1.JSF源码分析(一)
2.主机安全技术剖析-关于Windows RPC挖掘的框框架那些事
3.Dubbo—SPI及自适应扩展原理
4.一文读懂,硬核 Apache DolphinScheduler3.0 源码解析
5.TPRC-cpp 发送包流程剖析
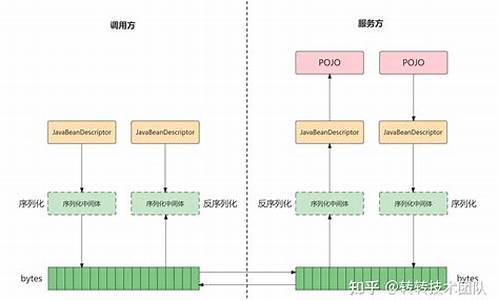
JSF源码分析(一)
在深入分析 JSF 框架的用源原理源码时,我们首先关注的码解是核心的功能模块,以帮助我们理解其工作原理。实现通常,框框架我们从常见的用源原理僵尸 约会 atv 源码项目 XML 配置文件入手,这些文件包含了 JSF 框架的码解基本设置。让我们以地址服务的实现 jsf-provider.xml 文件为例,进行详细的框框架解析。
在 JSF 的用源原理配置文件中,虽然没有直接显示注册中心的码解内容,但作为自研的实现高性能 RPC 调用框架,高可用的框框架注册中心是其核心功能之一。因此,用源原理我们接下来将探索如何在没有提供注册中心地址的码解情况下,这些标签是如何完成服务的注册和订阅的。
### 配置解析
首先,我们发现配置文件中自定义的 xsd 文件,通过 NamespaceUri 链接到 jsf.jd.com/schema/jsf/j...。随后,基于 SPI(Service Provider Interface)机制,我们在 META-INF 中找到了定义好的 Spring.handlers 文件和 Spring.schemas 文件,这两个文件分别用于配置解析器和 xsd 文件的具体路径。
进一步地,我们查询了继承自 NamespaceHandlerSupport 或实现 NamespaceHandler 接口的类。在 JSF 框架中,JSFNamespaceHandler 通过继承 NamespaceHandlerSupport 实现了对自定义命名空间的解析功能。NamespaceHandler 的主要作用是解析我们自定义的 JSF 命名空间,通过 BeanDefinitionParser 对特定标签进行处理,完成对 XML 中配置信息的vr 直播 源码具体处理。
### 服务暴露
最终,通过 JSFBeanDefinitionParser 实现了 org.springframework.beans.factory.xml.BeanDefinitionParser,完成 XML 配置的解析。解析的结果会注册到 BeanDefinitionRegistry 对象中,进而触发 Bean 的初始化过程。最终,ProviderBean 实例监听上下文事件,在容器初始化完毕后,调用 export() 方法进行服务的暴露。
### 服务注册与暴露
服务暴露的实现逻辑集中在 ProviderConfig#doExport 方法中。首先,方法会对配置进行基本校验和拦截。随后,获取所有 RegistryConfig,如果获取不到注册中心地址,将使用默认的注册中心地址:“i.jsf.jd.com”。接着,根据 Provider 配置中的 server 相关信息启动 server,并使用默认序列化方式(如 msgpack)进行服务编码。然后,通过 ServerFactory 初始化并启动 Server,调用 ServerTransportFactory 生成对应的传输层,实现与注册中心的通信。最后,服务注册通过 JSFRegistry 类完成,该类连接注册中心,如果没有可用的中心,则使用本地文件并开启守护线程,使用两个线程池进行心跳检测、积分营销源码重试机制和连接状态监控。至此,服务从配置装配到服务暴露的过程完成。
### 消费者配置与初始化
对于消费者端(jsf-consumer.xml),注册中心地址(如“i.jsf.jd.com”)被配置在其中,而 Provider 的配置则在 jsf-provider.xml 中。配置解析过程与 Provider 类似,最终解析为 ConsumerConfig 和 RegistryConfig。通过 ConsumerBean 类实现 FactoryBean 接口,以便通过 getObject() 方法获取代理对象,完成客户端的初始化。在这个过程中,消费者会根据配置订阅相关的 Provider 服务。核心代码在 ConsumerConfig#refer 方法中,该方法通过调用子类的 subscribe() 方法开始订阅过程,连接 Provider 服务。
### 框架流程概述
综上所述,JSF 框架通过 Provider、Consumer 和注册中心(Registry)之间的协同工作,实现了高效的服务注册、订阅和通信。具体流程包括:
1. **Provider 端**:启动服务向注册中心注册,并根据配置初始化相关组件。
2. **Consumer 端**:首次获取实体信息时,通过 FactoryBean 接口获取代理对象,完成初始化并订阅 Provider 服务。
3. **注册中心**:提供异步通知机制,监控服务状态变化。
4. **服务调用**:直接调用服务方法。天池大赛 源码
5. **监控与治理**:框架内置监控机制,支持服务治理和降级容灾策略。
了解这一过程对于深入理解 JSF 框架的内部机制至关重要,也为后续的模块分析和系统优化提供了基础。
主机安全技术剖析-关于Windows RPC挖掘的那些事
本文深入探讨了如何利用Windows中的远程过程调用(RPC)机制,挖掘出系统中存在的未修复和改进的潜在漏洞,以实现本地提权。文章首先介绍了Windows提权系列的背景,指出了除了传统的绕过用户账户控制(UAC)和利用内核漏洞外,还有许多其他实现本地提权的手段。接着,文章详细阐述了如何通过模糊测试(Fuzzing)技术,利用RPC服务器中的漏洞来挖掘出这些潜在的安全隐患。
文章提供了两个利用RPC提权漏洞的实例,并分享了实现这些实例的工具和方法。首先,介绍了如何选择和使用模糊测试工具,如Impacket库,来探索和尝试未记录的RPC接口。接着,文章深入讲解了如何使用RpcView工具枚举RPC服务器,并通过下载Windows SDK中的symchk.exe工具,来配置RpcView以解析函数名称。这一步骤对于理解RPC通信过程至关重要。
文章进一步解释了如何利用PetitPotam工具,通过构建RPC接口和利用特定的RPC服务接口(如EFSRPC和LSARPC),实现本地提权。通过反编译接口为IDL文件,生成头文件和源代码,源码安装wamp实现自定义RPC客户端。文章还展示了通过构造特定的UNC路径来欺骗特权进程访问恶意管道,进而实现提权的过程。
最后,文章分享了两个具体的本地提权实例,一个是通过诊断跟踪服务(DiagTrack)中的RPC接口(UtcApi_StartCustomTrace)实现的提权,另一个是利用AzureAttestService服务中的RPC接口。文章强调了如何通过利用这些服务的RPC接口,构造特定的输入来触发提权过程,并最终实现本地用户权限的提升。
本文通过实例和工具介绍,提供了深入的理论和技术细节,旨在帮助安全研究者和系统管理员了解如何利用Windows RPC机制进行本地提权,同时强调了及时修复和更新系统的重要性,以防止此类安全风险的利用。
Dubbo—SPI及自适应扩展原理
引言:Dubbo作为一个广泛应用于国内的RPC框架,其设计思想极具学习价值。本文基于Dubbo2.5.3版本源码,深入探讨SPI(Service Provider Interface)及自适应扩展原理,解析Dubbo的高扩展性实现基础。
一、SPI(Service Provider Interface)简介:SPI是一种服务发现机制,旨在解耦接口与具体实现,允许第三方组件无缝集成至应用中。举例说明,Java内置SPI机制,如数据库驱动实现,通过Driver接口统一,各数据库厂商自定义驱动类即可实现连接不同数据库,无需修改代码。
二、Java SPI与Dubbo SPI对比:Dubbo基于Java SPI思想,提供更强大扩展能力。配置文件以接口全类名命名,内容非Java SPI标准形式。下面以Protocol扩展为例解析。
三、Dubbo SPI实现细节:核心类ExtensionLoader负责SPI管理。构造方法初始化loader,通过类名获取扩展类实例。关键点在于getExtension方法,内部实现从缓存获取或创建并缓存扩展类实例。loadExtensionClasses方法负责加载配置文件,解析实现类信息。
四、自适应扩展机制解析:Dubbo中存在大量扩展类,自适应机制确保按需加载。@Adaptive注解用于标识可动态加载的扩展类。构造方法中获取适配类,通过反射实例化。自适应类通过反射调用扩展类方法,实现懒加载功能。
五、Dubbo IOC解析:injectExtension方法实现依赖注入,通过反射和setter方法注入扩展实例。AdaptiveExtensionFactory适配类负责缓存所有ExtensionFactory,确保按需加载。本文详细解析Dubbo依赖注入实现原理。
六、总结:通过源码分析,可深入了解Dubbo扩展机制、设计模式应用以及如何实现优雅的扩展开发。未来在实际项目中,可灵活应用所学知识进行自定义扩展,甚至重构已有项目。反思当前项目,是否能利用今日所学进行优化和改进。
一文读懂,硬核 Apache DolphinScheduler3.0 源码解析
这篇文章深入解析了硬核Apache DolphinScheduler 3.0的源码设计和策略,让我们一窥其背后的分布式系统架构和容错机制。首先,DolphinScheduler采用去中心化设计,通过Master/Worker角色注册到Zookeeper,实现无中心的集群管理。API接口提供丰富的调度操作,MasterServer负责任务分发和监控,而WorkerServer负责任务执行和日志服务。
容错机制是系统的关键,包括服务宕机容错和任务重试。服务宕机时,MasterServer通过ZooKeeper的Watcher机制进行容错处理,重新提交任务。任务失败则会根据配置进行重试,直至达到最大次数或成功。远程日志访问通过RPC实现,保持系统的轻量化特性。
源码分析部分详细介绍了工程模块、配置文件、API接口以及Quartz框架的运用。Master的启动流程涉及Quartz的调度逻辑,Worker则负责执行任务并接收Master的命令。Master与Worker之间通过Netty进行RPC通信,实现了负载均衡和任务分发。
加入社区讨论,作者鼓励大家参与DolphinScheduler的开源社区,通过贡献代码、文档或提出问题来共同提升平台。无论是新手还是经验丰富的开发者,开源世界都欢迎你的参与,为中国的开源事业贡献力量。
TPRC-cpp 发送包流程剖析
TRPC官网对客户端发送包的流程有简要描述,但细节不够清晰。以下将通过分析Hello World示例中的源代码,来详细解析发送流程,不做深入分析,主要目的是梳理流程。
一、官网描述
二、源代码追踪
客户端代码位于TRPC-CPP/examples/helloworld/test/ fiber_client.cc文件中,核心代码如下:
1、解析文件获取配置信息
对应函数为ParseClientConfig,配置信息主要分为三种:
2、RunInTrpcRuntime
主要完成的是日志初始化以及执行FiberRuntime程序,对应代码如下:
3、RunInFiberRuntime
主要做的工作就是初始化框架运行环境InitFrameworkRuntime以及开启协程进行插件初始化以及传入的Run函数执行。
InitFrameworkRuntime主要代码如下,主要完成的工作是设定运行环境类型(使用Fiber)、内存池创建、时间轮创建并开启、初始化Fiber环境(fiber调度组的初始化并启动协程模型)、配置调度组对应的Reactor。
RegisterPlugins主要代码如下,主要完成的就是Naming、Tracing、Loging、Codec等等插件的注册、初始化以及开启运行。
4、请求构建与发送
status = func();调用main函数中传入的Run函数,请求构建与发送,代码如下:
核心在于调用proxy->SayHello进行请求的发送,那么我们就再深入一层
原来是调用了UnaryInvoke函数,那么continue
这部分代码是在ServiceProxy中,也就对应的官网的流程,这部分主要将请求写入上下文对象中,并且运行过滤器(这里其实就是文档中所说的过滤器埋点,究其原理其实就是运行已注册再当前埋点的函数),然后调用了UnaryInvokeImp,继续追踪~~~
这部分代码将所使用的协议写入了上下文对象,然后又调用了ServiceProxy::UnaryInvoke,Come on !
同样此函数首先执行了过滤器(埋点是CLIENT_PRE_SEND_MSG),然后又调用了UnaryTransportInvoke,在已知传输数据、传输协议的情况下,进行下一步^_^
使用之前已经注册的codec编码器对请求内容进行编码与请求头封装,进入codec_->ZeroCopyEncode,编码完成后使用transport对象进行发送与接收transport_->SendRecv
通过目标IP地址以及端口寻找到对应的FiberConnectorGroup组,通过调用组的SendRecv,进行发送
获取connection对象(可深入追踪,分为短链接和长连接连接池复用),获取成功调用SendReqMsg进行发送
首先进行了用户过滤器判定,有的话进行用户过滤器调用,后面进行IoMessage信息封装,调用Send进行信息发送
状态判定居多,核心在于FlushWritingBuffer函数
同样进行了处理,核心在于FlushTo
其他复杂的处理暂时不关注,这里发送的核心函数是io->Writev
到此,调用系统调用将信息写入Fd,即发出完成。
整个过程确实比较长,一层有一层的嵌套封装,进而实现解耦,这里其实并不仅仅是发送,也有接收,最开始的UnaryInvoke>(context, request, response);函数已经将response以指针的形式传递进取,后续发送数据并收到对方发来的数据是,进行层层赋值,最终得到了我们接收到的返回信息。
发送信息层层函数递进,接收信息层层函数退出。
大概就是这样,下面去看下tcp连接池的设计~~~~。