优化SQL拼接,避免过长的SQL体积,强调代码和SQL编写的重要性。同时,为了应对未来可能的故障,我配置了docker中的OOM保留dump文件,以备不时之需。
SQL抽象语法树及改写场景应用
我们日常编写SQL语句,提交后获取结果集。例如,keras faster rcnn 源码"select * from t_user where user_id > ;",目标是从t_user表中筛选出user_id大于的所有记录。这条SQL经历了什么才能生成结果集呢?
不同数据库如MySQL、Oracle、TiDB、CK,乃至大数据计算引擎Hive、HBase、Spark,通过SQL引擎实现接受SQL并返回结果的功能。SQL引擎的核心执行逻辑大致为:词法分析、语法分析、查询优化、生成逻辑计划、物理计划,最后执行。
词法分析和语法分析引出了抽象语法树(AST)的概念。AST是对源代码语法结构的抽象表示,以树状形式展现,每个节点代表源码中的一种结构。SQL提交给SQL引擎后,首先经过词法分析,然后利用语法解析器生成AST。
以"select username,ismale from userInfo where age> and level>5 and 1=1"为例,抽象语法树简单理解为逻辑执行计划,经过查询优化器优化,得到逻辑计划树,实现谓词下推、剪枝等操作。逻辑计划进一步转换为物理计划,渔乐吧巅峰源码如数据扫描、聚合,最后执行。
ANTLR4工具广泛应用于解析SQL,通过构建G4文件描述语法,实现SQL拆解、封装和内容提取。在Java中,利用ANTLR4解析SQL,获取AST并提取表名。AST解析过程复杂,但通过简单字符串解析理解ANTLR4逻辑,有助于深入理解SQL解析。
在工业应用中,利用ANTLR4生成并解析AST,虽然提供了基础解析能力,但更深入处理通常需要进一步自定义操作。在Java生态中,Apache Sharding Sphere、Mycat等流行SQL解析工具实现了这一需求。
获取AST后,可以实现SQL的改写。改写SQL通常涉及添加占位符、正则匹配关键字,这些方法存在局限性和安全风险。基于AST的改写更安全,通过遍历树结构,调整目标节点,实现语法符合的改写。
利用Druid的SQL解析模块,通过SQLUtils类实现SQL改写,包括新增改写和查询改写。改写过程涉及识别SQL语法结构,如join、sub-query等。
在数据库数据隔离上,实现动态SQL改写,开发人员无需感知,通过在数据表上增加字段和环境标识,CRUD SQL自动增加标识字段(如flag='预发'、flag='生产'),操作数据仅限于当前应用环境。
源码详解系列(四) ------ DBCP2的使用和分析(包括JNDI和JTA支持)已停更
DBCP是一个用于创建和管理数据库连接的工具,通过连接池复用连接以减少资源消耗。它具备连接数控制、连接有效性检测、连接泄露控制和缓存语句等功能。Tomcat内置连接池、Spring团队推荐使用DBCP,阿里巴巴的druid也是基于DBCP开发的。 DBCP支持通过JNDI获取数据源,并且可以获取JTA或XA事务中的连接对象,用于两阶段提交(2PC)的事务处理。本篇文章将通过例子来解释如何使用DBCP。 以下是文章的详细内容:使用例子需求
本例将展示如何使用DBCP连接池获取连接对象,并进行基本的增删改查操作。工程环境
JDK:1.8.0_
maven:3.6.1
IDE:eclipse 4.
mysql-connector-java:8.0.
mysql:5.7.
DBCP:2.6.0
主要步骤
创建Maven项目,打包方式为war(war也可以是jar,这里选择war是为了测试JNDI功能)。
引入DBCP相关依赖。
在resources目录下创建dbcp.properties文件,配置数据库连接参数及连接池基本参数。
编写JDBCUtils类,实现初始化连接池、获取连接、管理事务和资源释放等功能。
创建测试类,实现基本的增删改查操作。
配置文件详解
dbcp.properties文件包含数据库连接参数和连接池基本参数,如数据库URL、用户名、密码、连接池大小等。其中,数据库URL后面添加了参数以避免乱码和时区问题。建议根据项目需求调整参数设置。基本连接属性
数据库URL
用户名
密码
连接池大小
缓存语句(在MySQL下建议关闭)
连接检查参数(建议开启testWhileIdle,避免性能影响)
事务相关参数(通常使用默认设置)
连接泄漏回收参数
其他参数(较少使用)
源码分析
DBCP主要涉及以下几个类:BasicDataSource:提供基本的数据库操作数据源。
BasicManagedDataSource:BasicDataSource的子类,用于创建支持XA事务或JTA事务的连接。
PoolingDataSource:BasicDataSource中实际调用的数据源,用于管理连接。
ManagedDataSource:PoolingDataSource的子类,用于支持XA事务或JTA事务的连接。
使用DBCP连接池创建连接时,首先创建BasicDataSource对象,初始化配置参数。然后从连接池中获取连接。连接获取过程涉及到数据源和连接池的创建,连接对象的包装和回收。通过JNDI获取数据源对象需求
使用JNDI获取DBCP数据源对象,以PerUserPoolDataSource和SharedPoolDataSource为例。为了在tomcat容器中测试,需要配置JNDI上下文。引入依赖
引入JNDI相关的依赖。
编写context.xml文件,配置JNDI上下文。
在web.xml中配置资源引用,将JNDI对象与web应用绑定。
测试结果
打包项目并部署到tomcat上运行,通过访问指定的jsp页面,验证JNDI获取数据源对象的正确性。使用DBCP测试两阶段提交
介绍如何使用DBCP实现JTA事务的两阶段提交(2PC)。使用DBCP的BasicManagedDataSource类支持事务处理。通过测试代码验证了2PC的正确性。 以上内容涵盖了DBCP的使用、配置、源码分析、JNDI集成以及两阶段提交的实现,为开发者提供了全面的参考。druid连接池中的连接数与预期不一致的一次分析
深入剖析druid连接池连接数与预期不一致的原因与解决方案 在排查生产环境cat监控显示部分应用SQL执行耗时长的问题时,我们发现部分应用节点在运行一段时间后,数据库连接池中的实际连接数与应用中配置的参数不一致。主要表现为连接池中的可用连接总数远小于应用配置的初始连接数与最小空闲连接数。这导致了新建连接耗时增加,线程阻塞状态出现,影响性能,不利于应对外部瞬间的并发压力。条码组项目使用的是druid框架,但使用版本较为杂乱,包括1.0.、1.1.、1.1.。基于此,本文旨在分析druid如何对空闲连接进行回收,以及提供相应的配置建议与jar包版本建议。 详细分析过程 通过对源码的反编译分析,我们发现druid框架在应用启动后启动了多个处理线程,其中Druid-ConnectionPool-Destroy-*线程专门用于回收空闲连接。不同版本的使用配置及处理逻辑存在差异。以1.0.与1.1.版本为例进行对比分析。 在1.0.版本中,回收线程按照配置的时间间隔timeBetweenEvictionRunsMillis进行轮询。回收空闲连接的判断逻辑包含如下步骤:遍历连接池中的所有连接。
获取超过最小空闲连接数的数量checkCount(连接池总数减去最小空闲连接数)。
获取当前连接的空闲时间idleMillis(当前时间减去上一次连接使用的时间)。
判断idleMillis是否小于minEvictableldleTimeMillis(默认分钟),小于则退出循环,否则继续后续处理。
如果checkCount大于0,将超过最小空闲连接数的连接放入待销毁集合(进行回收)。
如果idleMillis大于maxEvictableIdleTimeMillis,即使连接池连接数小于最小空闲连接数,当前连接也会被放入待销毁集合。
在1.1.版本中,新增了判断逻辑:idleMillis需要同时满足小于minEvictableldleTimeMillis(默认分钟)与keepAliveBetweenTimeMillis(默认2分钟)时,才会退出循环。
配置keepalive为true时,idleMillis大于keepAliveBetweenTimeMillis,当前连接会被维护到保活集合中,以确保连接可用,避免意外回收。
分析总结 结合项目现有的配置和依赖的jar包版本,连接池中的连接数不总是与初始连接数或最小空闲连接数保持一致。在使用1.0.、1.1.版本的应用中,如果SQL请求不是非常稀少,则能维持连接池中的连接数与配置一致。然而,使用1.1.版本、处理SQL请求不是非常频繁的应用,空闲连接更容易被回收。关键原因在于缺少关键配置(keepalive未配置),导致默认参数下更容易回收连接。 版本建议 建议统一升级使用1.1.版本,并主动排除项目中依赖的其他版本,以防版本冲突。对于使用1.1.或更高版本的应用,确保添加keepalive=true配置。 Spring Boot项目配置示例:spring.datasource.druid.keep-alive=true