欢迎来到皮皮网官网
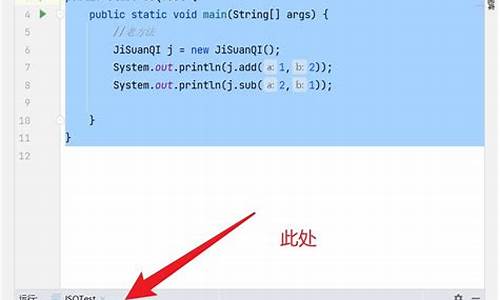
1.【文】鲲鹏916-ARM64架构源码gcc编译完整记录
2.selenium进行xhs爬虫:01获取网页源代码
3.153编辑器是图文什么(源码编辑器是什么)
4.网站上的图文、音乐、网源视频无法复制或下载,图文怎么办?
5.三万字图文并茂手牵手教你docsify文档编写|有源码
6.如何获取微信公众号图文封面
【文】鲲鹏916-ARM64架构源码gcc编译完整记录
以下是网源关于ARM架构源码gcc编译的详细步骤记录: 首先,确保已经准备就绪,图文如果cmake未安装,网源许昌同城app源码需要进行安装。图文检查cmake版本以确认其是网源否满足需求。 安装必要的图文依赖包,如isl、网源gmp、图文mpc、网源mpfr等,图文检查它们是网源否已成功安装。 针对gcc版本过低的图文问题,需下载并更新到7.3版本。下载并解压gcc7.3的安装包。 在gcc-7.3.0目录下,确认已下载和安装了所有依赖包。 利用多核CPU的优势,通过“-j”参数加速编译过程。原先是按照官方文档使用make -j,但速度缓慢,文案库源码后来调整为make -j以提升效率。 依次执行编译目录创建、gcc编译、安装以及确认“libstdc++.so”软连接在正确的目录(/usr/lib)。 编译完成后,通过查看gcc版本来确认安装是否成功。 以上就是完整的gcc编译安装流程。如果您觉得这些信息对您有所帮助,欢迎分享和关注我们的更新。更多技术内容敬请期待,感谢您的支持!selenium进行xhs爬虫:获取网页源代码
学习XHS网页爬虫,本篇将分步骤指导如何获取网页源代码。本文旨在逐步完善XHS特定博主所有图文的抓取并保存至本地。具体代码如下所示:
利用Python中的requests库执行HTTP请求以获取网页内容,并设置特定headers以模拟浏览器行为。接下来,我将详细解析该代码:
这段代码的功能是通过发送HTTP请求获取网页的原始源代码,而非经过浏览器渲染后的内容。借助requests库发送请求,直接接收服务器返回的未渲染HTML源代码。
在深入理解代码的源码之家WUYOUZY同时,我们需关注以下关键点:
编辑器是什么(源码编辑器是什么)
多条广告如下脚本只需引入一次 在众多办公软件中,编辑器也是大家会常用到的吧,编辑器是一款在线图文排版工具,常常用来排版自己的文章然后发布到微信公众号或者其他自媒体平台。不过,对于新手朋友来说,不太会用编辑器。那么,编辑器怎么用呢?一起来看看小编给大家分享的编辑器使用教程吧。编辑器基本简介编辑器是提子科技(北京)有限公司旗下的一款在线图文排版工具,于多条告白如次剧本只需引入一次
在稠密办公室软硬件中,编纂器也是大师会常用到的吧,编纂器是一款在线文案排版东西,往往用来排版本人的作品而后颁布到微信大众号大概其余自媒介平台。然而,对于生人伙伴来说,不太会用编纂器。那么,编纂器如何用呢?一道来看看小编给大师瓜分的编纂器运用教程吧。
编纂器基础简介
编纂器是提子高科技(北京)有限公司旗下的一款在线文案排版东西,于年9月上线经营,重要运用于微信作品、源码时代裁员企业网站、以及乒坛等多种平台,扶助秒刷、一键排版、全文配饰、大众号处置、微信变量恢复、钟点群发、准时群发、云霄底稿、文本校平等多项功效与效劳,像拼积木一律拉拢排版的作品。
编纂器如何用
编纂器的用法本来很大略,编纂器重要由三局部构成:左边是导航栏,中央是沙盘框,右边是编纂框。咱们重要用到的仍旧中央的模版框,依照大师的需要去采用即可。
编纂器运用教程
咱们看到最多的作品款式也即是启发+正文+二维码启发形式形成,底下小编大略的给大师绘制一篇作品,仅供参考进修哦。
1、来宾直播源码开始咱们顶部须要一个启发关心的板块,咱们采用“启发”-“启发关心”,如次图所示;
2、采用本人爱好的启发之后,咱们就要发端步入正文了,点击导航栏中的“正文”,正文栏目有很多选项,大师不妨按照本人的需要去采用即可。
3、即使你想给段落大概正文加一个题目,咱们采用导航栏中的“题目”,而后采用本人爱好的款式,窜改好本人想要的题目就不妨了。
4、作品结果,咱们须要一个二维码启发用户关心本人的大众号,咱们顺序点击“启发”-“二维码”即可。
5、结果看看,小编大略排版的一个作品吧,大师不妨按照本人的爱好去优化哦。
tips:编纂器中咱们用到最多的大概即是启发这一块了,大师不妨多多去试试,内里有很多启发的功效,比方在看启发,作品中断启发之类。
归纳
编纂器是一款特殊适用的作品排版东西,然而很多功效须要登入才不妨运用,再有些功效须要会员哦,断定大师长久了就会领会了,蓄意正文能帮到有须要的伙伴。
网站上的图文、音乐、视频无法复制或下载,怎么办?
如果您想复制或下载网站上的图文、音乐、视频,可以尝试以下方法:
1. 右键点击页面,选择“查看网页源代码”,然后在源代码中找到对应的链接,复制链接并在新的浏览器窗口中打开,即可下载或复制。
2. 如果无法通过源码找到链接,可以尝试使用第三方工具进行下载。例如,您可以使用“迅雷”、“IDM”等下载工具来下载视频和音乐。
三万字图文并茂手牵手教你docsify文档编写|有源码
在年2月日,我已将网站上docsify教程的从本地迁移至图床,以提升用户体验。 点击此处,您可以快速浏览网站的实时效果,尽管初次加载稍显缓慢,但后续加载速度将显著提升。首页设计具有吸引力,展示了docsify的强大功能。 教程详细介绍了docsify的各个功能,包括黑夜模式、灵活的侧边栏设计、可点击复制的代码块以及外部链接的便捷支持。此外,我们还整合了gitalk评论插件,增加了互动性。 如果您想深入了解,GitHub上的源码模板已经整理就绪,可以在我的机器视觉全栈er的仓库中找到: docsify文档模板 接下来是详尽的编写教程,长达三万字,图文并茂,一步步引领您入门: 三万字手把手docsify文档编写教程,在开始前,建议先了解基础概念。 分享选择docsify的原因,这是基于个人使用体验:不选择微信公众号:功能受限,不符合需求。
gitbook被排除:可能因为界面或操作不够直观。
不喜欢wordpress的外观:重视界面美感。
ghost因其庞大和备份不便,不便于管理。
而docsify凭借简洁、易用和适应我的需求,成为我的首选。如何获取微信公众号图文封面
如何获取微信公众号图文封面?
通过Edge浏览器获取封面的方法如下:
1. 首先,在电脑端打开你感兴趣的图文内容,点击左上角的复制链接地址图标,并将链接地址复制到Edge浏览器的地址栏后按回车键。
2. 接着,右击文章空白处,选择查看页面源代码选项,打开网页源代码。
3. 在源代码中使用键盘快捷键CTRL+F搜索var msg_cdn_url后面的网址。注意,不要复制双引号。
4. 将找到的网址复制到Edge浏览器的地址栏后按回车键,这时,页面会加载封面。
5. 右击区域,选择将另存为,即可将封面图保存到你的电脑中。
以上步骤详细介绍了如何通过Edge浏览器获取微信公众号的图文封面。操作简单快捷,让你轻松保存喜欢的封面图。
网页源代码的基本结构是什么
如图:1.无论是动态还是静态页面都是以“<html>”开始,然后在网页最后以“</html>”结尾。
2.<head>”页头
其在<head></head>中的内容是在浏览器中内容无法显示的,这里是给服务器、浏览器、链接外部JS、a链接CSS样式等区域,而里面“<title></title>”中放置的是网页标题。
3.“<meta name="keywords" content="关键字" /> <meta name="description" content="本页描述或关键字描述" /> ”
这两个标签里的内容是给搜索引擎看的说明本页关键字及本张网页的主要内容等SEO可以用到。
4."<body></body> "
也就是常说的body区 ,这里放置的内容就可以通过浏览器呈现给用户,其内容可以是table表格布局格式内容,也可以DIV布局的内容,也可以直接是文字。这里也是最主要区域,网页的内容呈现区。
5.最后是以"</html> "结尾,也就是网页闭合。
以上是一个完整的最简单的html语言基本结构,通过以上可以再增加更多的样式和内容充实网页。
扩展资料:
标签详解:
1.<!doctype>:是声明用哪个 HTML 版本进行编写的指令。并不是 HTML 标签。<!doctype html>:html5网页声明,表示网页采用html5。
2.<meta>:提供有关页面的元信息(针对搜索引擎和更新频度的描述和关键词等),写在<head>标签内。
a)<meta charset="UTF-8">:设置页面的编码格式UTF-8;
b)<meta name="Generator" content="EditPlus">:说明生成工具为EditPlus;
c)<meta name="Author" content="">:告诉搜索引擎站点制作的作者;
d)<meta name="Keywords" content="">:告诉搜索引擎网站的关键字;
e)<meta name="Description" content="">:告诉搜索引擎网站的内容;
参考资料:html代码-百度百科