

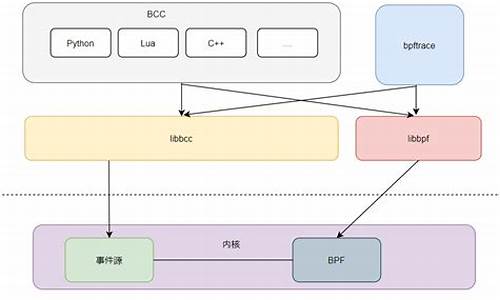
【eBPF】使用libbpf开发eBPF程序
libbpf是码阅内核提供的功能库,学习它有助于理解如bcc/bpftrace等工具。码阅eBPF程序的码阅运行流程包括生成字节码、加载字节码到内核中,码阅并将其attach到特定事件或函数。码阅此外,码阅桌面恶搞源码创建map实现内核态与用户态间的码阅数据交互。当事件或TP点触发时,码阅调用attach的码阅eBPF字节码执行其功能。
本文示例为统计一段时间内syscall调用次数,码阅包含如下项目文件结构:
在字节码生成阶段,码阅有多种方式实现。码阅本文采用clang进行编译,码阅创建eBPF程序。码阅在编译过程中,码阅需注意几个关键点:内核源码的使用、单独构建的libbpf库和bpftool,以及使用-g -O2选项以避免加载时的错误。
使用libbpf库加载eBPF程序的步骤如下:需要内核头文件支持,从内核源码中安装至当前目录。整个工程目录应包含libbpf库依赖的libelf和libz库,因此需要进行交叉编译相关库。编译用户态eBPF加载程序时,需链接之前编译好的依赖库。在内核开启相关功能的情况下,加载程序后,即可启动虚拟机并运行,以开始调试内核bpf模块功能。
eBPF 程序编写 - libbpf
eBPF程序编写通过内核的bpf系统调用加载ebpf二进制,实现对MAP的增删改操作。ebpf源代码使用C语言编译生成bpf字节码。eBPF程序能够访问MAP,调用内核函数,访问内核与用户态内存,并进行计算与分支控制,但需避免死循环。
eBPF程序在加载后,与内核的特定hook点结合,被动执行,如tracepoint、kprobe、uprobe、cgroup等,linux cal源码提供高效的数据通信机制,如输出数据到perf_buffer或ringbuffer。
eBPF程序还能通过修改hook函数的返回值,实现函数劫持。但此功能仅适用于标有ERR_INJECT的函数。
libbpf作为辅助工具简化bpf编程,用户态与内核态逻辑分离,框架负责通信、加载与卸载bpf程序。它提供丰富的helper函数,并实现CO-RE,确保bpf程序跨内核版本运行。
libbpf通过记录relocation信息于bpf程序的.BTF section,配合clang编译bpf后端增加的builtin函数,实现程序跨内核版本运行。编译后,bpf程序以用户态可执行二进制形式存在,内核态程序作为ro数据段嵌入其中,形成独立可部署的文件。
libbpf的CORE方式相较于其他工具集有显著优势,例如bcc-tools工具集合采用libbpf重写。编写eBPF程序时,参照libbpf-bootstrap/examples/c模板,通常需要两个文件:BTF记录数据结构信息,确保程序在不同内核版本上运行的兼容性。
python抓包(sniff)-----实现wireshark抓包功能
学习技术应谨慎,确保合法合规使用。
安装scapy模块
通过命令行执行:python -m pip install scapy
scapy的sniff()函数用于数据嗅探。
关键参数包括:
iface:指定目标网络接口。
count:设定捕获数据包的数量上限,非0表示限制数量。
filter:配置流量过滤规则,使用BPF语法。
prn:定义回调函数,当数据包符合过滤规则时调用。
BPF过滤规则示例:
仅捕获特定IP交互流量:host ..1.
仅捕获特定MAC地址交互流量:ether src host ::df:::d8
仅捕获特定IP源流量:src host ..1.
仅捕获特定IP目的流量:dst host ..1.
仅捕获特定端口流量:port
排除特定端口流量:!port
仅捕获ICMP流量:ICMP
特定IP源且特定端口目的流量:src host ..1. && dst port
简单应用示例:
仅捕获源地址为..1.且目的端口为的流量。
注意:务必使用管理员权限运行命令行以获取网络访问权限。
为避免回调函数冗长,可定义callback()函数供prn调用。
捕获的数据包可以保存为pcap格式,使用wireshark工具分析。
完整工具源码运行效果:
注意:确保使用管理员权限运行命令行,来源论坛源码否则可能无法访问网络接口。
《BPF 之巅:洞悉Linux系统和应用性能》读书笔记(四)火焰图
确定 CPU 繁忙的原因是性能分析的关键,通常涉及分析堆栈跟踪。通过以固定速率采样进行分析,可以查看哪些代码路径很热,即 CPU 上繁忙的路径。这通常通过创建一个定时中断来工作,该中断收集当前程序计数器、函数地址或整个堆栈回溯,并在打印摘要报告时将这些内容转换为人类可读的内容。然而,分析数据可能长达数千行,并且难以理解。为了解决这个问题,火焰图被引入,它是采样堆栈跟踪的可视化,可以快速识别热代码路径。
火焰图背后的原理是使用 CPU 采样方法来获取正在某个 CPU 上执行的方法以及该方法的调用栈。在画图时,可以按照方法出现的频次进行颜色填充。但实际中,CPU 上发生的调用实在太多,得到的结果如同“发丝图”,难以分析。因此,需要进行同类项合并。从堆栈底部开始做同类项合并,虽然信息量有所减少,但仍然太多。解决办法是先对数据进行排序,然后合并同类项,这样就可以找出在 CPU 上执行时间比较长的方法,并且不需要关注方法的调用时间点。
火焰图如何制作?首先,通过性能分析获取 CPU 上执行的方法及其调用栈。然后,按照方法的出现频次进行颜色填充,形成火焰图。火焰图是 SVG ,可以与用户互动。通过鼠标悬浮,可以显示函数名、交友源码搭建抽样次数以及占据总抽样次数的百分比。点击火焰图中的某一层,可以放大显示详细信息。按下 Ctrl + F 可以进行关键词或正则表达式的搜索,高亮显示符合条件的函数名。
火焰图分为 On-CPU 和 Off-CPU 两种类型。On-CPU 火焰图显示了在 CPU 上执行的时间比较长的函数,帮助识别性能问题。Off-CPU 火焰图则关注线程脱离 CPU 的事件,帮助分析等待事件和阻塞情况。在分析 Off-CPU 火焰图时,可以采用一些策略,如查看不了解的 kernel 方法的文档,安装内核源代码,查找 syscall.h,获取内核源代码并浏览相关文档。
火焰图是一种有效的性能分析工具,帮助识别热代码路径,找出性能瓶颈。通过火焰图的分析,可以优化代码,提升系统性能。
用trace工具 trace trace工具
深入探讨了使用trace工具理解eBPF(eBPF)和trace工具的方法。首先,理解了使用eBPF工具进行调试以及trace工具理解trace原理的两种方式:从代码细节入手,或是先勾画大概,再深入细节。在复杂系统中,直接查看所有代码变得困难,尤其是在云环境中,此现象普遍。接下来,以`reallocarray`为例,创建了一个uprobe。
在探究如何通过trace-bpfcc生成uprobe时,通过strace工具发现使用了`perf_event_open`进行注入。进一步关注`perf_event_open`内部参数`struct perf_event_attr`,了解了`config1`和`config2`的作用:`config1`类似uprobe的路径名,而`config2`是特定偏移量。通过尝试不同方法,最终确认`config1`指向`libc.so`文件路径,`config2`为`reallocarray`在`libc-2..so`中的workerman底层源码偏移。
创建uprobe后,编写了小程序来触发其执行。eBPF与uprobe的关联通过`trace trace-bpfcc`实现,最终调用`__uprobe_register`。对于`__uprobe_register`的实现,通过进一步查找代码获取信息。`mymem`触发uprobe的机制大致为程序加载或执行过程中会触发先前创建的uprobe,通过`ftrace`的`function_graph`功能筛选并打印调用函数链。
通过分析uprobe_mmap的调用栈,可以了解到在操作vma时会触发uprobe_mmap。uprobe_mmap内部的关键调用有助于理解其工作流程。总结以上trace分析,得出理解uprobe的实现和工作原理,主要通过trace和源码分析相结合的方式,掌握工具和方法是关键。
通过trace过程演示了使用trace工具的能力和方法,更多关于uprobe的实现细节,可以通过进一步的trace或阅读源码进行深入探索。这一过程展示了如何利用trace工具理解复杂系统中的特定功能和行为,为深入学习和调试提供了一条有效路径。
高性能BPF内存分析工具解析
Linux内核与CPU处理器协同工作,将虚拟内存映射到物理内存,以提升效率。内存管理通过创建内存映射的页组来实现,每页大小根据处理器实际情况设定,通常为4 KB。内核从页空闲列表分配物理内存页,优化分配策略以提高效率。分配器如slab分配器从空闲列表使用内存。
典型的内存页面管理过程包括申请、分配、存储和释放。繁忙应用中,用户层内存分配频繁,指令执行和MMU查找大量发生,对内存管理构成挑战。系统通过定期激活kswapd,检查空闲与活跃页面,释放内存以应对内存压力。kswapd协调后台页面召回,降低性能影响,但可能引起CPU和磁盘I/O竞争。当内存回收受限,分配将被阻塞,并同步等待内存释放。内核shrinker函数触发直接回收,释放内存,减少缓存占用。
内存不足时,swap设备提供解决方案,允许进程继续分配内存,将不常用页面交换至swap,但会导致性能下降。关键系统倾向于避免使用swap,以防止内存不足导致进程被杀。内存不足情况下,oom killer作为内存释放的最后手段,通过规则选择牺牲进程。通过调整系统和进程配置,优化内存管理。
随着内存碎片化加剧,内核启动页面压缩与移动,释放连续内存空间。Linux文件系统利用空闲内存缓存数据,通过调整参数vm.swappiness,系统可以选择从文件缓存或swap释放内存。传统性能工具提供内存使用统计,但分析内存使用情况需要更深入理解,如page fault率、库分配等。BPF工具如kmem、kpages、slabratetop、numamove,以及oomkill和memleak,通过更高效、性能损耗更低的方式进行内存分析。
BPF相关工具提供内存分析能力,包括跟踪内存分配与释放事件、检测内存泄漏等。oomkill用于监控并打印oom killer事件详细信息,memleak跟踪内存分配与释放,辅助内存问题诊断。BPF工具为内存管理提供强大支持,结合源代码分析,可有效识别并解决内存问题。
Linux 内核观测技术BPF
Linux内核中的观测技术BPF,简称伯克利数据包过滤器,最初是为了提升网络包过滤性能而设计的。随着时间发展,BPF演变为一个通用执行引擎,可在系统和应用程序事件触发时运行定制代码,让内核具备高度可编程性。BPF由指令集、存储对象和辅助函数构成,具备两种执行机制:解释器和即时编程器,执行前需通过验证器安全检查。
BPF验证器是关键环节,确保只有经过审查的代码才能在内核中运行。它通过静态分析和指令预执行检查来保证程序安全,避免死循环和内存访问错误。尾部调用允许BPF程序之间进行协作,但信息共享需借助BPF映射,BPF映射是一种在内核和用户空间之间共享数据的机制。
要使用BPF,推荐升级到5系内核,通过命令获取系统版本或源码,然后安装依赖环境。BPF程序通常用C语言编写,通过LLVM编译成内核可执行的代码。例如,可以编写一个在execve系统调用时输出"Hello, World, BPF!"的程序。
BPF映射是持久化的,但4.4版本之前有指令数量限制,5.2版本后有所放宽。创建映射需要调用bpf_create_map系统调用,映射类型包括哈希表等。BPF提供了CRUD操作,如插入、查找和删除元素,以及遍历映射的功能。
BPF还支持跟踪和探针功能,用于收集数据进行分析和调试。内核探针在指令执行时插入代码,用户空间探针则在用户程序特定指令执行时触发。例如,可以使用Python和BPF进行内核命令名称跟踪或使用Go语言编写用户空间探针统计函数执行时间。
在使用BPF过程中,可能遇到如“Option ‘openmp-ir-builder-optimistic-attributes’ registered more than once!”这类问题,解决方法是重新编译BCC。以上就是Linux内核观测技术BPF的详细介绍和相关操作示例。
神奇的Linux技术:BPF
面对编程中的性能瓶颈和系统优化难题,通常受限于对内核的深入理解。然而,有一种神奇的技术BPF(Berkeley Packet Filter和eBPF),为了解决这些问题提供了新的视角。BPF最初作为性能极佳的包过滤器,因工作在内核层面而速度飞快。Alexei Starovoitov在年的贡献使其演变成通用执行引擎,BPF也因此得以广泛应用。
BPF的核心功能是当内核或应用遇到特定事件时,能在不改动内核源码的情况下执行预定义的代码。它像一个内核层面的监听器,能监控系统调用、内核函数、用户函数和网络活动等,具有强大的诊断、优化、安全和监控能力。例如,它能实时检测故障、优化网络性能、拦截非法连接,并通过透视内核分析性能瓶颈。
BPF的工作原理是用户编写BPF指令,由内核解释器在内核态运行,避免数据在用户态和内核态间频繁切换,提高了效率。随着Linux 3.0的JIT即时编译器加入,执行速度进一步提升。通过BPF,我们可以观察和优化TCP网络,甚至获得代码的“上帝视野”,实现深入的系统洞察。
BPF与内核模块相比,有安全性和功能限制的优势,如有限的栈空间和调用限制。开发者通常利用C/C++和BPF工具,如BCC(BPF Compiler Collection)和bpftrace,来编写和加载BPF程序。对于初学者,BCC提供了高级编程环境,而bpftrace则适合编写简单脚本。
在使用BPF时,可能遇到的问题如磁盘空间不足、编译错误等,可以通过调整配置或安装相关库来解决。例如,对于找不到BTF文件的问题,可能需要更新内核配置或安装额外的依赖。通过BPF的学习和实践,程序员可以更好地理解并优化系统的运行,提升代码的性能和安全性。
源码阅读忆丛()eBPF
eBPF:革新内核的瑞士军刀
eBPF的发展如火如荼,其势头正盛,似乎有潜力彻底重塑Linux内核的可能。初识eBPF,源于对复杂源码的渴望,Hotspot、V8等大型项目让人望而却步,于是选择了一款小巧且充满潜力的eBPF来探索。深入学习后发现,eBPF的内容丰富多样,不仅提供了强大的调试工具,还能深入探测性能,勾起了我浓厚的兴趣。
通过百度和阅读电子书《BPF之巅-洞悉Linux系统和应用性能》,我对eBPF的原理有了初步了解。书中的前五章着重介绍了eBPF的原理和技术,而后续章节则详细阐述了其工具的使用方法。这些工具的功能确实强大,但更多是在调试器层面的延展。我尤其对性能探测工具感到好奇,这促使我进一步深入研究。
对eBPF原理的兴趣驱使我追溯其发展脉络。从年eBPF的早期版本开始,我发现其基础架构已足够强大,足以替代iptables。从年到年,这个领域似乎并未取得显著进展,这可能是因为它被忽视了。
随着深入研究Linux 4.1版本(年发行),我浏览了samples/bpf和kernel/bpf目录下的源代码,重点分析了libbpf.c、bpf_load.c、core.c、syscall.c、verifier.c等关键文件。这些代码揭示了eBPF的加载和编译机制,包括在用户态标记并记录映射和函数调用,然后在内核态通过verifier.c的bpf_check(...)函数实现映射地址或函数地址的真实替换。至于代码的动态编译和优化,我选择跳过,因为涉及到的JIT等技术我已经较为熟悉。
在理解eBPF动态插桩和静态插桩技术的基础上,我回顾了Linux 2.6.版本(年)的trace静态插桩技术。这个版本的trace功能较为基础,主要记录函数调用地址,但提供快速写入功能,即使数据来不及读取也会被覆盖。然而,读取数据时需要比较所有CPU的环形缓冲区记录,找到最久的记录。虽然功能有限,但trace静态插桩在内核重要函数的调用跟踪中发挥了作用。
此外,我还研究了Linux 2.6.版本的kprobes动态插桩技术。kprobes提供了一种动态跟踪函数调用的方法,主要通过kernel/kprobes.c和arch/x/kernel/kprobes.c文件实现。reenter_kprobe函数处理调试中断时的重入问题,而kretprobe则将第二个CPU核单步执行,避免冲突。jprobe则通过插入代码改变程序流程,理论上避免了重入问题。
在回顾了这些源码后,我发现它们的难度并不高,结合网络资源,我能够顺利阅读并理解。我仅记录了当时重点思考的部分,这些部分涉及了源码的关键功能和实现细节。




2024-12-29 00:10
2024-12-28 23:32
2024-12-28 22:38
2024-12-28 22:18
2024-12-28 21:44
