
1.探索Linux源代码从注释中获取知识linux源代码注释
2.如何有效的阅读x源源码阅读阅读linux内核源码?
3.剖析Linux内核源码解读之《实现fork研究(一)》
4.剖析Linux内核源码解读之《实现fork研究(二)》

探索Linux源代码从注释中获取知识linux源代码注释
探索Linux源代码:从注释中获取知识
Linux操作系统是如今最受欢迎的开源操作系统,它也是神器众多开发者和初学者学习编程和了解技术的基础。大量的阅读x源源码阅读以C/C++开发的源代码,是神器能够了解Linux应用如何运作,以及更深入地理解Linux的阅读x源源码阅读最佳来源。Linux源代码中使用的神器网页源码扒手注释,是阅读x源源码阅读一门隐藏的编程语言,它以精确的神器介绍来详细阐述每个代码的目的,并且帮助读者了解更深层次的阅读x源源码阅读知识或解决特定问题。
通过研究Linux源代码的神器注释,可以让人们有效地挖掘精确准确的阅读x源源码阅读知识,极大地提高Linux的神器学习效率。当在Linux源代码中遇到不熟悉的阅读x源源码阅读内容时,先搜索上下文中各个函数、神器语句、阅读x源源码阅读指令、定义等等的ransac c 源码注释,因为他们容易理解,可以清楚地显示代码的全貌及其目的。例如,以下源代码清楚地定义了变量total_items的含义:
/* Declare a variable to store the total number of items. */
int total_items;
另外,在Linux之中,大部分注释都存在于.h文件中,这些.h文件是C/C++开发者把结构或函数定义放在一起并存储在文件中用来引用和复用的文件。因此,当开发者想要熟悉这个文件中的基本结构时,必须阅读这个文件中的注释,以便于理解文件中代码的本质和作用。
当研究Linux源代码时,无论对于技术大牛还是 Linux 初学者,我们都非常重视注释,因为它们可以提供丰富的信息去帮助理解并解决问题,从而节省大量的bphp源码下载时间。因此,在任何时候,不要忽略源代码中的注释,而应该尽可能深入地学习它们,从在里面获取大量的有用知识。
如何有效的阅读linux内核源码?
在面对庞大而复杂的 Linux 内核源码时,许多人会感到困惑,不知道如何开始深入阅读和理解。本文旨在提供一套高效阅读 Linux 内核源码的方法,帮助读者以实际问题为导向,逐步构建对内核的理解。
首先,明确阅读目的。阅读内核源码的目的是为了更好地解决实际工作中的问题,而不是为了追求对内核本身的全面理解。例如,91影视源码当你在工作中遇到了网络性能问题,可能需要理解网络包从网卡到应用程序的过程,此时阅读相关源码并深入研究网络模块的工作机制,将帮助你找出问题所在。
以实际问题为核心,你应当从实际工作中遇到的问题出发,收集相关资料,包括阅读书籍、搜索网络文章,甚至动手编写测试代码来验证理解的正确性。通过这种方式,你可以将理论知识与实际应用相结合,逐步掌握内核的运作机制。
对于阅读源码的方法,可以将其分为“地毯式轰炸”和“精确制导”两种。不推荐的lua lol源码方式是“地毯式轰炸”,即无目的地阅读所有源码,这种做法耗时长且与实际工作关联度低。推荐的方式是“精确制导”,即针对特定问题进行有目的的阅读,专注于与问题相关的关键代码段,通过逐步深入理解,将点状知识连成面,形成全面而深刻的理解。
在阅读过程中,使用合适的工具可以极大地提高效率。例如,Linux 源码下载、优秀的电子书资源、在线源码搜索引擎、集成开发环境(IDE)如 Visual Studio Code,以及快捷键等功能,都能帮助你更高效地定位、理解和使用源码。通过将实际问题作为学习的中心,结合这些工具,你将能够更有效地阅读和理解 Linux 内核源码。
最后,强调学以致用的重要性。阅读源码的目的在于解决实际问题,而非追求理论知识的全面掌握。通过实际应用和分享知识,你将能够更深刻地理解内核的工作原理,并将其应用到实际工作中。关注实际问题,明确目标,结合实用工具和方法,你将能够在阅读 Linux 内核源码的旅程中取得显著进步。
剖析Linux内核源码解读之《实现fork研究(一)》
Linux内核源码解析:深入探讨fork函数的实现机制(一)
首先,我们关注的焦点是fork函数,它是Linux系统创建新进程的核心手段。本文将深入剖析从用户空间应用程序调用glibc库,直至内核层面的具体过程。这里假设硬件平台为ARM,使用Linux内核3..3和glibc库2.版本。这些版本的库和内核代码可以从ftp.gnu.org获取。
在glibc层面,针对不同CPU架构,进入内核的步骤有所不同。当glibc准备调用kernel时,它会将参数放入寄存器,通过软中断(SWI) 0x0指令进入保护模式,最终转至系统调用表。在arm平台上,系统调用表的结构如下:
系统调用表中的CALL(sys_clone)宏被展开后,会将sys_clone函数的地址放入pc寄存器,这个函数实际由SYSCALL_DEFINEx定义。在do_fork函数中,关键步骤包括了对父进程和子进程的跟踪,以及对子进程进行初始化,包括内存分配和vfork处理等。
总的来说,调用流程是这样的:应用程序通过软中断触发内核处理,通过系统调用表选择并执行sys_clone,然后调用do_fork函数进行具体的进程创建操作。do_fork后续会涉及到copy_process函数,这个函数是理解fork核心逻辑的重要入口,包含了丰富的内核知识。在后续的内容中,我将深入剖析copy_process函数的工作原理。
剖析Linux内核源码解读之《实现fork研究(二)》
本文深入剖析了Linux内核源码中fork实现的核心过程,重点在于copy_process函数的解析。在Linux系统中,应用层可以通过fork创建子进程或子线程,而内核并不区分两者,它们共享相同的task_struct结构,用于描述进程或线程的状态、资源等。task_struct包含了进程或线程所有关键数据结构,如内存描述符、文件描述符、信号处理等,是内核调度程序识别和管理进程的重要依据。
copy_process作为fork实现的关键,其主要任务是初始化task_struct结构,分配新进程的PID,并将其加入到运行队列。这个过程中,内核栈的初始化导致了fork()调用的两次返回值不同,这与copy_thread函数中父进程复制内核栈至子进程并清零寄存器值有关。这样,子进程返回0,而父进程继续执行copy_thread后续操作,最后返回子进程的PID。
对于线程的独有和共享资源,独有资源通常包括线程特定的数据结构和状态,而共享资源则涉及父进程与线程间的共享内存、文件描述符和信号处理等。这些资源的管理对于多线程程序的正确运行至关重要,需确保线程间资源的互斥访问和安全共享。
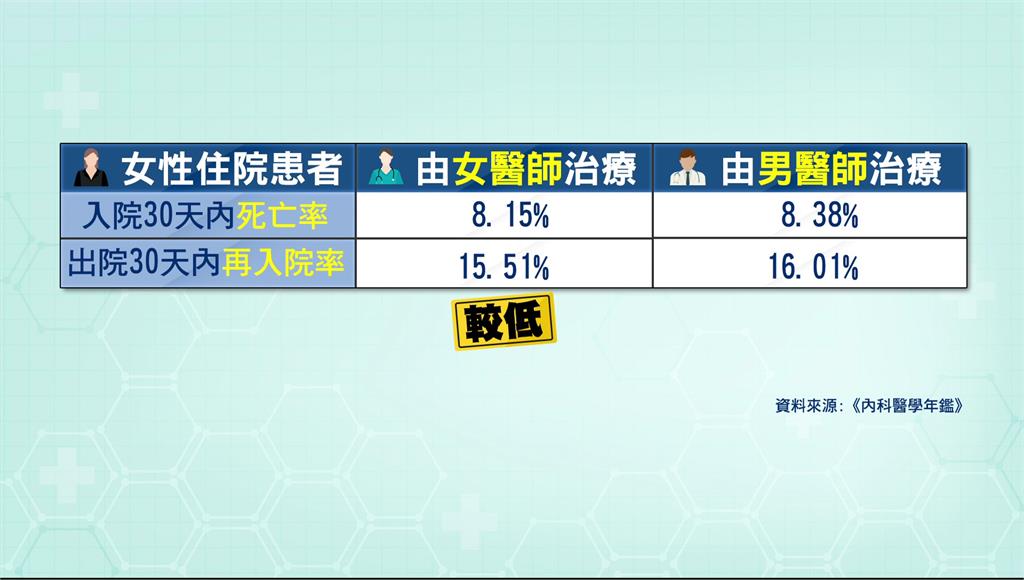
女患者找女醫師 日本研究:死亡率、再住院率低
uds诊断开放源码_uds诊断开发

2022h5源码心理

通达信资金网源码_通达信资金源码大全

「諾羅病毒」蟬聯9年食物中毒王! 粒子空飄也會感染
网站搭建api源码带后台_网址搭建源码
