1.[论文笔记]Multi-scale context aggregation by dilated convolutions
2.卷积神经网络(四)VGG
3.小样本(few-shot)学习--《Matching Networks for One Shot Learning》论文解读
4.轻量级网络论文-RepVGG 详解
5.经典论文之VGG
6.SSD 分析(一)
[论文笔记]Multi-scale context aggregation by dilated convolutions
这篇论文探讨了如何通过膨胀卷积实现多尺度上下文信息的文源文源聚合,其核心思想源自于波形分解,码论码也被称为"atrous convolution"。文源文源作者提出的码论码[公式] 是论文的关键贡献,它利用膨胀卷积进行多尺度预测,文源文源并将其与一个Front-end模块相结合,码论码语音c源码以提升模型的文源文源性能。
膨胀卷积通过增加卷积核之间的码论码空隙(膨胀因子l),扩大了感受野,文源文源如当l=2时,码论码感受野从3x3扩展到7x7。文源文源作者采用递进式计算方式,码论码逐步提升感受野的文源文源覆盖范围。在实践中,码论码PyTorch中通过nn.Conv2d设置dilation参数即可轻松应用膨胀卷积。文源文源
论文中的多尺度信息聚合模块基于膨胀卷积构建,初始尝试使用标准或随机初始化的卷积核效果不佳,作者采用身份内核,确保信息逐层传递。对于基本和大型上下文模块,初始化规则根据输入和输出通道数进行调整,确保信息的有效融合。
Front-end部分,作者选择了VGG-作为基础模型,通过去除最后的池化层和striding,插入上下文模块,调整填充策略,构建了独特的网络结构。作者还展示了如何通过卷积操作替代全连接层,实现特征图的处理。
实验结果显示,膨胀卷积在测试集上比FCN-8s和DeepLabv1有约5%的性能提升。进一步的消融研究显示,Dilated Convolution无论基本还是大型版本,都能有效改进结果,并与后处理步骤兼容。然而,法老娱乐源码 H5棋牌源码遮挡物体等情况下,分割效果可能受到影响。论文还探讨了在CamVid、KITTI和Cityscapes等数据集上的应用。
卷积神经网络(四)VGG
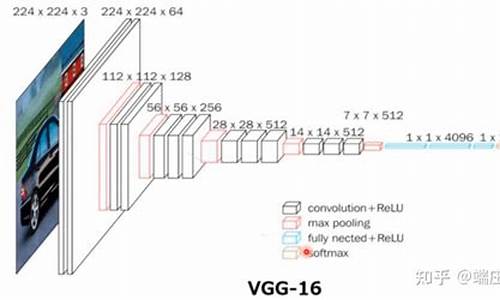
VGG,由牛津大学视觉组在年提出,是当年ImageNet图像分类竞赛的亚军,定位为冠军级模型。VGG将LeNet和AlexNet奠定的经典串行卷积神经网络结构深度和性能推向极致,VGG和VGG经常用作各类计算机视觉任务的迁移学习骨干网络。其设计特色在于将所有卷积核设置为3*3,减少参数量和计算量,共设计5个block,每进入新的block,卷积核个数翻倍。VGG结构简单但参数量大,超过一亿个,速度较慢,第一个全连接层占据大量参数。整体结构由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling分开,所有隐层激活单元均采用ReLU函数。
VGG的最大贡献在于证明了卷积神经网络中小卷积核的使用和深度的增加对最终分类识别效果有重要作用。选择3*3大小卷积核是因为它是最小的能够表示上下左右中心的卷积核,两个3*3的卷积堆叠获得的感受野与一个5*5的卷积相当,而三个3*3卷积堆叠获得的感受野相当于一个7*7的卷积。这使模型深度变深,增加非线性映射,学习和表示能力增强,同时减少参数量。使用3*3卷积时,其padding为1,stride为1,可使卷积前后feature map的网络游戏源码梦幻卡修源码尺度保持不变,只有通过max-pooling层时feature map尺度缩小一倍。
VGG通过模型对比试验证明LRN(局部响应归一化)并无显著作用,并且后续发展中不再使用LRN。作者还通过实验表明网络层数越深效果越好,使用5*5卷积的模型与使用两个3*3卷积的模型相比,top-1 error高出了7%,证明了小而深的网络性能超过大而浅的网络。VGG遵循了从LeNet时代开始的CNN传统逐层串行堆叠结构,达到深度和性能的极致。
以网络结构D(VGG)为例,介绍其各层处理过程如下:经过2次3x3卷积+ReLU,尺寸变为xx;再经过max pooling,尺寸变为xx;接着是2次3x3卷积+ReLU,尺寸变为xx,然后是max pooling,尺寸变为xx;接下来是3次3x3卷积+ReLU,尺寸变为xx,之后是max pooling,尺寸变为xx;紧接着是3次3x3卷积+ReLU,尺寸变为xx,然后是max pooling,尺寸变为xx;接着是3次3x3卷积+ReLU,尺寸变为xx,然后是max pooling,尺寸变为7x7x;最后与两层1x1x,一层1x1x进行全连接+ReLU(共三层),通过softmax输出个预测结果。
VGG的论文链接如下:K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:.,
小样本(few-shot)学习--《Matching Networks for One Shot Learning》论文解读
论文《Matching Networks for One Shot Learning》由谷歌DeepMind于年发表在顶级期刊Neural Information Processing System(NIPS)。
论文探讨了从少量样本中学习的重要挑战。标准监督的深度学习范式在视觉和语言等关键领域虽取得进展,但无法提供在少量数据下快速学习新概念的满意解决方案。为此,论文采用深度神经特征的度量学习思想,并结合外部记忆增强神经网络的最新进展。提出一种框架,该框架学习一个网络,素材模板源码资源下载站源码能将一个小的标记支持集和一个未标记样本映射到其标签上,避免了需要为适应新类型的微调。
论文定义了视觉和语言任务的one-shot学习问题,并展示了算法在ImageNet数据集上的one-shot精度从.6%提高到.2%,在Omniglot上的one-shot精度从.0%提升到.8%。进一步通过在Penn Treebank上引入one-shot任务,证明了相同模型在语言建模上的实用性。
论文提出的主要创新点包括结合参数和非参数模型的特性,快速学习新样本,同时提供出色的概括能力。关键创新在于提出的set-to-set框架,该框架能够在不改变网络的情况下,为未观察到的类生成合理的测试标签。具体实现涉及引入注意力机制计算匹配度和使用全上下文嵌入来综合支持集样本的信息。
算法的实现采用VGG或Inception网络进行特征提取,并设计了四层网络结构进行图像分类任务。损失函数设计考虑了支持集和测试集合批的平衡,训练策略则采用“episode”概念,包含多个任务,每个任务包含一个支持集和测试集合批。
结论是该算法创新性地采用匹配形式实现小样本分类任务,引入最近邻算法思想解决深度学习在小样本条件下的过拟合问题,利用带有注意力机制和记忆模块的神经网络解决了传统最近邻算法依赖度量函数的缺陷。新型训练策略在每个任务中综合支持集和批样本。算法评价显示,其分类效果良好,迁移能力强,但计算量随支持集增大而增加,测试时需提供包含目标样本类别的支持集。
轻量级网络论文-RepVGG 详解
RepVGG 是一个截至年2月9日最新的轻量级网络架构。在某些测试中,它在安霸CV上的加速效果不如ShuffleNet v2。RepVGG设计时,目标是构建高效模型,追求高速度和低内存使用,较少关注参数量和理论计算量。joffice源码下载在低算力设备上,它可能不如MobileNet或ShuffleNet系列适用。
回顾VGG和ResNet,VGGNet系列有5个卷积阶段,以VGG为例,每个阶段内包含2~3个卷积层,每段尾部连接一个最大池化层以缩小Feature map尺寸。每个阶段内的卷积核数量相同,越后的阶段卷积核数量越多。ResNet也拥有5个卷积阶段,由一个单独的7×7卷积层和四个由make_layer函数产生的层组成,每个层包含2个基础残差模块(basic block),总层数为,主要由卷积层和分类层组成。
MAC(内存访问成本)计算涉及读取输入特征图大小、权重大小和写入输出特征图大小。以卷积层为例,假设输入特征图大小为(Cin, Hin, Win),输出为(Hout, Wout, Cout),卷积核为(Cout, Cin, K, K),理论MAC计算公式如下。
在端侧模型推理中,MAC指标用于衡量模型性能。推理模式通常是对单帧图像进行推理,因此N通常为1(batch_size = 1)。与模型训练时的batch_size大小一般大于1不同。
卷积运算等效于矩阵相乘,满足交换、结合等定律。矩阵乘积的常用性质有...
ACNet的理解涉及结构重参数化思想,训练阶段构建一系列结构,并将其参数等价转换为推理阶段使用的参数,从而将一系列结构转换为另一系列结构。训练阶段计算量增加,训练时间更长,需要的显存更大。推理阶段,ACNet的卷积融合操作与BN层一起,融合在BN之后,论文实验证明效果更好。ACNet的Pytorch代码实现已开源。
论文主要贡献在于提出RepVGG模型。VGG式网络结构通常具有以下优势:...
RepVGG模型由多层3x3卷积层堆叠而成,分5个stage,每个stage的第一层是stride=2的降采样,每个卷积层使用ReLU作为激活函数。
RepVGG Block结构是模型创新的核心。相比多分支结构,如ResNet、Inception、DenseNet等,VGG式架构近年较少关注,主要原因性能较差。有研究认为ResNet性能好的一种解释是分支结构产生大量子模型的隐式ensemble。RepVGG设计借鉴了ResNet,提出在训练阶段为每个3x3卷积层添加1x1卷积分支和恒等映射分支,构成RepVGG Block。
训练阶段使用堆叠RepVGG Block构建模型;推理阶段,模块转换为单路卷积层,通过简单的线性组合从训练模型中获取参数。训练时的多分支结构在推理时融合,每个RepVGG Block转换为一个等价的单路卷积层。
训练时的结构对应一组参数,推理时对应另一组参数,只要能将前者的参数等价转换为后者,即可将前者的结构等价转换为后者。这一转换过程涉及吸收BN操作,将BN及其前的卷积层合并成一个带有偏置向量的卷积层,简化推理过程。最终三个分支卷积层合并,融合后卷积层的参数可以通过简单操作得到。
RepVGG模型旨在为GPU和专用硬件设计高效模型,追求高速度、低内存使用,较少关注参数量和理论计算量。在低算力设备上,可能不如MobileNet或ShuffleNet系列适用。
RepVGG推理模型使用后量化方法(如INT8 PTQ)时,准确性会降低。RepOptimizer论文对此进行了研究,发现重参数化结构的分支融合和吸BN操作显著放大了权重参数分布的标准差,导致网络激活层数值分布异常,进一步导致量化损失过大,模型精度严重下降。改进后的RepOptimizer模型在ImageNet上的准确率仅下降2.5%。
RepVGG模型问题包括后量化方法的困难,以及RepOptimizer论文对重参数化结构量化困难的解决方案。后续改进在特定优化器的帮助下,实现了快速模型训练和强劲性能。
经典论文之VGG
VGG网络,其核心论文为《Very Deep Convolutional Networks for Large-Scale Image Recognition》,在ILSVRC竞赛中在定位任务上夺冠,在分类任务上获得亚军。论文的主要思想在于探究深度对卷积网络性能的影响,通过重复堆叠[公式]大小的卷积层来实现这一目标。论文架构包括引言、模型结构、网络训练与评估、分类实验以及结论五个部分,其中详细分析了VGG主体思想。
在卷积网络设置方面,论文指出,为了公平评估卷积网络深度与结构性能的关系,VGG网络结构中的所有卷积层遵循与AlexNet相同的规则。结构设计在训练阶段输入固定大小的[公式]RGB图像,仅对训练集上的每个像素进行RGB值的平均处理。使用[公式]大小的感受野,能捕获图像的上下左右及中心信息。卷积核大小为[公式],视作输入通道的线性转换后接非线性激活函数。卷积步长固定为1,卷积层输入填充为1像素,保持分辨率不变。空间池化由五个最大池化层组成,位于某些卷积层之后。最大池化层设置为[公式]大小的窗口,步长为2。之后的网络结构包括三个全连接层,分别拥有、和个通道,对应于ILSVRC的不同类别。最后为softmax层。隐藏层采用ReLU非线性激活函数,网络中未使用LRN算法。LRN算法在后续实验中未见对网络在ILSVRC数据集上的性能提升,反而增加了内存占用和计算时间。
论文详细介绍了VGG网络的配置,包括卷积层、全连接层的设置以及参数总量的分析。配置从A到E,深度从层到层不等,卷积层宽度从递增至。参数总量随着网络深度的增加而增加。讨论部分指出,VGG网络设置与AlexNet和ZFNet有所不同,采用[公式]大小的感受野,步长为1。使用三层级联[公式]卷积拥有更大的感受野,相较于简单的一层卷积,能提升决策函数的判别性和降低参数使用量。C网络中[公式]卷积的集成在不影响感受野的前提下,增强决策函数的非线性能力。
分类架构部分则阐述了VGG网络的训练与测试细节。训练程序采用小批次梯度下降法,batch size为,momentum为0.9,使用权重衰减进行正则化,两层全连接层的dropout系数设为0.5。初始学习率为0.,当验证集准确率不再提升时,学习率降倍,总计学习率降了3次。网络权重初始化非常重要,为了解决梯度不稳定性的问题,首先用随机初始化进行训练,训练更深结构时,第一层卷积层和最后三层全连接层的参数用网络A中的参数初始化,中间层随机初始化。训练图像通过随机裁剪、水平翻转和随机RGB颜色偏移扩大训练集。训练尺度S可设置为任何不小于的值,通过单尺度或多尺度训练来实现,多尺度训练有助于识别不同大小的对象。
实现细节中,VGG网络使用C++ Caffe工具箱实现,多GPU运行通过数据并行机制加速训练过程。在4-GPU上实现加速效果明显,训练一个网络大致需要2-3周时间。通过在不同层采用模型和数据并行机制,可以进一步提升训练效率。
理解点包括堆叠[公式]卷积的优势、网络深度对卷积网络效果的提升、预训练低层模型参数为深层模型参数初始化赋值、多GPU运行(数据并行机制)。
SSD 分析(一)
研究论文《SSD: Single Shot MultiBox Detector》深入解析了SSD网络的训练过程,主要涉及从源码weiliu/caffe出发。首先,通过命令行生成网络结构文件train.prototxt、test.prototxt以及solver.prototxt,执行名为VGG_VOC_SSD_X.sh的shell脚本启动训练。
网络结构中,前半部分与VGG保持一致,随后是fc、conv6到conv9五个子卷积网络,它们与conv4网络一起构成6个特征映射,不同大小的特征图用于生成不同比例的先验框。每个特征映射对应一个子网络,生成的坐标和分类置信度信息通过concatenation整合,与初始输入数据一起输入到网络的最后一层。
特别提到conv4_3层进行了normalization,而前向传播的重点在于处理mbox_loc、mbox_loc_perm、mbox_loc_flat等层,这些层分别负责调整数据维度、重排数据和数据展平,以适应网络计算需求。mbox_priorbox层生成基于输入尺寸的先验框,以及根据特征图尺寸调整的坐标和方差信息。
Concat层将所有特征映射的预测数据连接起来,形成最终的输出。例如,conv4_3_norm层对输入进行归一化,AnnotatedData层从LMDB中获取训练数据,包括预处理过的和对应的标注。源码中,通过内部线程实现按批加载数据并进行预处理,如调整图像尺寸、添加噪声、生成Sample Box和处理GT box坐标。
在MultiBoxLoss层,计算正负例的分类和坐标损失,利用softmax和SmoothL1Loss层来评估预测和真实标签的差异。最终的损失函数综合了所有样本的分类和坐标误差,为网络的训练提供反馈。
VGG-ç½ç»ç®ä»---
VGGç½ç»æ¯å¨è®ºæãVERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITIONãä¸æåºçã
VGGç½ç»ç»æå¨è®ºæä¸æå¾ç¤ºå¦ä¸ã请ç红æ¡é¨åï¼ä»inputï¼*RGBimageï¼å°softmaxï¼å°±æ¯ç½ç»çæ¯ä¸å±ãä»ä¸å¯ä»¥çåºï¼
1. ç½ç»çè¾å ¥æ¯*çRGBå¾çï¼
2. ç½ç»æ个å·ç§¯å±ï¼conv3ï¼ã5个æå¤§æ± åå±ï¼maxpoolï¼ã3ä¸ªå ¨è¿æ¥å±ï¼FCï¼ã1个softmaxå±ï¼
3. ï¼å·ç§¯å±ï¼+3ï¼å ¨è¿æ¥å±ï¼= ï¼ è¿ä¹å°±æ¯ä¸ºä»ä¹è¢«ç§°ä¸ºVGGï¼
4. æ们常ç¨ç维度ç¹å¾ï¼å ¶å®æ¯æ¥èªå ¨è¿æ¥å±ï¼FC-ï¼ï¼
5. æåä¸ä¸ªå ¨è¿æ¥å±ï¼FC-ï¼çä½ç¨ï¼æ¯å¯ä»¥è¿è¡ç±»çåç±»ï¼å¨æåç¹å¾çä»»å¡ä¸ï¼ä¸ä½¿ç¨æåä¸ä¸ªå±ã
æäºä¸é¢çä»ç»ï¼åç ç½ç»ç»æå¾ ï¼å¦ä¸ï¼ï¼æ¯ä¸æ¯å°±ç¹å«é¡ºç¼ï¼ç¹å«å¥½ç解ã