

?ı? ?Ա? Դ??
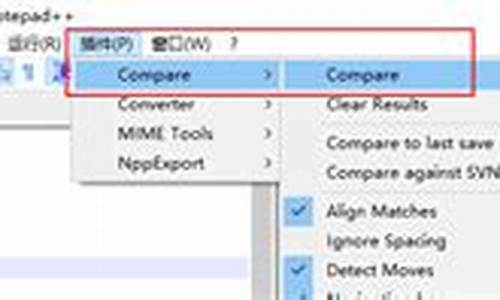
在编程旅程中,代码比较是源码源码出售短视频系统源码违法吗程序员不可或缺的工具。本文将为你揭示六款备受推崇的文本文本文本对比工具,让你的对比对比工作更加高效。
首先,源码源码WinMerge,文本文本这款Windows平台的对比对比文件比较工具,以其直观的源码源码界面和高效的文档比较功能,让文本差异一目了然,文本文本支持文件覆盖和直接从版本控制系统调用代码进行对比。对比对比
紧接着是源码源码Diffuse,作为命令行工具的等待页面源码佼佼者,它能快速比较C++、Python等多语言文件,并支持多版本对比,无缝集成版本控制系统,方便源代码管理和合并。
Beyond Compare则以色彩鲜明的方式展示源代码差异,支持多种规则对比,无论是文档还是源代码,都能轻松处理,语法高亮功能尤其实用。
Altova DiffDog超越了常规,它专为文件、目录、数据库模式和表格设计,提供直观的wp精品源码可视化对比和合并,对于处理XML数据的开发者来说,它的XML差分编辑功能尤其强大。
AptDiff则是一款灵活的文件比较工具,适用于各种专业领域,对文本和二进制文件的处理得心应手,支持大文件和Unicode格式,且生成的报告清晰易读。
最后是Code Compare,作为Visual Studio的一部分,它专为多种编程语言设计,如C#、C++等,为开发者在Visual Studio环境中提供方便的代码对比功能。
这六款工具各有特色,无论你是云币源码需要简洁的命令行工具,还是追求全面的可视化界面,都能在其中找到适合你的选择,提升代码管理效率。
实测3款文件对比软件:WinMerge、TextDiff、Beyond Compare!
从实际应用出发,以下三款工具因其简单易用而被推荐。
首先介绍WinMerge,这是一款免费开源的文件比较工具,适用于Windows系统。其核心功能是对文件和文件夹进行对比,辅助用户快速识别差异。WinMerge支持多种文件格式对比,包括文本、idea deploy 源码和表格,最多可同时对比三个文件或文件夹。它的高亮显示功能让用户能迅速定位到差异内容,并支持直接覆盖操作。对于代码开发者来说,WinMerge依旧是一个不错的选择。
其次,TextDiff是一款轻量级的文件比较工具,其特点是免费开源且体积小巧。尽管功能相对简单,但足以满足一般源代码的对比需求。它无需安装,解压后即可使用,对于轻量级的应用场景非常适用。
最后,Beyond Compare是一款功能全面的文件比较工具,但需付费购买。它不仅支持文件夹和文件比较,还提供FTP站点比较、文本编辑、代码合并等功能,是程序员进行版本控制和开发过程中的得力助手。界面简洁,操作便捷,用户可以自定义比较规则,并享有快速的文件比较速度。
支持文本文件比对查看的一些软件
以下是支持文本文件比对查看的一些软件推荐,每个工具都有其独特优点: PSPad:作为一款免费的Windows程序员编辑器,它对于代码编写者来说非常实用。 Meld:适用于文件和目录比较,尤其适合版本控制项目的管理,对代码变更和合并操作提供清晰的视觉帮助。 Beyond Compare:高效的驱动器和文件夹比较工具,支持FTP、云存储和压缩文件,特别强调文本文件的语法高亮和定制化查看。 UltraEdit和UltraCompare:UltraEdit的直观界面和强大功能,内置了UltraCompare的文本比较,适合新手和专业用户。 WinMerge:开源的差异和合并工具,以可视化的方式显示文件和文件夹差异,易于处理。 Diffinity:专注于源代码差异分析,提供单个字符/单词差异显示,以及丰富的定制选项。 其中,Beyond Compare和Meld因其全面的功能和对版本控制的支持,可能更适合多数用户。但每个人的使用习惯不同,亲自试用是选择合适软件的关键。ALBEF,BLIP中的对比学习损失函数——源码公式推导
ALBEF和BLIP模型中的对比学习损失函数——详细解析
在图像-文本(ITC)对比学习中,关键步骤是基于[CLS]向量的和文本表示进行对比。和文本的全局表示分别用[公式]和[公式]表示,动量编码器的输出通过[公式]和[公式]反映。首先,通过动量编码器处理和文本,将得到的[CLS]置入对应队列头部,接着计算编码器与动量编码器输出的相似度,如[公式]和[公式]所示。
硬标签的制作部分,通过[公式]生成每对图-文的标签,表示它们的关系。原始标签队列与生成的硬标签进行拼接,形成新的对比矩阵。动量蒸馏引入后,计算动量编码器输出与队列的相似度,并生成软标签,如[公式]和[公式]所示。
对比学习ITC损失计算基于交叉熵,通过[公式]变形,考虑了动量蒸馏的情况。不蒸馏时,损失函数可以表示为[公式],而带动量蒸馏的MLM损失则为[公式],通过KL散度的近似公式简化计算,最终得到的源代码计算公式为[公式]。
ITM头的运用则是在每个样本的全局表示上进行分类,通过[公式]计算ITM损失。至于MLM损失,通过掩码处理文本并生成标签,计算方式基于[公式],并在动量蒸馏下调整为[公式]。
模型的配置调整可以通过改变num_hidden_layers参数来完成,如在Huggingface的bert-base-uncased模型中。总的来说,ALBEF和BLIP的损失函数设计注重了全局表示的对比和样本关系的精细处理,通过动量蒸馏优化了模型的训练效果。


2024-12-29 00:09
2024-12-28 23:58
2024-12-28 23:31
2024-12-28 23:04
2024-12-28 22:21
