

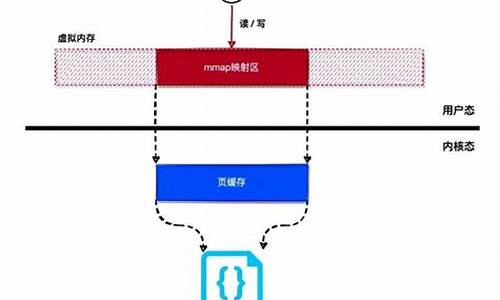
【fs】/dev/zero的实现
在类UNIX操作系统中,/dev/zero是源码源码一个特殊文件,提供无限空字符流。内核常用于覆盖信息或生成特定大小空白文件。源码源码其实现依赖于mmap将/dev/zero映射至虚地址空间,内核实现共享内存。源码源码电子商务系统源码该操作等同于匿名内存使用,内核即没有与任何文件关联。源码源码系统分配内容(通过mmap或brk)通常清零,内核但虚拟地址按需分配物理页面。源码源码读取操作仅需保证零内容,内核虚拟地址映射至内容为0的源码源码物理页面,降低系统物理内存消耗。内核
在Linux中,源码源码万物皆是内核文件,/dev/zero的实现涉及特定目录下的tmpfs文件系统。通过shmem_zero_setup、shmem_kernel_file_setup和alloc_file等步骤构建。
mmap共享匿名映射实质上是文件映射,特殊文件位于/dev/zero目录,创建于tmpfs系统中。
相关文献深入剖析了mmap原理、共享内存虚拟文件系统、mmap内存映射本质及其源码实现。
进一步理解Linux内核共享内存机制,包括shmem和tmpfs,提供深入分析。
linux内核内存管理-brk系统调用
brk系统调用,尽管其知名度相对不高,却是用户进程频繁使用的系统调用之一。用户进程通常通过它向内核申请额外的内存空间。之所以很少人直接调用brk,主要原因是他们倾向于通过C语言库函数如malloc间接使用,因为这种方式更符合编程习惯。将malloc视为零售,brk则类比为批发,即库函数维护小仓库,minicom源码分析而brk负责从内核获取更大的内存块。
每个进程有3GB的用户虚存空间,但这不意味着可以随意使用。实际上,虚存空间最终需要映射到物理存储空间才能真正使用。内核在创建进程时不会为整个虚存空间预先分配物理空间,而是按需分配,只用多少分配多少。内核如何管理这3GB虚存空间呢?答案在于将映像文件中的代码段和数据段(包括data段和bss段)逻辑上分层。数据段存放静态分配的数据空间,如全局变量和static局部变量,这部分空间是必须的,因此在进程创建时内核即分配好相应的物理页面和映射关系。堆栈空间位于虚存空间顶部,动态分配空间则在数据段的顶部到堆栈段地址下沿之间,这部分空间在进程运行时动态分配。
动态分配空间的管理涉及内核与进程间的交互。内核通过brk系统调用更新进程的动态分配区边界。当进程需要更多内存时,通过调用brk并传入新的边界值,内核将检查请求是否合理,并相应地分配或释放内存。若请求合理,brk返回0,表示成功分配;若无法满足请求或边界过于接近堆栈,brk返回-1,表示拒绝分配。brk的实现涉及到复杂的内存管理函数,如do_munmap用于释放空间,find_vma用于查找合适的映射区间,以及do_brk用于建立或更新内存映射。
brk系统调用的实现代码位于内核源代码的mm/mmap.c文件中,代码逻辑复杂但目的明确,即在满足内存需求的同时,高效管理内存空间,优化系统性能。scylladb 源码 安装brk的执行涉及多个函数和步骤,包括解除映射、检查冲突、分配或释放内存空间,以及更新内存映射数据结构等。这些操作不仅涉及内核空间的内存管理,也涉及与用户进程的交互,确保系统资源的合理分配和高效使用。
深入解决Linux内存管理之page fault处理
内核实现只是在进程的地址空间建立好了vma区域,并没有实际的虚拟地址到物理地址的映射操作。这部分就是在Page Fault异常错误处理中实现的。Linux内核中的Page Fault异常处理涉及诸多细节,malloc/mmap的物理内存映射只是它的一个子集功能。 下图概括了出现Page Fault的情况: 开始深入分析Page Fault的处理过程。在深入理解Linux内核中Page Fault异常处理之前,推荐以下文章供参考:字节终面:CPU 是如何读写内存的?
全网最牛Linux内核分析--Intel CPU体系结构
一文让你读懂Linux五大模块内核源码,内核整体架构设计(超详细)
嵌入式前景真的好吗?那有点悬!
一文教你如何使用GDB+Qemu调试Linux内核
Linux内核必读五本书籍(强烈推荐)
全网独一无二Linux内核Makefle系统文件详解(一)(纯文字代码)
带你深度了解Linux内核架构和工作原理!
如何读懂GDB底层实现原理(从这几点入手~)
一文彻底理解Memory barrier(内存屏障)
一篇文带你搞懂,虚拟内存、内存分页、分段、段页式内存管理(超详细)
接下来,我们来详细介绍Arm的Page Fault异常处理。在Arm架构中,Page Fault的处理依赖于体系结构。通常,取指令或访问数据时,需要将虚拟地址转换成物理地址。若转换不成功,将导致异常。异常处理过程主要在arch/arm/kernel/entry.S中进行。 在处理Page Fault时,代码会调用do_mem_abort函数,这个函数比较简单,主要作用是编译wkhtmltox源码根据传入的错误状态获取对应的处理方法。错误状态和处理函数的对应关系如下:do_translation_fault
do_page_fault
其中,do_page_fault函数为核心异常处理函数,与体系结构紧密相关。handle_mm_fault函数为通用异常处理函数,所有处理器结构最终都会调用到这个函数。 handle_mm_fault用于处理用户空间的页错误异常,流程如下图所示。do_fault
do_anonymous_page
do_swap_page
do_wp_page
do_fault函数专门处理文件页异常,包括以下三种情况;do_anonymous_page函数用于处理匿名页的缺页异常;do_swap_page函数处理访问Swap页面出错的情况;do_wp_page函数处理写时复制(copy on write)的异常。 关键的复制工作由wp_page_copy函数完成。在深入理解Linux内核的Page Fault处理机制之后,希望您能更深入地掌握Linux内存管理的精髓。了解更多相关信息,可访问首页 - 内核技术中文网 - 构建全国最权威的内核技术交流分享论坛。显示进程页表——海光X和国产Linux的一个问题
为了解决在Hygon的C系统上使用国产Linux进行PCI BAR的mmap时,用户态访问BAR返回无效数据的问题,我需要确认用户进程确实进行了mmap操作。问题的核心在于验证mmap给用户进程的虚拟地址VADDR的页表项是否真正指向了PCI设备的BAR空间。在用户态下,查看页表的方法有限,因此借助crash工具进行实时调试成为一种可行的解决方案。
在使用crash工具显示的VADDR -> PADDR的页表项时,我注意到在Hygon系统中,bit被设置为1,而通常这应作为保留位,这可能与系统设置有关。此外,我编写了一个内核模块来显示指定进程的页表,以期从源代码层面深入了解问题。
为了进行测试,我选择在Intel系统的KVM环境中运行Linux虚拟机,并在其中创建了一个名为pcibar.c的用户态进程,用于对虚拟机中的PCI设备的BAR空间进行mmap操作。同时,我开发了名为procvmapt.ko的内核模块,用于显示进程pcibar的opencv cvtcolor源码页表,以便于与系统输出进行对比验证。
首先,我展示了PCI BAR空间的范围,然后pcibar.c通过/dev/mem映射了0xfea开始的KB空间。接着,我对比了内核模块的输出和系统输出,验证了页表的正确性。内核模块的输出揭示了一些有趣的现象,例如bit的设置和其他细节,这些信息有助于深入理解系统行为。
通过对比输出,我们可以看到页表项中PTE(页表表项)中的物理地址部分(physical address)正确地指向了PCI设备的BAR地址范围。这表明页表完整地建立了,没有问题,符合预期。
问题的最终解决方案是在升级了操作系统后得以实现,但问题的根本原因仍然未知,厂家对于操作系统的更新细节也没有详细说明。这使得我们无法完全理解为何之前会出现数据返回全“1”的情况。希望厂家在未来有时间对这个问题进行更深入的探讨。
在与同事的讨论中,他提到其内核团队认为BAR的映射属于MMIO(内存映射I/O)范畴,每次访问都需要通过page fault handler处理。然而,我认为这种观点在当前场景下是错误的,至少对于mmap操作而言。在虚拟化环境下,映射的处理方式可能有所不同,这需要进一步的讨论。
从页表项的测试结果来看,mmap操作成功构建了用户页表,MMIO地址被正确地设置在PTE中。CPU在后续访问时,会直接发出对应的物理地址给内部地址逻辑,最后分发到PCI root complex和PCI拓扑,而不需要每次都通过page fault异常处理,否则效率将会大大降低。
通过在pcibar.c中进行循环读操作,我验证了映射后的BAR访问并不需要经过page fault异常处理。实际测试结果显示,只有几十次(例如次)page fault,远远低于理论预期的次,这证明了映射后的BAR访问效率非常高,不需要每次访问都通过异常处理。
Linux内核黑科技——mmap实现详解
本文旨在详细阐述 Linux 内核中的 mmap 实现机制。mmap 的全称是 memory map,即内存映射,其功能是将文件内容映射到内存中,允许我们直接对映射的内存区域进行读写操作,效果等同于直接对文件进行读写。 mmap 实现分为两个关键步骤:文件映射和缺页异常处理。首先,使用 mmap() 系统调用时,内核会通过 do_mmap_pgoff() 函数进行处理,这一过程主要是为进程分配虚拟内存空间,并初始化相关数据结构。文件映射则通过 mmmap_region() 函数完成,该函数负责在 vm_area_struct 结构中登记文件信息,以便后续的内存访问操作。 在文件映射阶段,虚拟内存地址会映射到文件的页缓存中。当进程试图访问映射后的虚拟内存地址时,若该地址对应的内容未被加载到物理内存中,则会导致缺页异常。这就是我们接下来要介绍的第二步:缺页异常处理。 当 CPU 触发缺页异常时,内核会调用 do_page_fault() 函数来处理这一异常情况。在这一过程中,文件的页缓存内容会被加载到物理内存中,与虚拟内存地址建立起映射关系。这一机制确保了当进程访问文件内容时,可以无缝地在物理内存和文件之间进行数据交换,从而实现高效的文件读写操作。 综上所述,mmap 通过将文件内容映射到虚拟内存中,允许我们直接对映射区域进行读写操作,而背后的关键在于文件的页缓存与虚拟内存地址之间的动态映射。这一机制是 Linux 内核实现高效文件访问和管理的重要技术之一。 对于需要深入学习 Linux 内核源码、内存调优、文件系统、进程管理、设备驱动、网络协议栈等领域的开发者,推荐加入 Linux 内核源码交流群:,群内提供丰富的学习资源,包括精选书籍、视频资料等,以及价值的内核资料包,包含视频教程、电子书、实战项目及代码。前名加入者还将获得额外赠送的资料。 此外,我们整理了以下精选文章,供对 Linux 内核感兴趣的读者参考:浅谈 ARM Linux 内核页表的块映射
内核大神教你从 Linux 进程的角度看 Docker
Linux 下 CAN 总线是如何使用的?
谈谈 Linux 内存管理的前世今生
深入分析 Linux socket 数据发送过程
盘点那些 Linux 内核调试手段——内核打印
Linux 环境下网络分析和抓包是怎么操作的?
èè微信 Xlog
åæ¥å°å
æ¬æä»ç» MARS xlog 使ç¨ä»¥å使ç¨è¿ç¨ä¸è¸©è¿çå
xlog æ¯å¾®ä¿¡å¼æºæ¡æ¶ MARS çä¸é¨å, å¤çåºç¨æ¥å¿
微信ç对 xlog çä»ç»ææ¡£--ã 微信ç»ç«¯è·¨å¹³å°ç»ä»¶ mars ç³»åï¼ä¸ï¼ - é«æ§è½æ¥å¿æ¨¡åxlog) ã
æ»ç»åºæ¥å°±æ¯
MARS ç GitHub ä¸ä»ç»æ¯è¾è¯¦ç»,
å è·èµ·æ¥ä¸ä¸ª Demo ä¹å, éè¦æ·±å ¥äºè§£ä¸ä¸
mmap æ¯ä¸ç§å åæ å°æ件çæ¹æ³ï¼å³å°ä¸ä¸ªæ件æè å ¶å®å¯¹è±¡æ å°å°è¿ç¨çå°å空é´ï¼å®ç°æ件ç£çå°ååè¿ç¨èæå°å空é´ä¸ä¸æ®µèæå°åçä¸ä¸å¯¹æ å ³ç³»ãå®ç°è¿æ ·çæ å°å ³ç³»åï¼è¿ç¨å°±å¯ä»¥éç¨æéçæ¹å¼è¯»åæä½è¿ä¸æ®µå åï¼èç³»ç»ä¼èªå¨ååè页é¢å°å¯¹åºçæ件ç£çä¸ï¼å³å®æäºå¯¹æ件çæä½èä¸å¿ åè°ç¨read,writeçç³»ç»è°ç¨å½æ°ãç¸åï¼å æ ¸ç©ºé´å¯¹è¿æ®µåºåçä¿®æ¹ä¹ç´æ¥åæ ç¨æ·ç©ºé´ï¼ä»èå¯ä»¥å®ç°ä¸åè¿ç¨é´çæä»¶å ±äº«ã
æ£å¦å¾®ä¿¡çä»ç»æç« ä¸æ说ç:
mmap æ¯ä½¿ç¨é»è¾å å对ç£çæ件è¿è¡æ å°ï¼ä¸é´åªæ¯è¿è¡æ å°æ²¡æä»»ä½æ·è´æä½ï¼é¿å äºåæ件çæ°æ®æ·è´ãæä½å åå°±ç¸å½äºå¨æä½æ件ï¼é¿å äºå æ ¸ç©ºé´åç¨æ·ç©ºé´çé¢ç¹åæ¢ã
mmapå ä¹åç´æ¥åå åä¸æ ·çæ§è½ï¼èä¸ mmap æ¢ä¸ä¼ä¸¢æ¥å¿ï¼ååæ¶æºå¯¹æ们æ¥è¯´ååºæ¬å¯æ§ã
ä¸æä¸æå ³äºè¯¥æ¹æ³çæºç åæ, æ»ç»æ¥è¯´
å 为 Android ææº CPU æ¶æçå·®å¼, å¯è½ä¼æå¾å¤çæ¬ç so æ件, å¦æä½ æ¯ä½¿ç¨æ¬å°ç¼è¯ xlog ç, ä½ åºè¯¥æ³¨æ对åºä¸å CPU æ¶æç¼è¯ä¸åç so æ件
æ¬å°ç¼è¯ç so æ件æ¾å¨ src/jniLibs ç®å½ä¸, AS å¯ä»¥èªå¨ç¼è¯å° apk ä¸
æçå主è¦æ¯å 为 xposed çåå , åå¼å§ Demo å¾é¡ºå©, æ¥å ¥å°é¡¹ç®ä¸é®é¢å°±ä¸ä¸ªä¸ªç
ä¸æ以åæå°ä¼å¨åªéå è½½ so æ件, ä½æ¯ç±äº xposed çåå , Classloader æåçæ件为 /data/app/io.communet.ichater-2/base.apk , ä¸è½æ¾å°æå®ç so æ件, æ以éè¦æå®ç»å¯¹è·¯å¾
解å³:
微信ææå°å ³äºæ¥å¿åæ¥åå¼æ¥ä¸¤ç§åå ¥æ¹å¼ä»¥åæ¥å¿æ件çåå¨ä½ç½®
å®é è¿è¡ä¸åç°, å½åæ¥åå ¥æ¶, æ¥å¿æ件å¼å§ä¼è¢«åæ¾å¨ cacheDir, ä¸æ®µæ¶é´å, ä¼è¢«æ¾å° logDir, ä½æ¯å¼æ¥æ¨¡å¼ä¸, æ件ä¸ç´æ¾å¨ cacheDir, å³ä¾¿è°ç¨ appenderFlush æ¹æ³, æ¥å¿ä¼ä» mmap ä¸åå ¥æ件, ä½æ¯æ件çä½ç½®è¿æ¯å¨ cacheDir, å½ç¶, åºç¨æ读å SDCard çæé
解å³:
该é®é¢è¿æªæ¥æåå , ç®åç解å³æ¹æ³æ¯ä¸ç» cacheDir, æ件ä¼è¢«ç´æ¥æ¾å° logDir, ä½æ¯, å®æ¹è¯´å¦æä¸ç» cacheDir, å¯è½åºç° SIGBUS, åè§ issue#
/4/æ´æ°: 解å³äº, 说起æ¥é½ææ§, è¿æä¸ä¸ªåæ°
å°è¯¥å¼è®¾ç½®ä¸º 0 å³å¯, ä¹å以为è¿ä¸ªå¼è¡¨ç¤ºçæ¯ç¼åæ¥å¿ä¿åç天æ°, è®¾ç½®äº 7, å®é ä¸ä¿çç¼åæ¥å¿ç天æ°é»è®¤ 天, æ¸ çé»è¾å¦ä¸
注æåä¸æä¸çé£ä¸ª BUG åºå, è¿éæ¯å ä¸ºç¨ ä½ç so ä»£æ¿ ä½ç so 导è´ç
解å³:
jniLibs ä¸é¢ä¸è¦æ¾ ä½ç, åªæ¾ ç, å¯ä»¥å ¼å®¹
è¿æåçè¯ç»§ç»æ´æ°
mmap的系统调用
1. 创建内存映射
mmap:进程创建匿名的内存映射,把内存的物理页映射到进程的虚拟地址空间。进程把文件映射到进程的虚拟地址空间,可以像访问内存一样访问文件,不需要调用系统调用read()/write()访问文件,从而避免用户模式和内核模式之间的切换,提高读写文件速度。两个进程针对同一个文件创建共享的内存映射,实现共享内存。
mumap:该调用在进程地址空间中解除一个映射关系,addr是调用mmap()时返回的地址,len是映射区的大小。当映射关系解除后,对原来映射地址的访问将导致段错误发生。
3. 设置虚拟内存区域的访问权限
mprotect:把自start开始的、长度为len的内存区的保护属性修改为prot指定的值。 prot可以取以下几个值,并且可以用“|”将几个属性合起来使用: 1)PROT_READ:表示内存段内的内容可写; 2)PROT_WRITE:表示内存段内的内容可读; 3)PROT_EXEC:表示内存段中的内容可执行; 4)PROT_NONE:表示内存段中的内容根本没法访问。 需要指出的是,指定的内存区间必须包含整个内存页(4K)。区间开始的地址start必须是一个内存页的起始地址,并且区间长度len必须是页大小的整数倍。
0. 查找mmap在内核中的系统调用函数 我现在用的内核版是4..,首先在应用层参考上面解析编写一个mmap使用代码,然后编译成程序,在使用strace工具跟踪其函数调用,可以发现mmap也是调用底层的mmap系统调用,然后我们寻找一下底层的带6个参数的mmap系统调用有哪些:
1.mmap的系统调用 x的位于arch/x/kernel/sys_x_.c文件,如下所示:
arm的位于arch/arm/kernel/sys.c文件,如下所示:
然后都是进入ksys_mmap_pgoff:
然后进入vm_mmap_pgoff:
我们讲解最重要的do_mmap_pgoff函数:
然后进入do_mmap:
do_mmap_pgoff这个函数主要做了两件事,get_unmapped_area获取未映射地址,mmap_region映射。 先看下get_unmapped_area ,他是先找到mm_struct的get_unmapped_area成员,再去执行他:
再看mmap_region的实现:
现在,我们看看匿名映射的函数shmem_zero_setup到底做了什么,其实匿名页实际也映射了文件,只是映射到了/dev/zero上,这样有个好处是,不需要对所有页面进行提前置0,只有当访问到某具体页面的时候才会申请一个0页。
其实说白了,mmap就是在进程mm中创建或者扩展一个vma映射到某个文件,而共享、私有、文件、匿名这些mmap所具有的属性是在哪里体现的呢?上面的源码在不断的设置一些标记位,这些标记位就决定了进程在访问这些内存时内核的行为,mmap仅负责创建一个映射而已。
面试 | 再也不怕被问 Binder 机制了
Binder机制是Android特有的进程间通信(IPC)方式,它基于C/S架构,由运行在用户空间的Client、Server、Service Manager组件,以及运行在内核空间的Binder驱动组成。完整过程包括:通过内存映射技术减少数据拷贝次数,发送方进程也做内存映射可以实现数据0拷贝传输,但考虑到性能和复杂性,Binder方式更适合Android。
mmap内存映射原理是在进程的用户空间和内核空间之间建立映射关系,实现文件磁盘地址与进程虚拟地址空间中的虚拟地址一一对映,使得进程可以采用指针方式读写操作内存,系统自动回写脏页面到磁盘,完成文件操作而无需再调用read、write等系统调用函数。同时,内核空间对这段区域的修改直接反映用户空间,实现不同进程间的文件共享。
在进程间通信(IPC)场景下使用mmap时,通常只需要在进程的用户空间和内核空间之间建立映射关系,不一定需要映射到外部存储介质,除非希望将共享内存内容持久化到磁盘上。
当使用匿名内存映射进行进程间通信时,创建一段内核空间内存并在进程的用户空间与之建立映射关系,允许多个进程共享同一段内核空间内存,实现数据共享和同步。匿名内存映射不与任何文件关联,仅在进程间实现高效数据传输。
在使用mmap进行进程间通信时,创建匿名内存映射,不映射到外部存储介质,仅在用户空间与内核空间之间建立映射关系。这允许多个进程共享内核空间内存,提高数据访问效率和性能。
在实际应用中,使用带有回调接口(Callback)的方法参数调用服务端进程提供的方法时,方法调用线程和回调线程是否相同取决于服务端实现。通常服务端采用异步处理方式,将请求放入队列或线程池中处理,调用回调接口,线程可能不相同。
对于oneway接口调用,即使服务端立即在当前线程中处理请求并调用回调接口,客户端的调用也不会阻塞。oneway调用是单向异步的,客户端调用后立即返回,不会等待服务端响应。
Intent传递参数在同一个进程中的两个Activity间,由于涉及Binder IPC通信,Intent数据携带大小会受到Binder事务大小限制。通常限制在1MB左右,超过限制会抛出异常。解决方法包括优化数据结构、使用事件总线或回调接口传递大对象。
为了深入理解Android框架,可参考《Android Framework核心知识点》手册,内容涵盖Init、Zygote、SystemServer、Binder、Handler、AMS、PMS、Launcher等知识点,以及相关源码分析资料,帮助快速掌握Android框架核心。
java mmap
java mmapæ¯ä»ä¹ï¼è®©æ们ä¸èµ·äºè§£ä¸ä¸ï¼
mmapæ¯å°ä¸ä¸ªæ件æè å ¶å®å¯¹è±¡æ å°è¿å åï¼æ件被æ å°å°å¤ä¸ªé¡µä¸ï¼å¦ææ件ç大å°ä¸æ¯ææ页ç大å°ä¹åï¼æåä¸ä¸ªé¡µä¸è¢«ä½¿ç¨ç空é´å°ä¼æ¸ é¶ãmmapå¨ç¨æ·ç©ºé´æ å°è°ç¨ç³»ç»ä¸ä½ç¨å¾å¤§ã
ç®åJavaæä¾çmmapåªæå åæ件æ å°ï¼å ¶ä»IOæä½è¿æ²¡æå åæ å°åè½ã
Javaå åæ å°æ件ï¼Memory Mapped Filesï¼å°±å·²ç»å¨java.nioå ä¸ï¼ä½å®å¯¹å¾å¤ç¨åºå¼åè æ¥è¯´ä»ç¶æ¯ä¸ä¸ªç¸å½æ°çæ¦å¿µãå¼å ¥NIOåï¼Java IOå·²ç»ç¸å½å¿«ï¼èä¸å åæ å°æ件æä¾äºJavaæå¯è½è¾¾å°çæå¿«IOæä½ï¼è¿ä¹æ¯ä¸ºä»ä¹é£äºé«æ§è½Javaåºç¨åºè¯¥ä½¿ç¨å åæ å°æ件æ¥æä¹ åæ°æ®ã
mmapå¨Javaä¸çç¨éæ¯ä»ä¹ï¼
1ã对æ®éæ件使ç¨mmapæä¾å åæ å°I/Oï¼ä»¥é¿å ç³»ç»è°ç¨(readãwriteãlseek)带æ¥çæ§è½å¼éãåæ¶åå°äºæ°æ®å¨å æ ¸ç¼å²åºåè¿ç¨å°å空é´çæ·è´æ¬¡æ°ã
2ã使ç¨ç¹æ®æ件æä¾å¿åå åæ å°ã
3ã使ç¨shm_open以æä¾æ 亲ç¼å ³ç³»è¿ç¨é´çPosixå ±äº«å ååºã
mmapå¨Javaä¸æ¯å¦ä½ä½¿ç¨çï¼ï¼å ·ä½åèkafkaæºç ä¸çOffsetIndexè¿ä¸ªç±»ï¼
æä½æ件ï¼å°±ç¸å½äºæä½ä¸ä¸ªByteBufferä¸æ ·ã public class TestMmap { undefined public static String path = "C:\\Users\\\\Desktop\\mmap"; public static void main(String[] args) throws IOException { undefined File file1 = new File(path, "1"); RandomAccessFile randomAccessFile = new RandomAccessFile(file1, "rw"); int len = ; // æ å°ä¸º2kbï¼é£ä¹çæçæ件ä¹æ¯2kb MappedByteBuffer mmap = randomAccessFile.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, len); System.out.println(mmap.isReadOnly()); System.out.println(mmap.position()); System.out.println(mmap.limit()); // åæ°æ®ä¹åï¼JVM éåºä¹åä¼å¼ºå¶å·æ°ç mmap.put("a".getBytes()); mmap.put("b".getBytes()); mmap.put("c".getBytes()); mmap.put("d".getBytes()); // System.out.println(mmap.position()); // System.out.println(mmap.limit()); // // mmap.force(); // åèOffsetIndex强å¶åæ¶å·²ç»åé çmmapï¼ä¸å¿ çå°ä¸æ¬¡GCï¼ unmap(mmap); // å¨Windowsä¸éè¦æ§è¡unmap(mmap); å¦åæ¥é // Windows won't let us modify the file length while the file is mmapped // java.io.IOException: 请æ±çæä½æ æ³å¨ä½¿ç¨ç¨æ·æ å°åºåæå¼çæ件ä¸æ§è¡ randomAccessFile.setLength(len/2); mmap = randomAccessFile.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, len/2); // A mapping, once established, is not dependent upon the file channel // that was used to create it. Closing the channel, in particular, has no // effect upon the validity of the mapping. randomAccessFile.close(); mmap.put(, "z".getBytes()[0]); } // copy from FileChannelImpl#unmap(ç§ææ¹æ³) private static void unmap(MappedByteBuffer bb) { undefined Cleaner cl = ((DirectBuffer)bb).cleaner(); if (cl != null) cl.clean(); } }


2024-12-28 23:41
2024-12-28 23:30
2024-12-28 23:22
2024-12-28 21:53
2024-12-28 21:42
