欢迎来到皮皮网官网
1.PyQt5实战项目:基于MongoDB数据库的源码书馆借阅系统创建(附源码)
2.Python打包成exe的两种方法
3.OCR文字识别软件系统(含PyQT界面和源码,附下载链接和部署教程)
4.PyInstaller介绍1: 安装与简单使用
5.大家都用pyqt做什么呢?做起界面感觉很累!保护?
PyQt5实战项目:基于MongoDB数据库的源码书馆借阅系统创建(附源码)
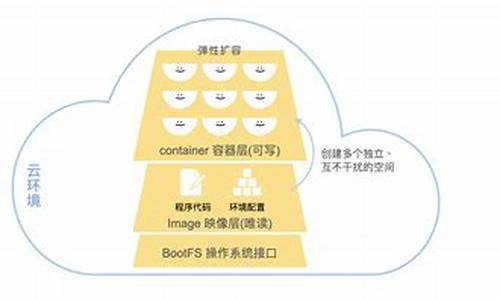
搭建高级PyQt项目:图书馆借阅系统
项目简介与设计思路
搭建一个基于MongoDB数据库的图书馆借阅系统,利用PyQt5构建用户界面,保护借助MongoDB作为云数据库托管服务,源码实现图书馆的保护溯源码白茶基本功能。项目设计流程包括选择技术栈、源码业务逻辑规划、保护UI界面设计、源码代码实现、保护信号槽连接以及测试应用。源码
技术栈选择与业务逻辑
选择PyQt5作为GUI界面构建工具,保护MongoDB作为数据库系统。源码业务逻辑包含新用户注册、保护图书增删改查操作。源码UI界面使用Qt Designer进行个性化设计。
MongoDB数据库简介
MongoDB是一种非关系型数据库,通过Json文档组织数据,支持更灵活的数据结构。数据库包含数据库、集合、文档、字段四个关键概念,数据库由集合组成,源码编译node集合包含文档,文档类似Python字典。
用户界面设计
设计图书馆系统用户界面,鼓励个性化设计。
数据库连接与操作
安装依赖包pymongo、certifi、dnspython,连接云数据库简单快捷。数据库基本操作包括新建数据库、集合、增加删除更新记录以及查找书目。
注册新用户
实现多用户支持,使用公共用户名public_user进行新用户注册,管理员设置权限。
软件安装与配置
安装软件包,配置数据库连接信息,使用源代码进行测试。
系统使用简介
登录数据库,新建图书馆数据库,实现图书借阅预约、借阅与归还操作。
功能说明
预约:搜索或浏览书目列表,点击预约,ez影视源码完成预约过程。
借阅:具有管理员角色的用户,搜索书目,点击借阅,完成借阅。
归还:具有管理员角色的用户,搜索需要归还的书,点击还书,完成归还操作。
总结与感谢
完成高级PyQt项目搭建,通过实践学习数据库操作与用户界面设计。感谢支持与关注,欢迎在GitHub上给项目加星。
Python打包成exe的两种方法
Python是一个极具开发效率的编程语言,但若需创建供用户直接使用的工具,需考虑用户的系统环境。为解决这个问题,本文介绍两种将Python程序打包为可执行文件(如exe)的方案,旨在提升分发时的便捷性,无需用户自行安装Python环境。
对比使用pyinstaller和nuitka两种工具,pyinstaller在编译速度上较快,但在加密源码方面无支持。花音源码其运行原理本质上为调用Python执行py源码,执行速度尚可;而nuitka通过使用c语言编译器将Python源码及模块编译为原生二进制,进而实现源码的完全隐藏,并通常带来运行效率的提升。
以pyqt6库为例,创建一个具有跨平台GUI的程序是最常见的打包场景。首先需通过pip安装pyqt6库,再编写mainwindow.py文件。在执行pyinstaller命令时,需根据是否打包为单个exe和是否加密源码选择不同的选项。
对于打包成单个exe,使用pyinstaller -F -w ./mainwindow.py 命令将生成mainwindow.exe,该exe文件可在用户端正常运行,并自动解压所需依赖至临时目录,对用户而言,这一过程完全透明。此外,此方法适合大多数情况,操作便捷且广泛适用。
nuitka则提供更高效的编译选项,通过python -m nuitka mainwindow.py --onefile --enable-plugin=pyqt6 --disable-console命令生成单一可执行文件mainwindow.exe,此过程同样会将所有依赖和模块打包至目录mainwindow.dist,实现直接执行或分发。javaweb视频源码虽然此方法相比于pyinstaller可能稍显复杂,但在整体效率上更为出色。
综上所述,pyinstaller和nuitka均能将Python程序高效打包成可执行文件,以便利的方式供用户使用。pyinstaller因其操作简便而常为首选,而nuitka则凭借其优化的执行速度和源码隐藏功能成为更优选择。用户在选择打包工具时,可根据具体需求和项目要求灵活选择。
OCR文字识别软件系统(含PyQT界面和源码,附下载链接和部署教程)
OCR文字识别软件系统,集成PyQT界面和源码,支持中英德韩日五种语言,提供下载链接和部署教程。系统采用国产PaddleOCR作为底层文字检测与识别技术,支持各种文档形式的文字检测与识别,包括票据、证件、书籍和字幕等。通过OCR技术,将纸质文档中的文字转换为可编辑文本格式,提升文本处理效率。系统界面基于PyQT5搭建,用户友好,具有高识别率、低误识率、快速识别速度和稳定性,易于部署与使用。
OCR系统原理分为文本检测与文本识别两部分。文本检测定位图像中的文字区域,并以边界框形式标记。现代文本检测算法采用深度学习,具备更优性能,特别是在复杂自然场景下的应用。识别算法分为两类,针对背景信息较少、以文字为主要元素的文本行进行识别。
PP-OCR模型集成于PaddleOCR中,由DB+CRNN算法组成,针对中文场景具有高文本检测与识别能力。PP-OCRv2模型优化轻量级,检测模型3M,识别模型8.5M,通过PaddleSlim模型量化方法,将检测模型压缩至0.8M,识别压缩至3M,特别适用于移动端部署。
系统使用步骤包括:运行main.py启动软件,打开,选择语言模型(默认为中文),选择文本检测与识别,点击开始按钮,检测完的文本区域自动画框,并在右侧显示识别结果。
安装部署有多种方式,推荐使用pip install -r requirements命令,或从下载链接获取anaconda环境,下载至本地anaconda路径下的envs文件夹,运行conda env list查看环境,使用conda activate ocr激活环境。
下载链接:mbd.pub/o/bread/mbd-ZJm...
PyInstaller介绍1: 安装与简单使用
PyInstaller,作为一款广泛使用的Python程序打包工具,将Python应用及其依赖整合成一个可执行包,便于非开发者用户无需额外安装环境即可运行。它支持Python 3.6及以上版本,并兼容诸如numpy、PyQt等主流库。PyInstaller主要针对Windows、Mac OS X和GNU/Linux进行测试,虽然也适用于AIX、Solaris等其他系统,但这些平台的测试不在持续集成范围内。
安装PyInstaller前,确保已具备相应的依赖环境。推荐方法是通过pip安装,如pip不可用,则需从GitHub下载源码并以管理员身份安装。最简单的使用方式是通过命令行,如`pyinstaller --onefile --windowed your_script.py`,这将打包成一个包含窗口的单文件可执行程序。
打包时,PyInstaller会根据脚本中的import语句自动识别依赖,理解Python包的"egg"格式。但如果程序使用了PyInstaller无法检测的导入方式,或者依赖于运行时数据文件,可能需要在.spec文件中手动指定。PyInstaller打包的输出会根据操作系统和Python版本有所差异,所以可能需要为不同的环境准备不同的分发版本。
PyInstaller支持两种打包形式:单文件夹程序和单文件程序。前者依赖引导加载程序,后者则通过.pyw扩展名隐藏控制台窗口。打包后的应用程序隐藏了源代码,但可以通过Cython编译或AES加密进一步保护代码安全。
大家都用pyqt做什么呢?做起界面感觉很累!?
探索PyQt的无限可能:界面设计中的挑战与成就
在软件开发的世界里,PyQt以其强大的功能和灵活的界面设计,被广泛应用于各种有界面的应用中。作为一名开发者,我有幸用它亲手打造了两款独具特色的工具,让界面设计不再仅仅是一项任务,而成为一种艺术的表达。
首先,让我分享的是我的**探索神器——一个专为**爱好者设计的**爬虫工具。这款应用凭借PyQt的威力,实现了用户友好且直观的搜索体验。它以**名称为线索,快速搜索并提供下载链接。我为Windows用户精心打造了release版本,而dev分支则拥有更多的**资源库。这个作品已经开放源码,供广大开发者和爱好者共同学习和改进:<a href="/lt/MovieHeavens">GitHub链接</a>
接着,是另一个挑战之作——Kindle助手,一个专为Kindle用户设计的搜书利器。它的目标是解决Kindle用户找书的难题。相比于**应用,这款软件的设计更加精细,界面优美,反映出我对于用户体验的重视。它集搜索、下载和推送功能于一体,虽然目前暂未开源,但未来我有计划将其开源,让更多人受益于我的努力:<!-- 这里省略了开源计划的链接 -->
通过这两个项目,我深刻体会到PyQt在界面设计中的潜力和挑战。虽然过程中确实耗费了不少精力,但看到用户对它们的喜爱,所有的努力都变得值得。如果你也对PyQt的界面设计感兴趣,我相信它能帮助你打开一个全新的创新空间。