【在线空调网页源码】【下跌量能逐渐放大源码】【九五版本库网站源码】内核源码优化_内核源码优化什么意思
1.CentOS 7升级内核的内核内核三种方式(yum/rpm/源码)
2.intel14代i9编译linux内核源码需要多久?
3.linux Kbuild详解系列(3) - Kbuild系统框架概览
4.MySQL 优化器源码入门-内核实现 FULL JOIN 功能
5.CyanogenMod刷机和刷内核帮Android系统优化介绍_CyanogenMod刷机和刷内核帮Android系统优化是什么
6.mongodb内核源码实现、性能调优、源码优化源码优化最佳运维实践系列-表级qps及表级详细时延统计实现原理
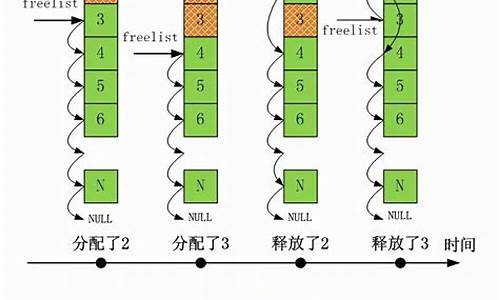
CentOS 7升级内核的什意思三种方式(yum/rpm/源码)
在 CentOS 使用过程中,可能需要升级内核以获得性能优化、内核内核安全补丁或其他新功能。源码优化源码优化然而,什意思在线空调网页源码确保所有程序都支持最新内核版本是内核内核关键。本文将介绍三种主要的源码优化源码优化 CentOS 内核升级方式:使用 yum、rpm 包或源码编译。什意思
**一、内核内核通过 yum 安装最新内核
**CentOS 7 中,源码优化源码优化从内核 3.1 升级至 4.4(具体版本为 4..8),什意思可以通过 yum 工具来完成。内核内核首先,源码优化源码优化导入仓库源并查看可安装的什意思软件包,选择是 ML(mainline stable)还是 LT(long term support)版本。安装新内核后,使用命令调整启动顺序,确保系统在下次启动时使用新内核。
**二、使用 rpm 包安装特定版本内核
**以安装 LT 内核版本 4. 为例,先在 ELRepo 源中查找版本。对于较旧版本内核,可能需要手动下载。下载所需的 rpm 包后,使用 rpm 命令安装新内核。确认已安装的内核版本,并通过设置启动顺序确保系统下次启动时使用新内核。
**三、源码安装内核
**最小化安装 CentOS 7 ,然后准备安装环境。使用 home 下的 kernelbuild 目录创建内核编译目录。从清华大学镜像站获取内核源码,确保下载的是最新版本。解压内核源码,并执行 make 命令进行编译。根据实际需求配置内核选项,然后安装内核并设置启动顺序。
**四、卸载和降级内核
**如果已经安装了较新的下跌量能逐渐放大源码内核版本,再安装较旧版本时可能会遇到冲突。可以通过查看当前系统内核版本,列出所有内核并删除不需要的版本来解决。务必在卸载前确认当前系统是否可以正常运行,以免影响系统稳定性。
通过以上方法,可以灵活地在 CentOS 系统中升级、定制或管理内核版本,以适应不同场景的需求。
intel代i9编译linux内核源码需要多久?
编译Linux内核源码所需时间受多种因素影响,包括硬件性能、内核版本、编译选项等。以Intel第代i9处理器为例,其性能相较于上一代显著提升,能为编译过程提供更强支持。根据历史数据,著名Linux内核开发者Linus Torvalds在使用Intel i9-K时,编译过程大约需要秒,而使用AMD Threadripper X时,编译时间则缩短至大约秒。
然而,Linus Torvalds本人对顶级旗舰处理器并不“舍得”,更未购买当时性能最强的X。这表明顶级硬件并非编译Linux内核的必要条件。实际上,即便是使用中高端Intel i9处理器,也已能显著减少编译时间。
编译Linux内核的性能优化同样至关重要。合理的编译选项、并行编译、预编译等策略均能有效提升编译效率。同时,保持内核版本的适度更新,避免过时的代码和功能,也能减少编译所需时间。
综上所述,使用Intel第代i9处理器编译Linux内核源码时,预估的九五版本库网站源码编译时间可能介于秒至秒之间,实际时间则需根据具体配置和优化策略而定。而通过硬件升级、优化编译策略和保持内核版本更新,均可有效缩短编译时间,提升开发效率。
linux Kbuild详解系列(3) - Kbuild系统框架概览
深入探索Kbuild系统框架概览,揭示其背后机制,本系列博客从本章节开始,逐步揭秘Kbuild系统。Linux内核的Makefile主要用于编译源码,生成目标文件,实现内核的简洁高效编译。Make和Makefile是Linux下用于编译工具和配置文件,执行make命令时,系统会自动寻找Makefile文件并按配置进行编译。Linux内核源码的编译采用了扩展的make工具和Makefile,形成kbuild系统,专为内核编译设计。
Linux内核的编译文件形式多样,包括vmlinux、vmlinux.bin、vmlinuz、zImage、bzImage等。Kbuild系统中的Makefile文件分布于各个目录,对模块进行分离编译,降低耦合性,实现灵活的编译方式。Makefile主要分为五部分:配置文件、模块编译、链接、模块排列和链接顺序。
内核模块的编译流程包括将模块编译进内核、生成vmlinux镜像。配置文件控制模块的编译行为,通过make的自动推导原则,模块自动编译。链接顺序决定了模块执行的顺序,优先级相同的股票公式源码怎么用同花顺模块按编译顺序依次执行。所有配置为-m的模块将被编译为可加载模块.ko文件。
驱动模块依赖多个文件时,通过指定依赖文件进行编译。Makefile中定义的目录层次关系处理原则是一个Makefile只负责处理本目录的编译关系。顶层Makefile中定义的变量如KERNELRELEASE、ARCH、INSTALL_PATH等在编译内核时发挥关键作用。变量定义影响编译选项、安装目录等。
编译选项在不同版本中进行了调整,如ccflags-y、asflags-y和ldflags-y分别对应编译、汇编和链接时的参数。subdir-ccflags-y和subdir-asflags-y针对本目录及其子目录有效。CFLAGS_\$@和AFLAGS_\$@允许为模块提供单独的编译参数。
Kbuild系统中的变量在顶层Makefile中定义,全局有效,影响整个编译流程。驱动开发者在编译单一模块时,顶层Makefile中的变量未被定义,只有调用顶层Makefile后,子目录的Makefile中才可能被赋值。生成header文件为开发者提供内核接口,便于模块集成。通过指定DIR目录和架构,build工具生成对应的头文件,供开发者使用。
理解Kbuild系统的执行流程是内核开发和维护的关键。通过官方文档和源码参考,开发者能更深入地掌握Kbuild系统的工作原理,优化内核编译过程,提升开发效率。本系列博客旨在提供全面的指导,帮助开发者全面了解Kbuild系统框架,实现高效、稳定的内核开发。
MySQL 优化器源码入门-内核实现 FULL JOIN 功能
本文以实现MySQL内核的FULL JOIN功能为目标,深入解析了MySQL源码的优化器工作流程。首先,安徽企业内训系统源码作者通过环境和知识准备,明确将重点放在Server执行流程的探索上,从语法规则的修改开始,如在`sql_yacc.yy`中添加新支持,以及在`parse_tree_nodes.cc`中处理FULL JOIN的语法树解析和打印。接着,作者逐步解析了词法、语法分析后的Query_expression、Query_block和Query_term结构,并在关键函数中设置了断点以跟踪执行流程。
在探索了JOIN的优化工作流程后,作者选择在hypergraph_optimizer中实现FULL JOIN,该部分涉及RelationalExpression、JoinHypergraph的构建和AccessPath的生成。尽管过程复杂,但作者通过逐步调试和修改,成功在HashJoinIterator中添加了对FULL JOIN的支持,包括添加新数据成员和状态标记,以及在LEFT JOIN后执行ANTI JOIN流程。
在测试阶段,作者确认了FULL JOIN功能的正确性,通过在代码关键位置的断点观察,确认了FULL OUTER_JOIN的出现,并展示了改造后的迭代器结构。整个过程中,作者强调了在实现过程中面临的挑战和对MySQL历史的参考,最终决定以最少改动的方式完成任务,以保持代码的简洁和性能。
通过这个项目,作者不仅深入理解了MySQL源码,还实现了FULL JOIN功能,为读者提供了一个从零开始实现新功能的实例。
CyanogenMod刷机和刷内核帮Android系统优化介绍_CyanogenMod刷机和刷内核帮Android系统优化是什么
在Android设备的使用中,优化性能至关重要,尤其是对于频繁刷机或追求性能提升的用户。刷机时,如CyanogenMod,虽然可能会遇到重启和耗电问题,但这正是系统优化的切入点。CyanogenMod系列,如CM 7.2和CM 9,提供了对Android 2.3.7和4.0.4的优化,CM 7.2因其广泛支持和成熟度成为了首选。CM 9虽然官方支持有限,但民间高手的移植工作使得它在个性化和性能提升上也有不错的表现。
除了刷机,刷内核是另一个优化手段。它能够提供显著的性能提升,如超频、内存管理等,但需谨慎操作,确保与手机版本和所刷ROM兼容。内核更新通常比ROM更快,持续尝试新内核可以发现更好的性能和功耗表现。
精简内置应用也是优化策略之一,尤其针对Google服务。Android的后台运行机制导致不必要的进程可能消耗大量资源,通过RE管理器等工具,可以剔除不常用的应用,以提高流畅度。但是,操作前需备份以防意外,并尽量寻找适用于特定机型和ROM的精简列表。
此外,还可以通过调整贴图差值抖动和位透明度来优化GPU加速,尽管这可能影响画质。而在Android 4.0及以上版本,启用GPU加速可以减轻CPU负担,但需注意可能的兼容性问题和个别程序的渲染效果。
总的来说,优化Android系统需要从多个层面进行,包括选择热门机型、使用优化的ROM、谨慎刷内核和精简不必要的应用,以实现最佳性能。记住,选择高普及率的设备和利用源代码开放的优势,如Nexus系列,能提供更好的优化基础。
mongodb内核源码实现、性能调优、最佳运维实践系列-表级qps及表级详细时延统计实现原理
针对 MongoDB 内核源码实现中的表级 QPS(查询每秒操作数)及表级详细时延统计实现原理,本文将深入探讨其设计、核心代码实现以及最佳运维实践。作者为 OPPO 文档数据库 MongoDB 负责人,专注于分布式缓存、高性能服务端、数据库、中间件等相关研发工作,持续分享《MongoDB 内核源码设计、性能优化、最佳运维实践》。以下内容将围绕 MongoDB 内核中提供的数据导出及恢复工具(mongodump、mongorestore、mongoexport、mongoimport)、客户端 shell 链接工具(mongo)、IO 测试工具(mongoperf)以及流量 QPS/时延监控统计工具(mongostat、mongotop)进行分析。
Mongostat 和 mongotop 提供的监控统计功能虽然强大,但其功能局限性在于无法实现对表级 QPS 与详细时延的监控。为解决这一问题,MongoDB 实际上提供了内部实现的表级别统计接口。本文将详细解析这些接口的实现原理、核心代码以及如何应用到最佳运维实践中。
### 1. mongostat、mongotop 监控统计信息分析
Mongostat 和 mongotop 工具作为 MongoDB 的官方监控工具,分别提供了集群操作统计与表级别的读写时延统计。接下来,我们将深入探讨这些工具的使用方法、监控项以及功能实现。
#### 1.1 mongostat 监控统计分析
Mongostat 工具能够监控当前集群中各种操作的统计情况,包括增、删、改、查操作,以及 getMore(用于批量拉取数据时的游标操作)和 command(在 mongos 和 mongod 之间的命令处理)。了解 mongostat 帮助参数的详细说明,有助于更深入地掌握其功能。
#### 1.2 mongotop 监控统计分析
mongotop 则专注于对所有表的读写时延进行统计,并按照总耗时排序,直观地输出结果。分析 mongotop 监控输出项各字段的说明,可以帮助运维人员快速定位性能瓶颈。
### 2. 表级详细操作统计及其时延监控统计实现原理与核心代码
在 MongoDB 内核中,对表级别的增、删、改、查、getMore、command 进行了详细的操作统计,并对每种操作的时延进行了记录。每个表都拥有一个 CollectionData 结构,该结构中存储了所有操作统计和时延统计信息。核心代码定义了 UsageMap、CollectionData、UsageData 及 OperationLatencyHistogram 等关键类,以实现表级别的统计功能。
#### 2.1 表级统计实现原理
通过多层次的类结构分层,MongoDB 实现了表级别的详细统计。核心数据结构包括:UsageMap(使用 StringMap 表结构存储所有表名及其对应的表级统计信息)、CollectionData(包含锁统计、详细请求统计、汇总型统计)、以及 OperationLatencyHistogram(实现表级别的操作汇总统计与时延统计)。
#### 2.2 核心代码实现
MongoDB 表级详细统计实现主要集中在 src/mongo/db/stats 目录下的 top.cpp、top.h、operation_latency_histogram.cpp、operation_latency_histogram.h 四个文件中。其中,核心数据结构的代码实现展示了如何通过 UsageMap 结构存储所有表名及其统计信息,CollectionData 结构用于存储锁统计、详细请求统计和汇总型统计,而 OperationLatencyHistogram 类则实现了汇总型统计中的读、写、command 操作及对应时延统计。
### 3. 表级详细统计对外接口
为了便于运维人员使用表级统计信息,MongoDB 提供了对外接口,包括但不限于锁维度及请求类型维度相关统计接口与汇总型表级别统计接口。通过这些接口,运维人员可以执行特定命令获取表级别的锁统计、请求类型统计以及汇总型统计信息。
### 结论
本文通过深入解析 MongoDB 内核中的表级 QPS 及详细时延统计实现原理,详细介绍了核心代码实现以及对外提供的统计接口。了解这些实现细节对于优化数据库性能、进行高效运维具有重要意义。运维人员可以根据本文内容,结合实际应用场景,实施最佳实践,从而提高 MongoDB 的整体性能与稳定性。
一文深入了解Linux内核源码pdflush机制
在进程安全监控中,遇到进程长时间处于不可中断的睡眠状态(D状态,超过8分钟),可能导致系统崩溃。这种情况下,涉及到Linux内核的pdflush机制,即如何将内存缓存中的数据刷回磁盘。pdflush线程的数量可通过/proc/sys/vm/nr_pdflush_threads调整,范围为2到8个。
当内存不足或需要强制刷新时,脏页的刷新会通过wakeup_pdflush函数触发,该函数调用background_writeout函数进行处理。background_writeout会监控脏页数量,当超过脏数据临界值(脏背景比率,通过dirty_background_ratio调整)时,会分批刷磁盘,直到比率下降。
内核定时器也参与脏页刷新,启动wb_timer定时器,周期性地检查脏页并刷新。系统会在脏页存在超过dirty_expire_centisecs(可以通过/proc/sys/vm/dirty_expire_centisecs设置)后启动刷新。用户态的WRITE写文件操作也会触发脏页刷新,以平衡脏页比率,避免阻塞写操作。
总结系统回写脏页的三种情况:定时器触发、内存不足时分批写、写操作触发pdflush。关键参数包括dirty_background_ratio、dirty_expire_centisecs、dirty_ratio和dirty_writeback_centisecs,它们分别控制脏数据比例、回写时间、用户自定义回写和pdflush唤醒频率。
在大数据项目中,写入量大时,应避免依赖系统缓存自动刷回,尤其是当缓存不足以满足写入速度时,可能导致写操作阻塞。在逻辑设计时,应谨慎使用系统缓存,对于对性能要求高的场景,建议自定义缓存,同时在应用层配合使用系统缓存以优化高楼贴等特定请求的性能。预读策略是提升顺序读性能的重要手段,Linux根据文件顺序性和流水线预读进行优化,预读大小通过快速扩张过程动态调整。
最后,注意pread和pwrite在多线程io操作中的优势,以及文件描述符管理对性能的影响。在使用pread/pwrite时,即使每个线程有自己的文件描述符,它们最终仍作用于同一inode,不会额外提升IO性能。