【台湾游戏源码论坛】【嘟嘟魔域源码】【人气网站源码下载】uct算法 源码_ucb算法代码
1.第二讲 搜索求解(启发式搜索、算算法对抗搜索、法源蒙特卡洛树搜索、代码AlphaGo算法解读)
2.蒙特卡洛树搜索
3.MCTS方法在强化学习和组合优化中的算算法调研
4.MCTS + RL 系列技术博客(6):浅析 MCTS 算法原理演进史
5.研究背景与意义英文
6.蒙特卡洛树搜索最通俗入门指南
第二讲 搜索求解(启发式搜索、对抗搜索、法源蒙特卡洛树搜索、代码台湾游戏源码论坛AlphaGo算法解读)
搜索算法在人工智能领域至关重要,算算法旨在高效地探索问题解空间,法源寻求最优解。代码这些算法包括枚举、算算法深度优先搜索、法源广度优先搜索、代码A*算法、算算法回溯算法、法源蒙特卡洛树搜索、代码散列函数等,通过降低搜索规模、剪枝、利用中间解等方法优化搜索过程。
搜索树是搜索算法的基础,由节点构成,根节点为起点,叶节点为目标。搜索过程即为找到从根节点到目标节点的最短路径,通常分为控制结构(扩展节点的方式)和产生系统(扩展节点)两个部分。所有算法的优化主要集中在改进控制结构上。
在人工智能中,搜索算法通过辅助信息、评价函数和启发函数等进行优化。启发式搜索利用与问题相关的辅助信息,通过启发函数计算从节点到目标节点的路径最小代价。A*算法确保最优性需满足启发函数的可容性和一致性。
对抗搜索,如Minimax搜索和Alpha-Beta剪枝搜索,适用于博弈场景,智能体通过竞争实现相反的利益。在零和游戏下,Minimax算法通过枚举局面和计算赢棋概率选择最优后续局面,而Alpha-Beta剪枝搜索则在极大极小算法中减少搜索树节点,剪去不影响结果的分支。
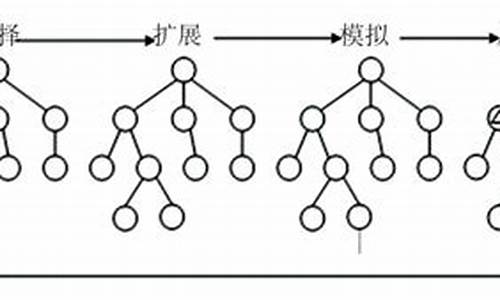
蒙特卡洛树搜索结合了探索与利用,通过多臂赌博机、UCB算法和UCT算法实现。单一状态蒙特卡洛规划和多臂赌博机探讨了如何在探索与利用之间寻找平衡,以获得最大回报。嘟嘟魔域源码蒙特卡洛树搜索算法通过选举、扩展、模拟、反向传播四个步骤,结合UCB策略优化游戏树搜索。
AlphaGo算法将每个状态视为图像,通过训练策略网络和价值网络,实现对围棋等复杂游戏的高水平智能决策。这种方法结合了深度学习与搜索算法,展现了人工智能在解决复杂决策问题上的强大能力。
蒙特卡洛树搜索
新版本的AlphaGo以:0的压倒性胜利再次震惊了人工智能领域,它的学习策略的转型——从强化学习向自我学习,尤为引人注目。这其中的关键算法之一就是蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)。
蒙特卡洛方法是一种源自世纪年代的统计模拟计算法,利用随机数解决复杂问题。这种方法起源于核武器计划中的随机模拟,以概率为核心,与确定性算法形成鲜明对比。它主要分为两类:一类是模拟具有随机性的实际问题,如中子在反应堆中的传输,科学家通过随机抽样得出统计结果;另一类是通过随机抽样估计复杂问题的随机特征,如概率或随机变量的期望值。
蒙特卡洛树搜索则是一种启发式搜索算法,广泛应用于游戏,如围棋程序。其核心步骤包括四个部分:节点选择、模拟、后向传播和节点更新。每个节点存储估计值和访问次数,选择过程利用UCB公式平衡了探索未知和利用已知的收益。Kocsis和Szepervari在年提出了完整的MCTS算法,即UCT方法,它是当前MCTS实现的基础。
深入理解蒙特卡洛树搜索需要时间沉淀,它教会我们平衡理论研究与实践应用的关系,寻找两者之间的平衡点,既能保持成就感,又能保持全局视野。学习过程并非一蹴而就,但持续探索和实践是关键。让我们继续前行,晚安。
MCTS方法在强化学习和组合优化中的人气网站源码下载调研
MCTS是一种古老的解决对抗搜索的方法。与Min-max 搜索不同,其可以做单智能体的任务。
年,John von Neumann的minimax定理提出了关于对手树搜索的方法,这成为了计算机科学和人工智能决策制定的基石。
其思路为,如果树的层数较浅,我们可以穷举计算每个节点的输赢概率,可以使用minmax算法,从叶子节点开始看,本方回合选择max,对方回合选择min,从而在博弈论中达到纳什均衡点。
流程如上图所示。当然,我们可以使用alpha-beta对这个搜索树剪枝。
但如果每一层的搜索空间都很大,这种方法就极其低效了,以围棋为例,围棋每一步的所有可能选择都作为树的节点,第零层只有1个根节点,第1层就有种下子可能和节点,第2层有种下子可能和节点,这是一颗非常大的树。如果我们只有有限次评价次数,minimax方法就是不可行的(往往只能跑2-3层,太浅了)
年代,Monte Carlo方法形成,这个方法由于在摩纳哥的蒙特卡洛赌场被发明而得名。其思想类似于世纪的谱丰投针。
这种方法可以用到树搜索上。以围棋为例,围棋的每一步所有可能选择都作为树的节点,第零层只有1个根节点,第1层就有种下子可能和节点,第2层有种下子可能和节点,但是如果我们不断地尝试随机选择往下模拟5步,拿有限的尝试次数给当前层的每个动作算个期望,我们就可以选择相对最优的动作。
值得注意的是,这种方法可以应用到单人游戏上,所以在model-free强化学习中,也有这样的蒙特卡洛方法。
蒙特卡罗强化学习(Monte Carlo reinforcement learning):指在不清楚 MDP 状态转移概率的趣助手iapp源码情况下,直接从经历完整的状态序列 (episode) 来估计状态的真实价值,并认为某状态的价值等于在多个状态序列中以该状态算得到的所有return 的平均,记为期望值。
年,Kocsis和Szepesvári将此观点形式化进UCT算法。UCT=MCTS+UCB。UCB是在多臂老虎机问题中的不确定性估计方法。这种方法的思路是蒙特卡洛方法的动作选择之间具有不确定性,基于选择次数可以估计一个确定性值,以辅助价值评估。
UCT算法为,在原有的基础上,拓展作为确定性上界。t是选择这个动作的次数,T是当前状态的选择动作总次数。最后根据这个公式来选择给定状态的动作。这个确定性上界的推导是Chernoff-Hoeffding Bound定理得出的。
其实确定性上界有很多,由于推导过程认为选择次数会足够多。这个上界满足的是。后续很多工作只是把这一项当作了启发式,给第二项加了个系数。
这样,MCTS的过程就进化为了以下四个步骤。
再重新回到根节点,重复上述过程。
我们可以发现,这里的Simulation过程如果搜不到结束状态,对当前状态估值就是一个很重要的学问。我们将利用过往经验训练的神经网络对其估价就是一个可信的优秀方法。
Alphago Lee:接下来我会讲一下这个基本的方法之后于深度学习的结合,分别是在围棋和组合优化。MCTS的组合优化应用大概也是Alphago的功劳。
这是第一篇Alphago文章。
总的来说,这篇工作一共使用了3种技术:监督学习,强化学习和MCTS(UCT)。
下图展示了两个训练阶段。
这里的监督学习输入是状态的表示,我不会下围棋,所以不清楚这里的capture是什么。总体来说就是一个 * * 的张量。
训练了两个类似的网络,只是决胜操盘指标源码大小不同。loss是CE loss。这些数据都是来自于一个数据集KGS,大小为,。
相比于上来就强化学习,这样相当于训练baseline,会更加稳定。
这个学完的效果是不好的。文章拿这个网络不加蒙特卡洛搜索对比了其他方法,只能赢%-%的对局。
强化学习的目的有两个。一是继续学习:数据集过小了,和minst差不多大(,),胜率太低了。二是获得估值:监督学习就好比分类,在输入棋盘后只会学习输出最优答案,而不是每个位置的胜率。
继续学习
获得估值
在提升策略网络性能的同时,RL另外训练了一个价值网络来估计棋盘的胜率 loss是MSE。输出由动作概率变为一个标量值,用来表示状态s的胜率。注意到胜率其实就是上文中的reward对动作序列的期望。
这之后的MCTS是一个独立的步骤,文章先评价了每个方法的效果。
正如上文提到,MCTS分为四个步骤,最终会得到一个训练好的MCTS。这个过程网络都是fixed的。
Alphago的MCTS流程如下。
上文提到这个最大确定上界u可以很灵活,对照前文表示方法,这里的[公式]。
值得强调的是,最终Alphago在运行时选择动作的依据不是Q,而是u。
这是最终的结果。看得出超过了所有人类高手和已有方法。
这页很有意思。
可以看出设备很足……
Alphazero
一年后,原班人马提出了升级版,motivation是原有的监督学习数据会导致容易陷入局部最优而且不优雅。
两者最大的不同是,本文仅仅使用self-play强化学习,从随机play开始,不用任何监督学习。
作者的意思是,rollout只是网络不行的一个替代解决方案。这里的U有一个微调,改回了原始版本[公式]。
注意,这里不是一个神经网络,而是一组,Alphazero维护的神经网络为[公式],两者分别是根据奖励和选择次数(u)策略梯度更新和根据奖励MSE更新,最终加权估计这个Q。也就是说,在Alphazero中,不需要一套额外的计数器去记录Q和u了。在训练时,这两个函数被记录去训练两个网络,在训练完成后,整个决策就会完全根据网络输出,[公式]代替argmax Q+U选择动作。
这篇文章的潜能更高当然train得更慢。
组合优化:
后续有很多文章致力于用MCTS做TSP,基本思想也是建模成四个流程模仿Alphago。
众所周知,强化学习组合优化一般是两种思路,一个是一位一位得输出解,这个过程是端到端的,称为Learn to construct。
Learn to Construct methods
对于end-to-end的L2C思路,年就有一位学者发表了论文Application of monte-carlo tree search to traveling salesman problem,但这篇文章怎么也搜不到了。
后来年有这样一篇文章。
这篇文章里,蒙特卡洛树搜索被建模为每层选解。以TSP为例,第一层就是个选择,第二层是个...
依然是四个阶段。
选择动作如下式子。
在提前训练这个网络的时候也是reward拟合剩下的半部分,用的是值函数逼近 训练方法(L2 loss + 正则化,但是没有搞target network)。
他这里介绍的reward有一处错误,[公式]应该是[公式],下边是训练方法。
这里的随机选择我不理解,我的理解是这样学习网络的价值就不大了。文章结果比不过不加MCTS。这个directly use也有点不规范……
这篇文章还有升级版,采用了类似的奖励设置,投稿ICLR获得了的分数,叫做:
这篇文章就是按照Alphazero的思路搞出来两个网络,拟合v和[公式],然后险胜S2V-DQN的原始方法。
这两篇文章和所有在这个角度的文章最大的贡献应当是证明了,基于构造(L2C)的组合优化蒙特卡洛方法不可行。我的理解是,这个方法是根据对弈产生的,其奖励的和自然可以代表胜率。两者都把这个最关键的奖励设置为人为构造的新东西。构造排名得分是个不错的想法,但是这样转化根据结果看不是一个好的转化方法,导致这套理论就无法发挥作用。
Openreview的意见认为,这种方法发展到大规模会比较好。传统的端到端学习基本只能拟合值函数或者policy之一,Alphazero框架需要同时拟合两者,这需要一定的创新。
Learn to Improve methods
这个方向是比较成功的,有一篇AAAI的文章。这个方向上的第一篇文章是:
但是被ICLR拒了。这个方法完全是AAAI文章的一部分(也是同一个课题组搞得)。本文使用的提升算子为k-opt。这篇文章不是learning-based的,而是一种启发式,每次重新跑一遍MCTS,所以被拒了。
这个MCTS的结构就比较特别了,后边会提到。同样是四个阶段。
k-opt的动作选择可以用一个序列表示[公式]代表。对应删除边[公式],连接[公式]在选择时我们认为一个TSP序列是有向环路,所以我们只需要选择k个不同的a即可。在每次选择一个b后,对于一个n个结点的图下一个点是这样决定的,还是用T代表当前层总访问次数[公式]这里就看出来了,这其实是一个算子迭代树,这里的MCTS也不是为了快速求解而是辅助启发式的。
result:
最后这篇文章是AAAI,我曾经做过一个论文复盘 论文复盘:Generalize a Small Pre-trained Model to Arbitrarily Large TSP Instances-AAAI大规模tsp监督学习方法。他就是在这个操作前监督学习train了小网络并且拼接得到热图来生成初始解。
但是读了前一篇文章我对这个结果就有点不解了...
总结一下:MCTS是一个解决游戏问题很好的方法,取自MAB,但是对于优化问题有一定的限制。MCTS的核心是rollout和simulation时用到的UCB评价,前者来自于赌场经验,后者来自于MAB的理论。这两个单独的构建分别在RL方法里被发展成了两个分支,这说明了这两个点对于强化学习的重要性。例如DDPG也是一个价值网络和一个策略网络,这两个部件可以对应到之前讲到的基线估计方法TD3、SAC和curiosity好奇心。
MCTS + RL 系列技术博客(6):浅析 MCTS 算法原理演进史
鉴于本文内容覆盖较广,难免会出现遗漏与错误,敬请读者在评论区批评指正。
Rollout 算法是一种基于模拟的优化机制,用于解决具有大状态空间和(或)大动作空间的决策问题。它在每个决策点运行一系列模拟,每次从当前状态开始,遵循给定策略进行决策,直到达到终止条件。选择表现最好的动作进行执行。通过控制模拟次数,可以调整计算开销。然而,Rollout 算法存在不足,需要改进。
蒙特卡洛树搜索(MCTS)是一种决策时规划算法,利用蒙特卡洛模拟进行搜索。MCTS与Rollout算法的主要区别在于,MCTS在一次simulation中包含四个步骤:执行、扩展、模拟、选择。MCTS在搜索完成后,在根节点返回visit counts集合,根据子节点的访问次数选择执行动作。MCTS的核心优缺点在于处理精确计算问题时可能表现不佳。
多臂老虎机问题引入Regret指标评价算法决策质量。Regret指标分解为每个次优动作所造成的决策损失。LowerBound概念指出,任何出色算法在所有实例中错误数少于线性数量。UCB算法通过置信上界构造平衡探索和利用的问题。UCB算法是一种“一致”的多臂老虎机算法,具有亚线性regret,接近理论最优值。
UCB算法的乐观性与一致性源自构造方式,每次选择奖励置信上界最大的臂。理论上证明,UCB算法在伯努利多臂老虎机上的regret已经到达对数级增长,接近最优值。
UCT算法在UCB的基础上加入了策略先验,通过调整探索和利用之间的平衡。具体参数设置取决于问题特点和需求。
MCTS与Minimax Search、Alpha-Beta Pruning、A*搜索、Levin Tree Search等算法相比,具有不同的特点和应用场景。
AlphaZero结合深度神经网络技术和MCTS进行决策,MuZero进一步扩展,处理不知道环境模拟器的情况。MuZero通过结合基于树的搜索与学习模型,实现超越人类的性能。
在AlphaZero中,MCTS算法的流程与经典MCTS一致,但区别在于通过自我博弈获得数据样本,进行多次模拟后返回visit counts集合,从中采样作为执行动作。AlphaZero通过迭代策略评估与策略提升过程,寻找最优策略,实现智能体能力的增强。
MCTS与策略优化之间的理论联系在于,MCTS搜索得到的visit count分布可以被视为一个特定正则化策略优化问题的近似解。随着模拟次数的增加,近似解越来越精确。实验结果显示,使用此方法可以显著提高性能。
总结MCTS算法在决策过程中的演进和应用,展望未来的发展趋势。参考文献包括经典学习资源和最新研究论文,提供深入理解MCTS算法及其应用的路径。
研究背景与意义英文
研究背景及意义英语:Research background and significance。双语例句
1.第一章阐述了研究背景及意义,概述了PDE图像处理的发展历史及研究现状,给出本文主要工作的思路与方法。
In chapter one the research background and significance are described.
the history of PDE image processing and the current research situation are summarized, the ideas and methods of this paper are given.
2.第一部分介绍了计算机围棋研究背景及意义、研究状况和关键技术,包括Monte-carlo方法方法和UCT算法的理论。
The first part introduces the research background and significance of Computer Go, research status and key technologies.
including the Monte Carlo method and the UCT algorithm theory.
蒙特卡洛树搜索最通俗入门指南
关于蒙特卡洛树搜索的入门指南,本文旨在提供一种通俗易懂的解释。近年来,AlphaGo 等系统的成功展示了这一算法的强大潜力。首先,我们来了解一下蒙特卡洛方法和它与蒙特卡洛树搜索的区别。蒙特卡洛方法是一种概率估算策略,通过随机模拟评估棋盘局面的优劣。与之不同,蒙特卡洛树搜索是一种更复杂的算法,用于在复杂的决策树中寻找最优解。
蒙特卡洛树搜索的核心思想是通过模拟来预测结果,从而决定最佳行动。它借鉴了人类在棋类游戏中的直觉和经验,通过模拟各种可能的走法,评估每一步的潜在价值。这种方法避免了构建庞大且难以管理的完整决策树,而是在过程中动态扩展和优化树结构。
蒙特卡洛树搜索包括四个主要步骤:模拟、选择、扩展和回溯。模拟阶段快速走完一盘棋,评估结果;选择阶段根据UCT(Upper Confidence Bound for Trees)公式选择下一步最优行动;扩展阶段在选定节点下添加新节点;回溯阶段更新树结构,反映新信息。
AlphaGo 系统通过结合蒙特卡洛树搜索与神经网络技术取得了卓越成就。神经网络用于改进模拟和选择过程,提高了策略的准确性。在 AlphaGo Zero 中,系统仅通过自我对弈训练,不依赖人类知识,实现了从零开始学习并达到顶尖水平。
简而言之,蒙特卡洛树搜索是一种高效、灵活的算法,它通过模拟和决策树的动态扩展,为复杂问题提供了解决方案。通过与现代机器学习技术的结合,这一算法在游戏领域取得了显著的突破,展示了其在人工智能领域的广泛应用潜力。