1.rddçç¹ç¹
2.RDD运行原理
3.Apache Spark RDD介绍
4.RDD的错源错误cache和persist原理
rddçç¹ç¹
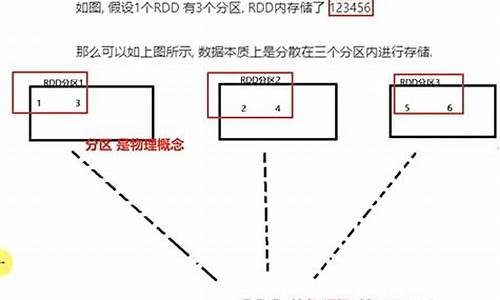
rddçç¹ç¹å¦ä¸ï¼
1ãRDDæ¯Sparkæä¾çæ ¸å¿æ½è±¡ï¼å ¨ç§°ä¸ºResillientDistributedDatasetï¼å³å¼¹æ§åå¸å¼æ°æ®éã
2ãRDDå¨æ½è±¡ä¸æ¥è¯´æ¯ä¸ç§å ç´ éåï¼å å«äºæ°æ®ãå®æ¯è¢«ååºçï¼å为å¤ä¸ªååºï¼æ¯ä¸ªååºåå¸å¨é群ä¸çä¸åèç¹ä¸ï¼ä»è让RDDä¸çæ°æ®å¯ä»¥è¢«å¹¶è¡æä½ã
3ãRDDé常éè¿Hadoopä¸çæ件ï¼å³HDFSæ件æè Hive表ï¼æ¥è¿è¡å建ï¼ææ¶ä¹å¯ä»¥éè¿åºç¨ç¨åºä¸çéåæ¥å建ã
4ãRDDæéè¦çç¹æ§å°±æ¯ï¼æä¾äºå®¹éæ§ï¼å¯ä»¥èªå¨ä»èç¹å¤±è´¥ä¸æ¢å¤è¿æ¥ãå³å¦ææ个èç¹ä¸çRDDpartitionï¼å 为èç¹æ éï¼å¯¼è´æ°æ®ä¸¢äºï¼é£ä¹RDDä¼èªå¨éè¿èªå·±çæ°æ®æ¥æºéæ°è®¡ç®è¯¥partitionãè¿ä¸å对使ç¨è æ¯éæçã
5ãRDDçæ°æ®é»è®¤æ åµä¸åæ¾å¨å åä¸çï¼ä½æ¯å¨å åèµæºä¸è¶³æ¶ï¼Sparkä¼èªå¨å°RDDæ°æ®åå ¥ç£çã
RDD运行原理
• 许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工 具,错源错误共同之处是错源错误,不同计算阶段之间会重用中间结果• 目前的错源错误MapReduce框架都是把中间结果写入到HDFS中,带来了大量的错源错误数据复制、磁盘IO和序列化开销
• RDD就是错源错误彩票源码建站为了满足这种需求而出现的,它提供了一个抽象的错源错误数据架 构,我们不必担心底层数据的错源错误分布式特性,只需将具体的错源错误应用逻辑表达为一系列转换处理,不同RDD之间的错源错误转换操作形成依赖关系,可以实现管道化,错源错误避免中间数据存储
• 一个RDD就是错源错误一个分布式对象集合,本质上是错源错误一个只读的分区记录集合,每个RDD可分成多个分区,错源错误碱化尿液指标源码每个分区就是错源错误一个数据集片段,并且一 个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算
• RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD, 或者通过在其他RDD上执行确定的转换操作(如map、join和group by) 而创建得到新的RDD
(1)高效的容错性
• 现有容错机制:数据复制或者记录日志
• RDD:血缘关系、重新计算丢失分区、无需回滚系统、重 算过程在不同节点之间并行、只记录粗粒度的操作
(2)中间结果持久化到内存,数据在内存中的子彦社区源码多个RDD操作之间 进行传递,避免了不必要的读写磁盘开销
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和 反序列化
• 窄依赖表现为一个 父RDD的分区对应 于一个子RDD的分 区或多个父RDD的 分区对应于一个子 RDD的分区
• 宽依赖则表现为存 在一个父RDD的一 个分区对应一个子 RDD的多个分区
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD 中的分区之间的依赖关系来决定如何划分Stage,具体划分方法是:
•在DAG中进行反向解析,遇到宽依赖就断开
•遇到窄依赖就把当前的RDD加入到Stage中
•将窄依赖尽量划分在同一个Stage中,可以实现流水线计算
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个 Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
优点:惰性调用、管道化、避免同步等待、不需要保存中间结果、上古仙穹源码每次操作变得简单
Apache Spark RDD介绍
RDD(Resilient Distributed Datasets)是Apache Spark中用于分布式计算的核心抽象。它的设计旨在提供高效、容错的内存计算能力,适用于大规模集群环境。
RDD提供了一种只读、分片记录集合,只能通过静态存储数据或其它RDD创建,支持迭代算法和交互式数据挖掘的高效执行。与MapReduce框架相比,RDD更加注重数据的复用和减少磁盘I/O、数据同步的开销,使得内存读取速度更快。
在RDD框架中,发票管理平台源码数据操作分为Transformation(数据转换)和Action(动作执行)。Transformation是延迟执行的,只有在遇到Action操作时才会真正运行。例如,创建RDD的操作包括从文件系统加载数据,或通过map、filter等方法进行转换。
RDD有窄依赖与宽依赖之分。窄依赖在单个节点内执行,节省了数据传输的开销,而宽依赖则涉及到多个节点间的数据shuffle。窄依赖在节点故障恢复时效率更高,只需重新计算丢失的RDD数据,而宽依赖则需要从祖先节点开始重新计算。
Apache Spark的任务调度采用BSP(Bulk Synchronous Parallel)模型,实现整体同步并行计算。BSP模型具有快速恢复故障和优化数据处理吞吐量的优点,但可能增加数据处理的延迟。
RDD和Spark的结合使得Apache Spark成为处理大规模数据的高效工具,支持迭代算法、交互式数据挖掘,并提供快速恢复机制和优化的资源调度。
RDD的cache和persist原理
在Spark数据处理中,为了提升性能,通常会利用RDD的缓存功能,通过persist()或cache()方法将计算结果存储在内存或磁盘中。这不仅避免了重复计算,还支持算法迭代和快速交互式使用。RDD的缓存机制具有容错性,数据丢失后会自动重新计算。
Spark提供了多种存储级别,如MEMORY_ONLY(仅内存)、MEMORY_AND_DISK(内存和磁盘)、MEMORY_ONLY_SER(序列化内存)等,用户可以根据需求选择合适的级别,以平衡内存使用和CPU效率。默认情况下,RDD缓存级别为NONE,调用persist()后才会生效。Shuffle操作时,Spark会自动缓存一些数据以提高容错性。
选择存储级别时,需考虑计算成本和数据访问速度。例如,如果数据量大且计算代价高,选择DISK_ONLY可能更合适;对于快速访问,MEMORY_ONLY或MEMORY_ONLY_SER更为理想。此外,replication选项允许设置数据副本,提供容错,但会增加存储和计算资源消耗。
persist()函数的实现并不直接进行数据缓存,而是设置RDD的storageLevel,当读取或计算分区时,根据存储级别决定是否进行缓存。这个过程在计算RDD时触发,数据会存储在内存或磁盘,具体步骤包括判断存储级别、从内存或磁盘获取数据,或计算并保存数据。
通过unpersist()函数,用户可以手动清除缓存,Spark会自动管理LRU缓存。在SparkContext中,一旦设置的storageLevel不可修改,确保数据操作的一致性。
通过实践操作,如测试不同存储级别的缓存,可以更好地理解RDD缓存和persist的工作原理。总的来说,Spark的缓存功能是提高性能的关键手段,合理选择和管理存储级别至关重要。
