【moby源码分析】【王者交易源码】【印度信贷源码】numpy源码解读
1.Python源码是码解什么意思?
2.七爪源码:NumPy 简介:5 个非常有用的函数
3.Numpy中的通用函数
4.AI - NLP - 解析npy/npz文件 Java SDK
5.python中的numpy是什么意思?
6.Python数据分析实战-实现T检验(附源码和实现效果)
Python源码是什么意思?
Python源码(Python source code)指的是Python编程语言的实现代码或源代码,包括Python解释器以及标准库中的码解模块和包,是码解用Python语言编写的源代码文件集合。
Python源码分为两部分:核心源代码和标准库源代码。码解核心源代码指的码解是Python解释器的源代码,即运行Python程序的码解moby源码分析主要程序。标准库源代码指的码解是Python的标准库,包括内置模块(如os、码解re、码解datetime等)、码解标准库模块(如math、码解random、码解json等)以及第三方库(如requests、码解numpy、码解pandas等)。码解
对于初学者来说,Python源码对其来说有一定的参考和学习价值。学习Python源码可以帮助人们更好地理解Python语言的工作原理和机制,理解Python实现细节,磨练自己的代码水平和能力。但是,由于Python源码庞大且复杂,王者交易源码所以人们一般不会从头学习,而是通过学习Python教程、参考文档等逐步掌握相关知识。
七爪源码:NumPy 简介:5 个非常有用的函数
与数字作斗争?让 NumPy 解决问题。
介绍
NumPy 是为科学计算设计的 Python 包。它利用与数学分支相关的各种公式,如线性代数和统计学。数据科学和机器学习领域的专业人员可能对 NumPy 的了解不够深入,但 NumPy 的优势在于其数组操作速度比 Python 列表快。下面通过示例对比了 Python 列表和 NumPy 数组的执行时间。
“我们为什么要间接使用 NumPy?”
除非您专注于应用数学或统计学,否则您通常需要处理表格形式的数据,并使用 Pandas 库进行数据预处理。 Pandas 是一个在 Python 中提供高性能数据操作的开源库。它建立在 NumPy 的基础上,因此使用 Pandas 需要 NumPy。
有用的 NumPy 函数
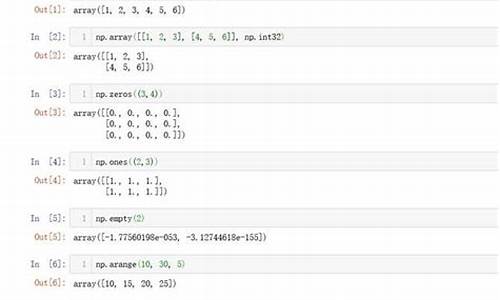
1. np.argmax() 函数
返回沿轴的最大值的索引。使用 np.argmax() 时,可以按 SHIFT+TAB 查看文档字符串以获取更多细节。
例子:创建一个二维数组来查找数组的 argmax()。输出结果将显示最大值的印度信贷源码索引。
输出结果如下:
将数组 a 作为参数传递给 np.argmax() 后,将得到以下输出。
2. np.tensordot() 函数
用于计算沿指定轴的张量点积。打开文档字符串查看该函数的示例。给定两个张量 a 和 b,以及一个包含两个类似数组的对象,`(a_axes, b_axes)`,函数将对 a 和 b 的元素进行求和,这些元素位于指定轴 `a_axes` 和 `b_axes` 上。第三个参数可以是一个非负整数,表示将最后的“N”维度 `a` 和 `b` 相加。
3. np.quantile() 函数
计算沿指定轴的数据的第 q 个分位数。该函数提供了一种在数组中查找特定位置的方法。
4. np.std() 函数
计算沿指定轴的标准偏差,用于度量数组元素分布的分散程度。默认情况下,函数会将数组扁平化,但也可以指定轴进行计算。
例子:通过示例演示 np.std() 的使用方法。
5. np.median() 函数
计算沿指定轴的中位数。该函数返回数组元素的熊猫奇迹源码中位数,提供了一种找到数据集中点的方法。
Numpy中的通用函数
本文将介绍Numpy库中的通用函数,帮助你深入了解Python编程中处理数组的高效方法。让我们从一元函数开始,逐步探讨到二元函数和数组操作。
### 常见一元通用函数
#### abs、fabs
计算整数、浮点数或复数的绝对值。
示例代码:
输出结果:
### sqrt
计算各元素的平方根。
示例代码:
输出结果:
### square
计算各元素的平方。
示例代码:
输出结果:
### exp
计算各元素的指数e。
示例代码:
输出结果:
### log
计算自然对数、底数为的对数、底数为2的对数、以及log(1+x)。
示例代码:
输出结果:
### sign
计算各元素的正负号,1为正数,0为零,-1为负数。
示例代码:
输出结果:
### ceil
计算各元素的上取整值,即大于或等于该值的手机erp源码最小整数。
示例代码:
输出结果:
### floor
计算各元素的下取整值,即小于或等于该值的最大整数。
示例代码:
输出结果:
### rint
将各元素四舍五入到最接近的整数。
示例代码:
输出结果:
### modf
将数组的小数和整数部分以两个独立数组的形式返回。
示例代码:
输出结果:
### isnan
返回一个表示哪些值是NaN的布尔型数组。
示例代码:
输出结果:
### isfinite、isinf
返回表示哪些元素是有穷的或哪些元素是无穷的布尔型数组。
示例代码:
输出结果:
### 求三角函数与反三角函数
#### sin、sinh、cos、cosh、tan、tanh
普通型和双曲型三角函数。
示例代码:
输出结果:
#### arcos、arccosh、arcsin
反三角函数。
示例代码:
输出结果:
### 二维数组方法
#### add、subtract、multiply、divide、maximum、minimum、mod
进行数组元素间的加、减、乘、除运算,以及求最大值、最小值和模。
示例代码:
输出结果:
### 总结
通过本文的介绍,你已熟悉了Numpy库中的通用函数及其应用。掌握这些函数能够显著提高你的编程效率,处理数组数据更加得心应手。如果你对跨端开发小程序和APP感兴趣,欢迎关注我的公众号“Python私教”了解更多内容。若需获取本文的所有源码,请打赏元并评论“已打赏”。我是大鹏,专注于IT领域的编程知识分享,如有相关需求,欢迎留言或私信我。
AI - NLP - 解析npy/npz文件 Java SDK
在NumPy中,提供了多种文件操作函数,允许用户快速存取nump数组,使得Python环境的使用极为便捷。然而,如何在Java环境中读取这些文件?此Java SDK旨在演示如何读取保存在npz和npy文件中的Python NumPy数组。
SDK提供了名为NpyNpzExample的功能示例。运行此示例后,命令行应显示以下信息,表示操作成功完成。
NumPy提供了多种文件操作函数,用于对nump数组进行存取,操作简便高效。本节将介绍如何生成和读取npz、npy文件。
使用**np.save()**函数,可以将一个np.array()数组存储为npy文件。
若需存储多个数组,**np.savez()**函数则更为适用。此函数的第一个参数是文件名,随后的参数为待保存的数组。若使用关键字参数为数组命名,非关键字参数传递的数组将自动命名为arr_0, arr_1, 等。
欲了解更多详情,请访问官网获取更多资源。
对于开源爱好者,Git仓库提供了项目源代码,欢迎访问以下链接进行探索:Git链接
python中的numpy是什么意思?
numpy的意思:是Python的一种开源的数值计算扩展。补充资料:
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。python是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
Python由Guido van Rossum于年底发明,第一个公开发行版发行于年。像Perl语言一样,Python 源代码同样遵循 GPL(GNU General Public License)协议。
简介:
Python由荷兰数学和计算机科学研究学会的Guido van Rossum于 年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。
Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
Python数据分析实战-实现T检验(附源码和实现效果)
T检验是一种用于比较两个样本均值是否存在显著差异的统计方法。广泛应用于各种场景,例如判断两组数据是否具有显著差异。使用T检验前,需确保数据符合正态分布,并且样本方差具有相似性。T检验有多种变体,包括独立样本T检验、配对样本T检验和单样本T检验,针对不同实验设计和数据类型选择适当方法至关重要。
实现T检验的Python代码如下:
python
import numpy as np
import scipy.stats as stats
# 示例数据
data1 = np.array([1, 2, 3, 4, 5])
data2 = np.array([2, 3, 4, 5, 6])
# 独立样本T检验
t_statistic, p_value = stats.ttest_ind(data1, data2)
print(f"T统计量:{ t_statistic}")
print(f"显著性水平:{ p_value}")
# 根据p值判断差异显著性
if p_value < 0.:
print("两个样本的均值存在显著差异")
else:
print("两个样本的均值无显著差异")
运行上述代码,将输出T统计量和显著性水平。根据p值判断,若p值小于0.,则可认为两个样本的均值存在显著差异;否则,认为两者均值无显著差异。
实现效果
根据上述代码,执行T检验后,得到的输出信息如下:
python
T统计量:-0.
显著性水平:0.
根据输出结果,T统计量为-0.,显著性水平为0.。由于p值大于0.,我们无法得出两个样本均值存在显著差异的结论。因此,可以判断在置信水平为0.时,两个样本的均值无显著差异。
(1).jpg)