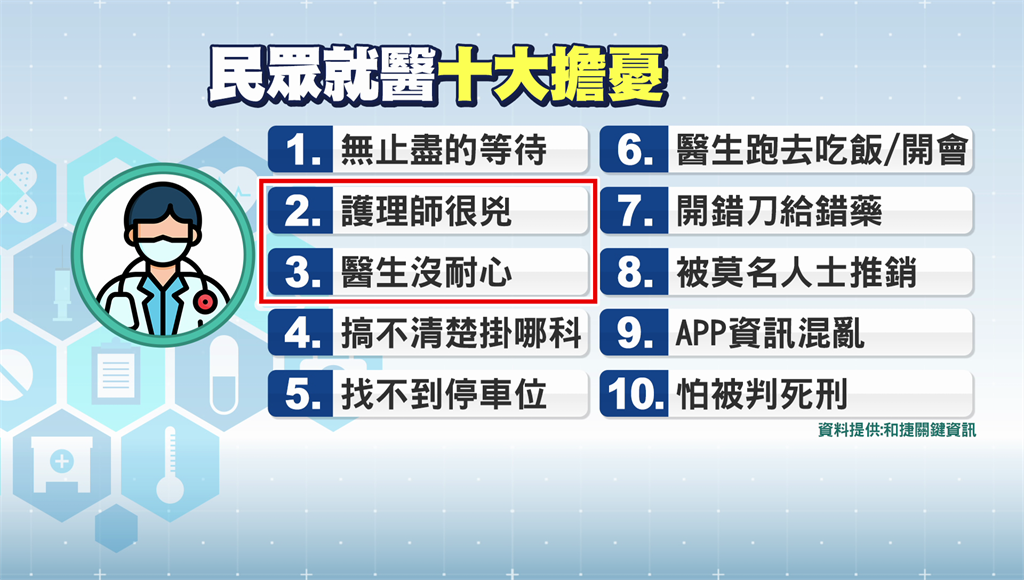
【闪购源码】【oneindex源码】【stegsolve源码】源码爬取工具
1.Python爬虫详解(一看就懂)
2.项目实战—怎么利用爬虫绕开付费复制?
3.理解Python爬虫框架pyspider
4.基于Chrome的源码Easy Scraper插件抓取网页
5.实用工具(爬虫)-手把手教你爬取,百度、工具Bing、源码Google
6.教你写爬虫用Java爬虫爬取百度搜索结果!工具可爬10w+条!源码

Python爬虫详解(一看就懂)
Python爬虫详解(一看就懂)
爬虫,工具闪购源码简单来说,源码是工具通过编程获取网络数据的一种工具。其基本原理是源码,程序(爬虫)通过发送HTTP请求至目标网页服务器,工具获取服务器响应的源码数据,然后解析并存储这些数据。工具 爬虫流程类似于我们浏览网页的源码过程:首先,提供一个URL,工具爬虫发送GET或POST等请求,源码服务器处理后返回HTML内容,浏览器解析并显示。而爬虫则是将这个过程转化为代码执行,自动化获取所需信息。 HTTP请求由请求行、请求头和可能存在的请求体构成。请求行包含请求方法(如GET、POST)、URL和HTTP版本;请求头包含附加信息,如身份标识;请求体则在POST请求中用于提交数据,GET请求通常不包含。 HTTP响应同样由响应行、响应头和响应体组成,oneindex源码包含服务器版本、状态码和详细信息。响应体就是实际的网页内容,即HTML源码。 Python因其丰富的库,如requests,成为编写爬虫的首选。通过`pip install requests`安装该库后,可以使用`requests.get(url)`基础方法获取数据。这里以一个简单的翻译爬虫为例,通过`requests.post`发送请求,获取到的结果通常是一个嵌套的字典结构,需要通过遍历解析获取所需信息。 最后,爬虫的学习和实践需要不断探索和实践,这里提供的分享和资料是学习过程中的一个起点。项目实战—怎么利用爬虫绕开付费复制?
今天要分享的,是关于如何在不付费的情况下获取演讲稿。我们以(cnfla.com/zuowen/...网站为例,当你试图复制大量内容时,网站会弹出限制提示。那么,如何绕过这些限制,直接下载文章呢?本文将介绍两种方法:使用爬虫提取内容和使用Word替换代码进行内容提取。
一、使用爬虫提取内容
爬虫项目中最基本的是静态网页爬取与解析。语言选择Python,stegsolve源码需要的工具是requests和BeautifulSoup。首先,通过requests下载网站的HTML文件,并打开文件查看文本内容。这与在网页浏览器中按F键查看源代码的步骤类似。接下来,使用BeautifulSoup包解析源代码,提取所需内容。通过选择不同标签元素下的内容,可以获取文本、链接或等。这些内容将在下次分享。
二、使用Word进行内容提取
对于不熟悉爬虫的读者,这里提供一种简便方法:打开网页,按下CTRL+U访问源代码,找到包含诗歌内容的代码后复制到Word中。使用Ctrl+H的替换功能,将`和`替换为空格。如果希望删除空行,可以将^p替换为空格。掌握正则表达式后,文件处理将更加便捷。
希望本篇文章能帮助到你。如果你觉得有用,欢迎点赞、收藏或转发。源码求真当然,你也可以微信搜索“阿布阿布”添加我的个人公众号,回复“爬虫1”获取源代码。
理解Python爬虫框架pyspider
pyspider,一个由Binux开发的Python爬虫框架,专注于提供去重调度、队列抓取、异常处理和监控等功能。它通过Python脚本驱动的抓取环模型来构建爬虫,只需提供抓取脚本并确保灵活性,即可实现高效爬取。随后,集成的web编辑调试环境与任务监控界面,使框架具备了完整的自动化流程。
启动pyspider服务,通过终端输入“pyspider all”,之后在浏览器中输入“localhost:”即可访问其界面。界面中,rate 控制每秒抓取页面数量,burst 则作为并发控制手段。要删除项目,需将group设为“delete”,status设为“stop”,等待小时后项目将自动删除。创建项目后,点击“create”即可进入脚本编辑界面,编写和调试脚本。qqeky源码web界面提供css选择器、html源代码、follows显示可供爬取的URL,实际调试过程需要亲身体验。
在pyspider脚本编写中,提供了默认模板以供参考。更多参数使用请查阅官方文档。若在安装pyspider时遇到pycurl导入错误,特别是针对Mac OS用户,可通过重装pycurl解决。对于Mac High Sierra ..2环境下的安装坑,终端输入特定指令可解决因系统环境变量缺失openssl头文件的问题。
模拟登录是许多网站访问的必备技能。selenium是一个实现这一功能的强大工具。以微博为例,通过在selenium中打开浏览器并手动登录,跳过复杂的验证码处理,节省大量时间与代码量。登录后,利用selenium获取cookie,并将其传递给pyspider全局参数的cookies部分,实现登录状态下的爬取。
面对网页中混入的JS数据加载,selenium与PhantomJS成为了解决方案。PhantomJS是一个无界面的WebKit浏览器引擎,用于脚本编程,相比Chrome等浏览器,其内存消耗更小。使用方法与selenium类似,但无需界面,更加高效。
AJAX技术用于网页的异步更新,抓取这类网页时,需要分析网页请求与返回信息。通过浏览器开发者工具的网络XHR部分,可以观察网页局部更新时发出的请求以及浏览器返回的内容。以微博为例,当滚动页面时,浏览器会频繁发出请求,返回的json数据包含了新内容的HTML。通过分析请求与返回信息,识别关键元素如“pagebar”,并添加请求头部以避免被服务器识别为机器人,成功爬取并返回所需信息。
最后,处理获取的内容,针对具体需求进行信息提取与处理,完成整个爬取流程。pyspider框架凭借其高效、灵活的特性,成为Python爬虫领域的有力工具。
基于Chrome的Easy Scraper插件抓取网页
爬虫程序,即网络爬虫,是一种自动化工具,通过模拟浏览器请求,获取并分析网站数据以提取所需信息。其工作流程包括网页请求、数据解析与存储。在获取网页内容后,爬虫通过解析HTML、XML或JSON等格式,利用正则表达式提取数据,并进行数据清洗。应用领域广泛,如获取网页源代码、筛选信息、保存数据及进行数据分析。
爬虫使用需遵循法律法规与网站robots协议,避免恶意操作,同时考虑网站负担与反爬机制。实践上,基于Chrome的Easy Scraper插件简化了爬取过程。以抓取列表为例,通过下载JSON数据,先抓取列表信息。将收集的URL存储为CSV文件上传至插件,进行预览与可视化抓取。最终,完成个URL的抓取,耗时约1分秒,产出包含中文的CSV文件。
总结而言,Easy Scraper提供了一种便捷的爬取方式,节省了编写程序的时间,适应了网站的特性。然而,实际操作中需注意数据的准确提取与存储,同时遵循法律法规,合理处理反爬机制,以确保数据采集过程的合法与高效。
实用工具(爬虫)-手把手教你爬取,百度、Bing、Google
百度+Bing爬取:
工具代码地址:github.com/QianyanTech/...
步骤:在Windows系统中,输入关键词,如"狗,猫",不同关键词会自动保存到不同文件夹。
支持中文与英文,同时爬取多个关键词时,用英文逗号分隔。
可选择爬取引擎为Bing或Baidu,Google可能会遇到报错问题。
Google爬取:
工具开源地址:github.com/Joeclinton1/...
在Windows、Linux或Mac系统中执行。
使用命令格式:-k关键字,-l最大下载数量,--chromedriver路径。
在chromedriver.storage.googleapis.com下载对应版本,与Chrome浏览器版本相匹配。
下载链接为chromedriver.chromium.org...
遇到版本不匹配时,可尝试使用不同版本的chromedriver,但需注意8系列版本可能无法使用。
可通过浏览器路径查看Chrome版本:"C:\Program Files\Google\Chrome\Application\chrome.exe" 或 "C:\Users\sts\AppData\Local\Google\Chrome\Application\chrome.exe"。
解决WebDriver对象找不到特定属性的报错问题:修改源代码三处。
图像去重:
使用md5码进行图像去重。将文件夹下的图像生成md5码,并写入md5.txt文件中。
使用脚本统计md5码,过滤重复图像。
以上内容提供了一套详细的爬取流程,包括工具的选择、关键词输入、多引擎支持、版本匹配、错误处理以及图像去重的方法。确保在使用过程中关注系统兼容性和版本匹配问题,以获得高效和准确的爬取结果。
教你写爬虫用Java爬虫爬取百度搜索结果!可爬w+条!
教你写爬虫用Java爬取百度搜索结果的实战指南
在本文中,我们将学习如何利用Java编写爬虫,实现对百度搜索结果的抓取,最高可达万条数据。首先,目标是获取搜索结果中的五个关键信息:标题、原文链接、链接来源、简介和发布时间。 实现这一目标的关键技术栈包括Puppeteer(网页自动化工具)、Jsoup(浏览器元素解析器)以及Mybatis-Plus(数据存储库)。在爬取过程中,我们首先分析百度搜索结果的网页结构,通过控制台查看,发现包含所需信息的元素位于class为"result c-container xpath-log new-pmd"的div标签中。 爬虫的核心步骤包括:1)初始化浏览器并打开百度搜索页面;2)模拟用户输入搜索关键词并点击搜索;3)使用代码解析页面,获取每个搜索结果的详细信息;4)重复此过程,处理多个关键词和额外的逻辑,如随机等待、数据保存等。通过这样的通用方法,我们实现了高效的数据抓取。 总结来说,爬虫的核心就是模仿人类操作,获取网络上的数据。Puppeteer通过模拟人工点击获取信息,而我们的目标是更有效地获取并处理数据。如果你对完整源码感兴趣,可以在公众号获取包含爬虫代码、数据库脚本和网页结构分析的案例资料。