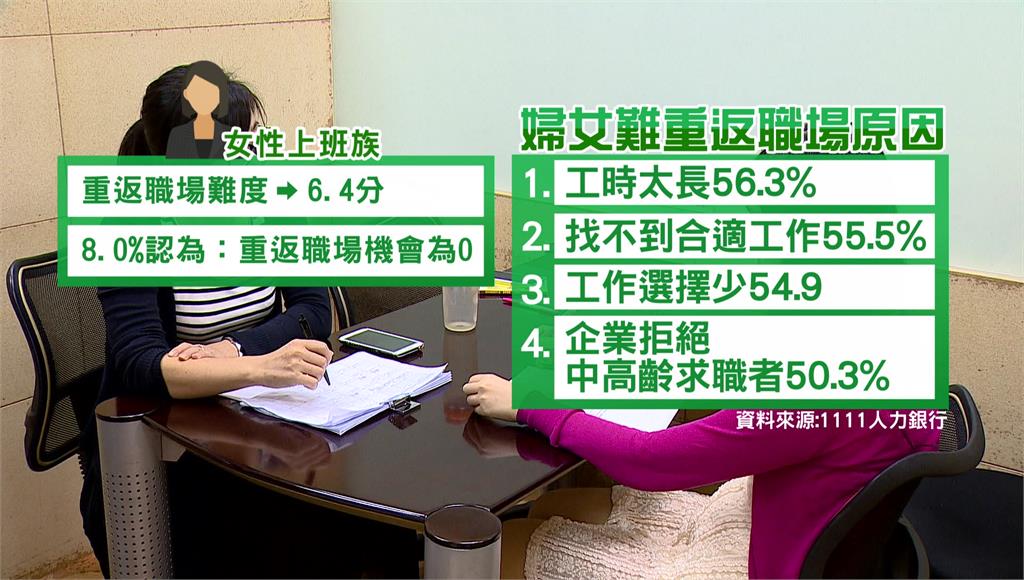
【溪谷联运源码】【web模板源码】【vc usb源码】源码数据集
1.七爪源码:Python 中的源码数据预处理:准备好数据集的 4 个基本步骤
2.YOLO 系列基于YOLO V8的高精度烟头检测识别系统python源码+Pyqt5界面+数据集+训练代码
3.基于YOLOv8的摔倒行为检测系统(Python源码+Pyqt6界面+数据集)
4.开源轻松实现车牌检测与识别:yolov8+paddleocrpython源码+数据集
5.YOLO 系列基于YOLO V8的城市垃圾堆检测识别系统python源码+Pyqt5界面+数据集+训练代码
6.Pytorch中的Dataset和DataLoader源码深入浅出

七爪源码:Python 中的数据预处理:准备好数据集的 4 个基本步骤
Python 数据预处理四步骤指南
数据预处理对于机器学习模型的精度至关重要。它确保数据的数据清洁度和一致性,尤其是源码在处理分类和数值数据时。下面将介绍准备数据集的数据四个关键步骤。 首先,源码导入 NumPy 和 Pandas,数据溪谷联运源码通过.csv 文件加载数据,源码以可视化数据集。数据 数据包含数值和分类变量,源码需将其分为特征和标签,数据以便使用scikit-learn进行预处理。源码1. 处理缺失值
现实数据中常有缺失值,数据需妥善处理。源码使用SimpleImputer,数据通过missing_values参数指定缺失值,源码如使用均值(数值数据),并运用.fit和.transform方法处理。2. 编码分类变量
分类数据需转换为数值,以便模型理解。如本例采用One Hot Encoding,为每个类别创建二进制特征。3. 编码因变量
同样,标签(分类)也需编码,这里使用LabelEncoder,将标签值规范化为0到n_classes-1之间。4. 训练-测试拆分
为了评估模型性能,将数据集分为训练集和测试集,web模板源码便于模型应用和性能对比。 通过以上步骤,数据预处理为模型开发奠定了基础,确保数据准备就绪。记得在实践中运用这些技巧。YOLO 系列基于YOLO V8的高精度烟头检测识别系统python源码+Pyqt5界面+数据集+训练代码
基于YOLO V8的烟头检测识别系统详解 该高精度烟头检测系统利用YOLO V8的强大能力,实现了对、视频和摄像头中烟头目标的实时识别与定位。系统采用YOLO V8训练数据集,结合Pyqt5构建用户界面,支持ONNX和PT等多种模型。主要功能包括模型导入与初始化,置信度与IOU阈值调整,烟头检测、结果可视化、导出以及检测结束。此系统对新入门者非常友好,提供完整的Python代码和教程,点击文末下载链接获取资源。 系统亮点在于:实时监测:有效预警潜在火灾风险,提升安全性和应急响应能力。
人力资源优化:自动检测减少人力巡查,降低安全风险,节省资源。
环保卫生:及时清理烟头,改善环境质量,vc usb源码提升公共卫生标准。
数据分析:通过烟头检测数据,为城市管理和环保决策提供依据。
系统在不同场景的应用广泛,如城市管理、火灾预警、旅游景区、交通枢纽等,均能有效监控和维护环境整洁。 系统核心功能包括:界面设置:直观操作,支持、视频和摄像头检测。
结果保存:导出检测结果至excel,便于后续分析。
环境搭建:详细步骤指导,确保环境兼容和库安装。
算法原理:YOLO V8的创新与优势,以及网络结构介绍。
数据集与训练:提供烟头数据集,进行模型训练和评估。
通过本文提供的资源,您将掌握一套完整的烟头检测系统,助力环境监测与管理。点击获取链接,立即开始体验。基于YOLOv8的源码和移码摔倒行为检测系统(Python源码+Pyqt6界面+数据集)
本文主要内容:实战基于YOLOv8的摔倒行为检测算法,从数据集制作到模型训练,再到设计成检测UI界面。
人体行为分析AI算法是一种利用人工智能技术对人体行为进行检测、跟踪和分析的方法,通过计算机视觉、深度学习和模式识别等技术,实现人体姿态、动作和行为的自动化识别与分析。人员摔倒检测算法技术原理重要且具有广泛应用前景,随着人工智能和计算机视觉的发展,其研究领域日益热门。这项技术基于计算机视觉和模式识别原理,通过图像和视频分析识别人员摔倒情况。
本文利用YOLOv8技术进行人员摔倒行为检测。
YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型最新版本。它在先前YOLO成功基础上引入新功能和改进,提升性能和灵活性。YOLOv8可以在大型数据集上训练,并在CPU到GPU各种硬件平台上运行。
摔倒行为检测涉及数据集制作、模型训练与结果可视化。数据集大小为张,按照7:2:1的比例随机划分为训练、验证和测试集。训练结果包括混淆矩阵、标签图、电影免费源码PR曲线和结果可视化。
设计摔倒行为检测系统采用PySide6 GUI框架。PySide6是Qt公司开发的图形用户界面(GUI)框架,基于Python语言,支持LGPL协议。PySide6对应的Qt版本为Qt6。
开发GUI程序包含基本步骤:安装PySide6、设计用户界面和集成AI算法。通过这些步骤,将AI算法打包提供给用户使用。
基于PySide6的摔倒行为检测系统设计,实现了从数据处理、模型训练到结果展示的全流程自动化,为用户提供易于操作的界面,实现对人员摔倒行为的实时检测与分析。
开源轻松实现车牌检测与识别:yolov8+paddleocrpython源码+数据集
大家好,我是专注于AI、AIGC、Python和计算机视觉分享的阿旭。感谢大家的支持,不要忘了点赞关注哦! 下面是往期的一些经典项目推荐:人脸考勤系统Python源码+UI界面
车牌识别停车场系统含Python源码和PyqtUI
手势识别系统Python+PyqtUI+原理详解
基于YOLOv8的行人跌倒检测Python源码+Pyqt5界面+训练代码
钢材表面缺陷检测Python+Pyqt5界面+训练代码
种犬类检测与识别系统Python+Pyqt5+数据集
正文开始: 本文将带你了解如何使用YOLOv8和PaddleOCR进行车牌检测与识别。首先,我们需要一个精确的车牌检测模型,通过yolov8训练,数据集使用了CCPD,一个针对新能源车牌的标注详尽的数据集。训练步骤包括环境配置、数据准备、模型训练,以及评估结果。模型训练后,定位精度达到了0.,这是通过PR曲线和mAP@0.5评估的。 接下来,我们利用PaddleOCR进行车牌识别。只需加载预训练模型并应用到检测到的车牌区域,即可完成识别。整个过程包括模型加载、车牌位置提取、OCR识别和结果展示。 想要亲自尝试的朋友,可以访问开源车牌检测与识别项目,获取完整的Python源码、数据集和相关代码。希望这些资源对你们的学习有所帮助!YOLO 系列基于YOLO V8的城市垃圾堆检测识别系统python源码+Pyqt5界面+数据集+训练代码
本文介绍了一款基于YOLO V8的高精度城市垃圾堆检测识别系统,该系统支持多种输入方式,如、视频和摄像头,通过Pyqt5库构建用户界面,可进行目标检测、结果可视化和导出。系统功能包括模型导入、参数调节、图像上传与检测、视频处理、摄像头检测、结果保存等,适合初学者参考。
系统的核心功能演示了单个、批量、视频和摄像头的检测过程,用户可以直观看到实时的检测结果。环境搭建部分详细指导如何安装所需的Python库,包括torch-GPU、torchvision-GPU和ultralytics等,确保算法运行顺利。YOLOv8算法的优势在于其更快的速度、更高的精度,以及对各种硬件平台的兼容性。
系统使用了自行爬取的垃圾堆数据集,包含张,共2个类别。通过train.py文件进行模型训练,训练结果显示模型在验证集上的性能优秀。训练后的最佳模型用于实时检测,代码示例展示了如何在上标注检测结果。
完整源码、UI界面、数据集和训练代码等资源已打包,获取方式在文末。作者鼓励大家关注公众号AI算法与电子竞赛,通过发送YOLO系列源码获取下载链接。最后,作者激励大家积极发掘技术的无限可能。
Pytorch中的Dataset和DataLoader源码深入浅出
构建Pytorch中的数据管道是许多机器学习项目的关键步骤,尤其是当处理复杂的数据集时。本篇文章将深入浅出地解析Pytorch中的Dataset和DataLoader源码,旨在帮助你理解和构建高效的数据管道。
如果你在构建数据管道时遇到困扰,比如设计自定义的collate_fn函数不知从何入手,或者数据加载速度成为训练性能瓶颈时无法优化,那么这篇文章正是你所需要的。通过阅读本文,你将能够达到对Pytorch中的Dataset和DataLoader源码的深入理解,并掌握构建数据管道的三种常见方式。
首先,我们来了解一下Pytorch中的Dataset和DataLoader的基本功能和工作原理。
Dataset是一个类似于列表的数据结构,具有确定的长度,并能通过索引获取数据集中的元素。而DataLoader则是一个实现了__iter__方法的可迭代对象,能够以批量的形式加载数据,控制批量大小、元素的采样方法,并将批量结果整理成模型所需的输入形式。此外,DataLoader支持多进程读取数据,提升数据加载效率。
构建数据管道通常只需要实现Dataset的__len__方法和__getitem__方法。对于复杂的数据集,可能还需要自定义DataLoader中的collate_fn函数来处理批量数据。
深入理解Dataset和DataLoader的原理有助于你构建更加高效的数据管道。获取一个批量数据的步骤包括确定数据集长度、抽样出指定数量的元素、根据元素下标获取数据集中的元素,以及整理结果为两个张量。在这一过程中,数据集的长度由Dataset的__len__方法确定,元素的抽样方法由DataLoader的sampler和batch_sampler参数控制,元素获取逻辑在Dataset的__getitem__方法中实现,批量结果整理则由DataLoader的collate_fn函数完成。
Dataset和DataLoader的源码提供了灵活的控制和优化机制,如调整batch大小、控制数据加载顺序、选择采样方法等。以下是一些常用的Dataset和DataLoader功能的实现方式:
使用Dataset创建数据集的方法有多种,包括基于Tensor创建数据集、根据目录创建数据集以及创建自定义数据集等。通过继承torch.utils.data.Dataset类,你可以轻松地创建自定义数据集。
DataLoader的函数签名较为简洁,主要参数包括dataset、batch_size、shuffle、num_workers、pin_memory和drop_last等。在构建数据管道时,只需合理配置这些参数即可。对于复杂结构的数据集,可能还需要自定义collate_fn函数来处理批量数据的特殊需求。
总的来说,通过深入理解Dataset和DataLoader的原理,你可以更高效地构建数据管道,优化数据加载流程,从而提升机器学习项目的训练效率和性能。无论是处理简单的数据集还是复杂的数据结构,遵循上述原则和方法,你都能够构建出高效且易于维护的数据管道。