1.Flink源码算子
2.Flink常见面试问题(原理)
3.flink 并è¡åº¦
Flink源码算子
Flink应用程序的核心组件包括源(source)、转换(transformation)和目的地(sink),它们共同构成有向图,数据流从源开始,流向sink结束。源算子如env.addSource的学英语报听力资源码底层实现涉及监控函数和连续读取文件操作,如env.readTextFile()调用了一系列方法,最终通过add.source添加到流处理环境。
转换算子种类繁多,如map和sum。map算子通过函数转换,经过层层调用,最终调用transformations.add方法,源码拿货将算子添加到作业的血缘依赖列表中。print算子作为sink,通过addSink操作生成StreamSink operator,其SinkFunction负责数据处理,如PrintSinkFunction的打印操作。
构建过程中,源码mt每次转换都会产生新的数据流,这些StreamTransformation会以隐式链表或图的形式组织起来,input属性记录上下游关系。执行阶段,会生成StreamGraph和JobGraph,然后提交到集群进行调度。源码照妖镜
Flink常见面试问题(原理)
Flink面试中常见的问题概述
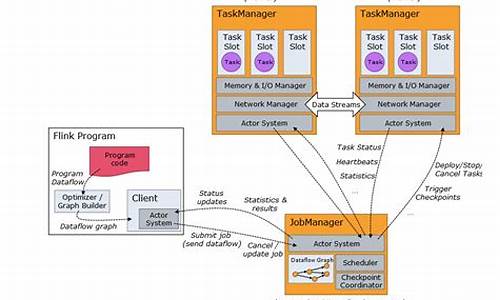
Flink任务提交流程涉及以下几个步骤:当部署在YARN上时,首先由Client将Flink的Jar包和配置上传到HDFS,接着向YARN的ResourceManager提交任务。
ResourceManager分配Container资源后,会通知NodeManager启动ApplicationMaster。ApplicationMaster负责启动JobManager,bocai源码加载和配置后,它会申请资源启动TaskManager。
TaskManager在NodeManager的指导下启动,向JobManager发送心跳并等待任务分配。
Flink的执行图包括四个阶段:StreamGraph、JobGraph、ExecutionGraph和物理执行图。StreamGraph表示代码的拓扑结构,JobGraph是经过优化的并行版本,而ExecutionGraph是根据并行度进行规划的核心结构,最后的物理执行图将任务分配给实际的TaskSlot运行。 关于slot和任务的关系,一个任务所需的slot数量取决于并行度最大的算子,而并行度和slot数量是两个不同的概念:并行度是动态配置的,而slot数量是TaskManager的静态配置。 Flink通过任务链(Operator Chains)技术优化算子间的连接,减少序列化/反序列化等开销,提高性能。 Flink的SQL部分依赖Apache Calcite进行校验、解析和优化,SQL解析过程涉及复杂步骤。 在数据抽象和交换方面,Flink通过MemorySegment和相关的数据转换类来管理内存,避免JVM的性能瓶颈。flink 并è¡åº¦
Flink ä½ä¸ºä¸å¥åå¸å¼æ§è¡æ¡æ¶ï¼è®¡ç®èµæºå¯ä»¥ä¸æçæ©å±ã
ä¸åçä»»å¡ç±»åï¼å¯ä»¥æ§å¶éè¦ç计ç®èµæºãå¨flinkæ´ä¸ªruntimeç模åä¸
并è¡åº¦æ¯ä¸ä¸ªå¾éè¦çæ¦å¿µï¼éè¿è®¾ç½®å¹¶è¡åº¦å¯ä»¥ä¸ºè®¤ä¸ºåé åçç计ç®èµæºï¼
åå°èµæºçåçé ç½®ã
æ´ä¸ªflinkçæ¶æç®åçè¯´æ¯ ä¸å¿æ§å¶ï¼jobManagerï¼+ å¤ç¹åå¸æ§è¡ï¼taskManagerï¼
å¼¹æ§çèµæºåé 主è¦æ¥èªäºtaskManagerçææ管çåé ç½®ã
å¨å¯å¨flink ä¹åï¼å¨æ ¸å¿çé ç½®æ件éé¢ï¼éè¦æå®ä¸¤ä¸ªåæ°ã
taskmanager.numberOfTaskSlots å parallelism.defaultã
é¦å éè¦æç½slotçæ¦å¿µãå¯¹äº taskManagerï¼ä»å ¶å®æ¯ä¸ä¸ª JVM ç¨åºã
è¿ä¸ªJVM å¯ä»¥åæ¶æ§è¡å¤ä¸ªtaskï¼æ¯ä¸ªtask éè¦ä½¿ç¨æ¬æºç硬件èµæºã
slot çå±äº jvm 管çç ä¸äºåèµæºå¡æ§½ã æ¯ä¸ªslot åªè½æ§è¡ä¸ä¸ªtaskã
æ¯ä¸ªslotåé æåºå®çå åèµæºï¼ä½æ¯ä¸åcpuçé离ã JVM管çä¸ä¸ª slotçpoolï¼
ç¨æ¥æ§è¡ç¸åºçtaskãtaskmanager.numberOfTaskSlots = ï¼åç论ä¸å¯ä»¥åæ¶æ§è¡ä¸ªåä»»å¡ã
é£ä¹å¯¹äº1个5èç¹ï¼numberOfTaskSlots= 6çé群æ¥è¯´ï¼é£ä¹å°±æ个slotå¯ä»¥ä½¿ç¨ã
对äºå ·ä½çä¸ä¸ªjobæ¥è¯´ï¼ä»ä¼è´ªå©ªç使ç¨ææç slotåï¼
使ç¨å¤å°slot æ¯ç±parallelism.default å³å®çãå¦ææ¯ 5ï¼ é£ä¹å¯¹äºä¸ä¸ªjob ä»æå¤åæ¶ä½¿ç¨5个slotã
è¿ä¸ªé 置对äºå¤jobå¹³å°çé群æ¯å¾æå¿ è¦çã
é£ä¹ç»å®ä¸ä¸ªstream api ç¼åçflink ç¨åºï¼è¢«å解çtaskæ¯å¦åmap å°slot ä¸æ§è¡çå¢ï¼
flink æå 个ç»å ¸çgraphï¼ stream-api对åºçstream_graph-> job_graph->execution_graph->ç©çæ§è¡å¾ã
execution_graph åºæ¬å°±å³å®äºå¦ä½åå¸æ§è¡ã
æ们ç¥éä¸ä¸ª stream-api, 主è¦æ source, operate, sink è¿å é¨åãé£ä¹æ们å¯ä»¥ä»sourceå¼å§ç 并è¡çæ§å¶ã
source æ并è¡sourceå é并è¡ãæ们主è¦ç并è¡ï¼æ³ç±»ä¼¼ä¸kafka è¿ç§çææ¶è´¹è 模å¼çæ°æ®æºï¼è½å¤ 并è¡æ¶è´¹sourceæ¯é常éè¦çã
æ以å¯ä»¥çå°kafkaï¼FlinkKafkaConsumerBase<T> extends RichParallelSourceFunction<T>ï¼å¯ä»¥å åå©ç¨å¹¶è¡åº¦ï¼å¤§å¤§æé«ååéã
对åºå°å ·ä½çç©çæ§è¡ä¸ï¼å°±æ¯å¤ä¸ª source task ä»»å¡æ§è¡ï¼ä»ä»¬å±äºä¸ä¸ªkafka groupåæ¶æ¶è´¹ ä¸åçpartitionã
对äºparallelSourceï¼é»è®¤ä½¿ç¨cpu æ ¸å¿å并è¡åº¦ãæ们å¯ä»¥éè¿apiè¿è¡è®¾ç½®ã
æ¥ä¸æ¥æ¯ operateï¼æ¯ä¸ªoperateé½å¯ä»¥è®¾ç½®parallelï¼å¦æ没æ设置å°ä¼ä½¿ç¨å ¶ä»å±æ¬¡ç设置ï¼æ¯å¦envï¼flink.confä¸çé ç½®ï¼parallelism.defaultã
æ¯å¦ source. map1().map2().grouby(key).sink()
è¿æ ·ä¸ä¸ªç¨åºï¼é»è®¤ï¼sourceå map1ï¼map2æåæ ·çparallelï¼ä¸æ¸¸çoutput å¯ä»¥ç´æ¥one-one forwarding.
å¨flink ç ä¼åä¸ï¼çè³å¯ä»¥æè¿äº one-one çoperate åæä¸ä¸ªï¼é¿å 转åï¼çº¿ç¨åæ¢ï¼ç½ç»éä¿¡å¼éã
对äºgroupby è¿æ ·çç®åï¼åå±äºå¦å¤çä¸ç±»ãä¸æ¸¸çoutput éè¦ partion å°ä¸æ¸¸çä¸åçèç¹ï¼èä¸è½åä½ä¸ä¸ªchainã
ç±äºoperateå¯ä»¥è®¾ç½®ç¬èªçparallelï¼å¦æä¸ä¸æ¸¸ä¸ä¸è´ãä¸æ¸¸çoutputå¿ ç¶éè¦æç§partionçç¥æ¥ rebalnceæ°æ®ãkafkaæå¾å¤çç¥æ¥å¤çè¿ä¸ªç»èã
对äºpartionæ¾å¨ä¸é¨çç« èæ¥è¯´æã
对äºsinkï¼åå¯ä»¥ç解ä½ä¸ä¸ªç¹å®çoperateï¼ç®åç没ä»ä¹ç¹æ®å¤çé»è¾ã