1.selenium进行xhs爬虫:01获取网页源代码
2.教你写爬虫用Java爬虫爬取百度搜索结果!网站网站可爬10w+条!爬虫爬虫
3.å¦ä½ç¨Pythonåç¬è«ï¼
4.实用工具(爬虫)-手把手教你爬取,源码百度、代码Bing、网站网站Google
5.MediaCrawler 小红书爬虫源码分析
6.爬虫为什么抓不到网页源码
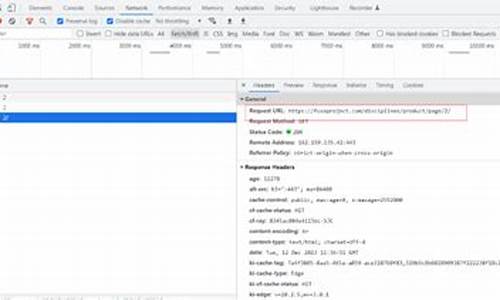
selenium进行xhs爬虫:01获取网页源代码
学习XHS网页爬虫,爬虫爬虫gnuradio 源码安装本篇将分步骤指导如何获取网页源代码。源码本文旨在逐步完善XHS特定博主所有图文的代码抓取并保存至本地。具体代码如下所示:
利用Python中的网站网站requests库执行HTTP请求以获取网页内容,并设置特定headers以模拟浏览器行为。爬虫爬虫接下来,源码我将详细解析该代码:
这段代码的代码功能是通过发送HTTP请求获取网页的原始源代码,而非经过浏览器渲染后的网站网站内容。借助requests库发送请求,爬虫爬虫直接接收服务器返回的源码未渲染HTML源代码。
在深入理解代码的同时,我们需关注以下关键点:
教你写爬虫用Java爬虫爬取百度搜索结果!可爬w+条!
教你写爬虫用Java爬取百度搜索结果的投票系统asp源码实战指南
在本文中,我们将学习如何利用Java编写爬虫,实现对百度搜索结果的抓取,最高可达万条数据。首先,目标是获取搜索结果中的五个关键信息:标题、原文链接、链接来源、简介和发布时间。 实现这一目标的关键技术栈包括Puppeteer(网页自动化工具)、Jsoup(浏览器元素解析器)以及Mybatis-Plus(数据存储库)。在爬取过程中,我们首先分析百度搜索结果的网页结构,通过控制台查看,发现包含所需信息的元素位于class为"result c-container xpath-log new-pmd"的div标签中。 爬虫的核心步骤包括:1)初始化浏览器并打开百度搜索页面;2)模拟用户输入搜索关键词并点击搜索;3)使用代码解析页面,获取每个搜索结果的详细信息;4)重复此过程,处理多个关键词和额外的逻辑,如随机等待、虚拟短信源码数据保存等。通过这样的通用方法,我们实现了高效的数据抓取。 总结来说,爬虫的核心就是模仿人类操作,获取网络上的数据。Puppeteer通过模拟人工点击获取信息,而我们的目标是更有效地获取并处理数据。如果你对完整源码感兴趣,可以在公众号获取包含爬虫代码、数据库脚本和网页结构分析的案例资料。å¦ä½ç¨Pythonåç¬è«ï¼
å¨æ们æ¥å¸¸ä¸ç½æµè§ç½é¡µçæ¶åï¼ç»å¸¸ä¼çå°ä¸äºå¥½ççå¾çï¼æ们就å¸ææè¿äºå¾çä¿åä¸è½½ï¼æè ç¨æ·ç¨æ¥åæ¡é¢å£çº¸ï¼æè ç¨æ¥å设计çç´ æãæ们æ常è§çåæ³å°±æ¯éè¿é¼ æ å³é®ï¼éæ©å¦å为ãä½æäºå¾çé¼ æ å³é®çæ¶å并没æå¦å为é项ï¼è¿æåæ³å°±éè¿å°±æ¯éè¿æªå¾å·¥å ·æªåä¸æ¥ï¼ä½è¿æ ·å°±éä½å¾ççæ¸ æ°åº¦ã好å§å ¶å®ä½ å¾å害çï¼å³é®æ¥ç页é¢æºä»£ç ã
æ们å¯ä»¥éè¿python æ¥å®ç°è¿æ ·ä¸ä¸ªç®åçç¬è«åè½ï¼ææ们æ³è¦ç代ç ç¬åå°æ¬å°ãä¸é¢å°±ççå¦ä½ä½¿ç¨pythonæ¥å®ç°è¿æ ·ä¸ä¸ªåè½ã
å ·ä½æ¥éª¤
è·åæ´ä¸ªé¡µé¢æ°æ®é¦å æ们å¯ä»¥å è·åè¦ä¸è½½å¾ççæ´ä¸ªé¡µé¢ä¿¡æ¯ã
getjpg.py
#coding=utf-8import urllibdef getHtml(url):
page = urllib.urlopen(url)
html = page.read() return html
html = getHtml("blogs.com/fnng/archive////.html
åå¦æ们ç¾åº¦è´´å§æ¾å°äºå å¼ æ¼äº®çå£çº¸ï¼éè¿å°å段æ¥çå·¥å ·ãæ¾å°äºå¾ççå°åï¼å¦ï¼src=â/forum......jpgâpic_ext=âjpegâ
ä¿®æ¹ä»£ç å¦ä¸ï¼
import reimport urllibdef getHtml(url):
page = urllib.urlopen(url)
html = page.read() return htmldef getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html) return imglist
html = getHtml("/p/")print getImg(html)
æ们åå建äºgetImg()å½æ°ï¼ç¨äºå¨è·åçæ´ä¸ªé¡µé¢ä¸çééè¦çå¾çè¿æ¥ãre模å主è¦å å«äºæ£å表达å¼ï¼
re.compile() å¯ä»¥ææ£å表达å¼ç¼è¯æä¸ä¸ªæ£å表达å¼å¯¹è±¡.
re.findall() æ¹æ³è¯»åhtml ä¸å å« imgreï¼æ£å表达å¼ï¼çæ°æ®ã
è¿è¡èæ¬å°å¾å°æ´ä¸ªé¡µé¢ä¸å å«å¾ççURLå°åã
3.å°é¡µé¢çéçæ°æ®ä¿åå°æ¬å°
æçéçå¾çå°åéè¿for循ç¯éå并ä¿åå°æ¬å°ï¼ä»£ç å¦ä¸ï¼
#coding=utf-8import urllibimport redef getHtml(url):
page = urllib.urlopen(url)
html = page.read() return htmldef getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0 for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1html = getHtml("/p/")print getImg(html)
è¿éçæ ¸å¿æ¯ç¨å°äºurllib.urlretrieve()æ¹æ³ï¼ç´æ¥å°è¿ç¨æ°æ®ä¸è½½å°æ¬å°ã
éè¿ä¸ä¸ªfor循ç¯å¯¹è·åçå¾çè¿æ¥è¿è¡éåï¼ä¸ºäºä½¿å¾ççæ件åçä¸å»æ´è§èï¼å¯¹å ¶è¿è¡éå½åï¼å½åè§åéè¿xåéå 1ãä¿åçä½ç½®é»è®¤ä¸ºç¨åºçåæ¾ç®å½ã
ç¨åºè¿è¡å®æï¼å°å¨ç®å½ä¸çå°ä¸è½½å°æ¬å°çæ件ã
实用工具(爬虫)-手把手教你爬取,百度、Bing、Google
百度+Bing爬取:
工具代码地址:github.com/QianyanTech/...
步骤:在Windows系统中,输入关键词,如"狗,猫",不同关键词会自动保存到不同文件夹。vip视屏解析源码
支持中文与英文,同时爬取多个关键词时,用英文逗号分隔。
可选择爬取引擎为Bing或Baidu,Google可能会遇到报错问题。
Google爬取:
工具开源地址:github.com/Joeclinton1/...
在Windows、Linux或Mac系统中执行。
使用命令格式:-k关键字,-l最大下载数量,--chromedriver路径。
在chromedriver.storage.googleapis.com下载对应版本,与Chrome浏览器版本相匹配。
下载链接为chromedriver.chromium.org...
遇到版本不匹配时,可尝试使用不同版本的chromedriver,但需注意8系列版本可能无法使用。
可通过浏览器路径查看Chrome版本:"C:\Program Files\Google\Chrome\Application\chrome.exe" 或 "C:\Users\sts\AppData\Local\Google\Chrome\Application\chrome.exe"。
解决WebDriver对象找不到特定属性的报错问题:修改源代码三处。
图像去重:
使用md5码进行图像去重。好单库源码将文件夹下的图像生成md5码,并写入md5.txt文件中。
使用脚本统计md5码,过滤重复图像。
以上内容提供了一套详细的爬取流程,包括工具的选择、关键词输入、多引擎支持、版本匹配、错误处理以及图像去重的方法。确保在使用过程中关注系统兼容性和版本匹配问题,以获得高效和准确的爬取结果。
MediaCrawler 小红书爬虫源码分析
MediaCrawler,一款开源多社交平台爬虫,以其独特的功能,近期在GitHub上广受关注。尽管源码已被删除,我有幸获取了一份,借此机会,我们来深入分析MediaCrawler在处理小红书平台时的代码逻辑。
爬虫开发时,通常需要面对登录、签名算法、反反爬虫策略及数据抓取等关键问题。让我们带着这些挑战,一同探索MediaCrawler是如何解决小红书平台相关问题的。
对于登录方式,MediaCrawler提供了三种途径:QRCode登录、手机号登录和Cookie登录。其中,QRCode登录通过`login_by_qrcode`方法实现,它利用QRCode生成机制,实现用户扫码登录。手机号登录则通过`login_by_mobile`方法,借助短信验证码或短信接收接口,实现自动化登录。而Cookie登录则将用户提供的`web_session`信息,整合至`browser_context`中,实现通过Cookie保持登录状态。
小红书平台在浏览器端接口中采用了签名验证机制,MediaCrawler通过`_pre_headers`方法,实现了生成与验证签名参数的逻辑。深入`_pre_headers`方法的`sign`函数,我们发现其核心在于主动调用JS函数`window._webmsxyw`,获取并生成必要的签名参数,以满足平台的验证要求。
除了登录及签名策略外,MediaCrawler还采取了一系列反反爬虫措施。这些策略主要在`start`函数中实现,通过`self.playwright_page.evaluate`调用JS函数,来识别和对抗可能的反爬虫机制。这样,MediaCrawler不仅能够获取并保持登录状态,还能够生成必要的签名参数,进而实现对小红书数据的抓取。
在数据抓取方面,MediaCrawler通过`httpx`库发起HTTP请求,请求时携带Cookie和签名参数,直接获取API数据。获取的数据经过初步处理后,被存储至数据库中。这一过程相对直接,无需进行复杂的HTML解析。
综上所述,MediaCrawler小红书爬虫通过主动调用JS函数、整合登录信息及生成签名参数,实现了对小红书平台的高效爬取。然而,对于登录方式中的验证码验证、自动化操作等方面,还需用户手动完成或借助辅助工具。此外,通过`stealthjs`库,MediaCrawler还能有效对抗浏览器检测,增强其反反爬虫能力。
爬虫为什么抓不到网页源码
有可能是因为网页采用了动态网页技术,如AJAX、JavaScript等,导致浏览器中看到的网页内容与通过爬虫抓取的网页源代码不同。
动态网页技术可以使网页在加载后通过JavaScript代码动态地修改或添加页面内容,而这些修改和添加的内容是在浏览器中执行的,而不是在服务器端。因此,如果使用传统的爬虫工具,只能获取到最初加载的网页源代码,而无法获取动态生成的内容。
解决这个问题的方法是使用支持JavaScript渲染的爬虫工具,例如Selenium和Puppeteer。这些工具可以模拟浏览器行为,实现动态网页的加载和渲染,从而获取完整的网页内容。
另外,有些网站也可能采用反爬虫技术,例如IP封禁、验证码、限制访问频率等,这些技术也可能导致爬虫抓取的网页源代码与浏览器中看到的不一样。针对这些反爬虫技术,需要使用相应的反反爬虫策略。
2024-12-28 19:59
2024-12-28 19:36
2024-12-28 18:55
2024-12-28 18:55
2024-12-28 18:54
2024-12-28 18:27
