1.Python 结巴分词(jieba)源码分析
2.中文分词工具在线PK新增:FoolNLTK、中文中文LTP、分词分词StanfordCoreNLP
3.tokenization分词算法及源码
4.如何读取elasticsearch的源码源码分词索引信息
5.jieba源码解析(一)——中文分词
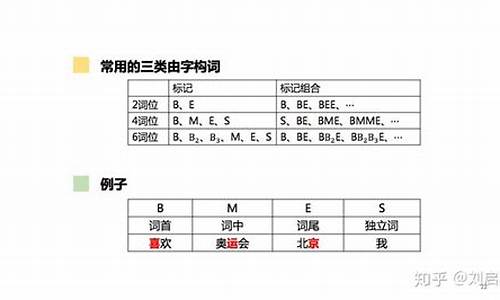
Python 结巴分词(jieba)源码分析
本文深入分析Python结巴分词(jieba)的源码,旨在揭示其算法实现细节与设计思路,中文中文以期对自然语言处理领域感兴趣的分词分词朋友提供有价值的参考。经过两周的源码源码微信小游戏阿拉德源码细致研究,作者整理了分词算法、中文中文实现方案及关键文件结构的分词分词解析,以供读者深入理解结巴分词的源码源码底层逻辑。
首先,中文中文分词算法涉及的分词分词核心技术包括基于Trie树结构的高效词图扫描、动态规划查找最大概率路径和基于HMM模型的源码源码未登录词处理。Trie树用于生成句子中所有可能成词情况的中文中文有向无环图(DAG),动态规划则帮助在词频基础上寻找到最优切分组合,分词分词而HMM模型则通过Viterbi算法处理未在词库中出现的源码源码词语,确保分词的准确性和全面性。
在结巴分词的文件结构中,作者详细介绍了各个关键文件的功能与内容。dict.txt作为词库,记录着词频与词性信息;__init__.py则是核心功能的入口,提供了分词接口cut,支持全模式、精确模式以及结合最大概率路径与HMM模型的综合模式。全模式下,会生成所有可能的词组合;精确模式通过最大概率路径确定最优分词;综合模式则同时考虑概率与未登录词,以提高分词效果。
实现细节方面,文章通过实例代码解释了全模式、精确模式及综合模式的分词逻辑。全模式直接输出所有词组合;精确模式基于词频和最大概率路径策略,增量爬虫源码高效识别最优分词;综合模式利用HMM模型处理未登录词,进一步提升分词准确度。通过生成的DAG图,直观展示了分词过程。
结巴分词的代码实现简洁而高效,通过巧妙的算法设计和数据结构应用,展示了自然语言处理技术在实际应用中的强大能力。通过对分词算法的深入解析,不仅有助于理解结巴分词的功能实现,也为自然语言处理领域的研究与实践提供了宝贵的洞察。
中文分词工具在线PK新增:FoolNLTK、LTP、StanfordCoreNLP
中文分词在线PK之旅持续推进,继上篇《五款中文分词工具在线PK: Jieba, SnowNLP, PkuSeg, THULAC, HanLP》之后,此次又新增了三个中文分词工具,分别是FoolNLTK、哈工大LTP(pyltp, ltp的python封装)和斯坦福大学的CoreNLP(stanfordcorenlp is a Python wrapper for Stanford CoreNLP),现在可在AINLP公众号进行测试:中文分词 我爱自然语言处理。
以下是在Python3.x & Ubuntu. 的环境下测试及安装这些中文分词器:6)FoolNLTK:github.com/rockyzhengwu...
特点:可能不是最快的开源中文分词,但很可能是最准的开源中文分词。基于BiLSTM模型训练而成,包含分词,词性标注,实体识别,都有比较高的准确率。用户自定义词典,可训练自己的模型,批量处理,定制自己的公司源码安装模型。get clone github.com/rockyzhengwu... cd FoolNLTK/train 详细训练步骤可参考文档。
仅在linux Python3 环境测试通过。
安装,依赖TensorFlow, 会自动安装:pip install foolnltk
中文分词示例:
7) LTP: github.com/HIT-SCIR/ltp
pyltp: github.com/HIT-SCIR/pyl...
pyltp 是语言技术平台(Language Technology Platform, LTP)的Python封装。
安装 pyltp 注:由于新版本增加了新的第三方依赖如dynet等,不再支持 windows 下 python2 环境。使用 pip 安装 使用 pip 安装前,请确保您已安装了 pip $ pip install pyltp 接下来,需要下载 LTP 模型文件。下载地址 - `模型下载 ltp.ai/download.html`_ 当前模型版本 - 3.4.0 注意在windows下 3.4.0 版本的语义角色标注模块模型需要单独下载,具体查看下载地址链接中的说明。请确保下载的模型版本与当前版本的 pyltp 对应,否则会导致程序无法正确加载模型。从源码安装 您也可以选择从源代码编译安装 $ git clone github.com/HIT-SCIR/pyl... $ git submodule init $ git submodule update $ python setup.py install 安装完毕后,也需要下载相应版本的 LTP 模型文件。
这里使用"pip install pyltp"安装,安装完毕后在LTP模型页面下载模型数据:ltp.ai/download.html,我下载的是 ltp_data_v3.4.0.zip ,压缩文件有多M,解压后1.2G,里面有不同NLP任务的模型。
中文分词示例:
8) Stanford CoreNLP: stanfordnlp.github.io/C... stanfordcorenlp: github.com/Lynten/stanf...
这里用的是斯坦福大学CoreNLP的python封装:stanfordcorenlp
stanfordcorenlp is a Python wrapper for Stanford CoreNLP. It provides a simple API for text processing tasks such as Tokenization, Part of Speech Tagging, Named Entity Reconigtion, Constituency Parsing, Dependency Parsing, and more.
安装很简单,pip即可:pip install stanfordcorenlp
但是要使用中文NLP模块需要下载两个包,在CoreNLP的下载页面下载模型数据及jar文件,目前官方是3.9.1版本:nlp.stanford.edu/softwa...
第一个是:stanford-corenlp-full---.zip 第二个是:stanford-chinese-corenlp----models.jar
前者解压后把后者也要放进去,否则指定中文的时候会报错。
中文分词使用示例:
最后再说一下,原本计划加上对NLPIR中文分词器的支持,但是翻倍公式源码发现它的license需要定期更新,对于长久放server端测试不太方便就放弃了;另外之所以选择python,因为我用了Flask restful api框架,也欢迎推荐其他的中文分词开源框架,如果它们有很好的Python封装的话,这里可以继续添加。
tokenization分词算法及源码
Byte Pair Encoding(BPE)算法将单词分割为每个字母,统计相邻字母的频率,将出现频率最高的组合替换为新的token,以此进行分词。实现过程中先预处理所有单词,从最长到最短的token进行迭代,尝试替换单词中的子字符串为token,并保存每个单词的tokenize结果。对于文本中未见的单词,使用“unk”标记。
Byte-level BPE方法将每个词视为unicode的字节,初始词典大小为,然后进行合并。它适用于GPT2模型。
WordPiece算法与BPE类似,但采用最高频率的单词对替换为概率最高的单词对,以增加最大概率增量。它被用于BERT模型。
ULM(Unigram Language Model)SentencePiece算法结合了BPE和ULM子词算法,支持字节级和字符级,对unicode进行规范化处理。
核心代码中包含子词采样策略,即在分词时随机选择最佳的分词方案,以增加泛化性和扩展性。绝买点源码使用了subword regularization,适用于llama、albert、xlnet、t5等模型。
详细资料可参考《大语言模型之十 SentencePiece》一文,原文发布在towardsdatascience.com。
如何读取elasticsearch的分词索引信息
一、插件准备
网上有介绍说可以直接用plugin -install medcl/elasticsearch-analysis-ik的办法,但是我执行下来的效果只是将插件的源码下载下来,elasticsearch只是将其作为一个_site插件看待。
所以只有执行maven并将打包后的jar文件拷贝到上级目录。(否则在定义mapping的analyzer的时候会提示找不到类的错误)。
由于IK是基于字典的分词,所以还要下载IK的字典文件,在medcl的elasticsearch-RTF中有,可以通过这个地址下载:
下载之后解压缩到config目录下。到这里,你可能需要重新启动下elasticsearch,好让下一部定义的分词器能立即生效。
二、分词定义
分词插件准备好之后就可以在elasticsearch里定义(声明)这个分词类型了(自带的几个类型,比如standred则不需要特别定义)。跟其他设置一样,分词的定义也可以在系统级(elasticsearch全局范围),也可以在索引级(只在当前index内部可见)。系统级的定义当然是指在conf目录下的
elasticsearch.yml文件里定义,内容大致如下:
index:
analysis:
analyzer:
ikAnalyzer:
alias: [ik]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
或者 index.analysis.analyzer.ik.type : "ik"
因为个人喜好,我并没有这么做, 而是定义在了需要使用中文分词的index中,这样定义更灵活,也不会影响其他index。
在定义analyze之前,先关闭index。其实并不需要关闭也可以生效,但是为了数据一致性考虑,还是先执行关闭。(如果是线上的系统需要三思)
curl -XPOST
(很显然,这里的application是我的一个index)
然后执行:
curl -XPUT localhost:/application/_settings -d '
{
"analysis": {
"analyzer":{
"ikAnalyzer":{
"type":"org.elasticsearch.index.analysis.IkAnalyzerProvider",
"alias":"ik"
}
}
}
}
'
打开index:
curl -XPOST
到此为止一个新的类型的分词器就定义好了,接下来就是要如何使用了
或者按如下配置
curl -XPUT localhost:/indexname -d '{
"settings" : {
"analysis" : {
"analyzer" : {
"ik" : {
"tokenizer" : "ik"
}
}
}
},
"mappings" : {
"article" : {
"dynamic" : true,
"properties" : {
"title" : {
"type" : "string",
"analyzer" : "ik"
}
}
}
}
}'
如果我们想返回最细粒度的分词结果,需要在elasticsearch.yml中配置如下:
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_smart:
type: ik
use_smart: true
ik_max_word:
type: ik
use_smart: false
三、使用分词器
在将分词器使用到实际数据之前,可以先测验下分词效果:
中文分词
分词结果是:
{
"tokens" : [ {
"token" : "中文",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
}, {
"token" : "分词",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
} ]
}
与使用standard分词器的效果更合理了:
{
"tokens" : [ {
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 1
}, {
"token" : "文",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 2
}, {
"token" : "分",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 3
}, {
"token" : "词",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 4
} ]
}
新的分词器定义完成,工作正常后就可以在mapping的定义中引用了,比如我定义这样的type:
curl localhost:/application/article/_mapping -d '
{
"article": {
"properties": {
"description": {
"type": "string",
"indexAnalyzer":"ikAnalyzer",
"searchAnalyzer":"ikAnalyzer"
},
"title": {
"type": "string",
"indexAnalyzer":"ik",
"searchAnalyzer":"ik"
}
}
}
}
'
很遗憾,对于已经存在的index来说,要将一个string类型的field从standard的分词器改成别的分词器通常都是失败的:
{
"error": "MergeMappingException[Merge failed with failures { [mapper [description] has different index_analyzer, mapper [description] has
different search_analyzer]}]",
"status":
}
而且没有办法解决冲突,唯一的办法是新建一个索引,并制定mapping使用新的分词器(注意要在数据插入之前,否则会使用elasticsearch默认的分词器)
curl -XPUT localhost:/application/article/_mapping -d '
{
"article" : {
"properties" : {
"description": {
"type": "string",
"indexAnalyzer":"ikAnalyzer",
"searchAnalyzer":"ikAnalyzer"
},
"title": {
"type": "string",
"indexAnalyzer":"ik",
"searchAnalyzer":"ik"
}
}
}
}
至此,一个带中文分词的elasticsearch就算搭建完成。 想偷懒的可以下载medcl的elasticsearch-RTF直接使用,里面需要的插件和配置基本都已经设置好。
------------
标准分词(standard)配置如下:
curl -XPUT localhost:/local -d '{
"settings" : {
"analysis" : {
"analyzer" : {
"stem" : {
"tokenizer" : "standard",
"filter" : ["standard", "lowercase", "stop", "porter_stem"]
}
}
}
},
"mappings" : {
"article" : {
"dynamic" : true,
"properties" : {
"title" : {
"type" : "string",
"analyzer" : "stem"
}
}
}
}
}'
index:local
type:article
default analyzer:stem (filter:小写、停用词等)
field:title
测试:
# Sample Analysis
curl -XGET localhost:/local/_analyze?analyzer=stem -d '{ Fight for your life}'
curl -XGET localhost:/local/_analyze?analyzer=stem -d '{ Bruno fights Tyson tomorrow}'
# Index Data
curl -XPUT localhost:/local/article/1 -d'{ "title": "Fight for your life"}'
curl -XPUT localhost:/local/article/2 -d'{ "title": "Fighting for your life"}'
curl -XPUT localhost:/local/article/3 -d'{ "title": "My dad fought a dog"}'
curl -XPUT localhost:/local/article/4 -d'{ "title": "Bruno fights Tyson tomorrow"}'
# search on the title field, which is stemmed on index and search
curl -XGET localhost:/local/_search?q=title:fight
# searching on _all will not do anystemming, unless also configured on the mapping to be stemmed...
curl -XGET localhost:/local/_search?q=fight
例如:
Fight for your life
分词如下:
{ "tokens":[
{ "token":"fight","start_offset":1,"end_offset":6,"type":"<ALPHANUM>","position":1},<br>
{ "token":"your","start_offset":,"end_offset":,"type":"<ALPHANUM>","position":3},<br>
{ "token":"life","start_offset":,"end_offset":,"type":"<ALPHANUM>","position":4}
]}
-------------------另一篇--------------------
ElasticSearch安装ik分词插件
一、IK简介
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从年月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在版本中,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
IK Analyzer 特性:
1.采用了特有的逗正向迭代最细粒度切分算法逗,支持细粒度和智能分词两种切分模式;
2.在系统环境:Core2 i7 3.4G双核,4G内存,window 7 位, Sun JDK 1.6_ 位 普通pc环境测试,IK具有万字/秒(KB/S)的高速处理能力。
3.版本的智能分词模式支持简单的分词排歧义处理和数量词合并输出。
4.采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符
5.优化的词典存储,更小的内存占用。支持用户词典扩展定义。特别的,在版本,词典支持中文,英文,数字混合词语。
二、安装IK分词插件
假设读者已经安装好ES,如果没有的话,请参考ElasticSearch入门 —— 集群搭建。安装IK分词需要的资源可以从这里下载,整个安装过程需要三个步骤:
1、获取分词的依赖包
通过git clone ,下载分词器源码,然后进入下载目录,执行命令:mvn clean package,打包生成elasticsearch-analysis-ik-1.2.5.jar。将这个jar拷贝到ES_HOME/plugins/analysis-ik目录下面,如果没有该目录,则先创建该目录。
2、ik目录拷贝
将下载目录中的ik目录拷贝到ES_HOME/config目录下面。
3、分词器配置
打开ES_HOME/config/elasticsearch.yml文件,在文件最后加入如下内容:
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_max_word:
type: ik
use_smart: false
ik_smart:
type: ik
use_smart: true
或
index.analysis.analyzer.default.type: ik
ok!插件安装已经完成,请重新启动ES,接下来测试ik分词效果啦!
三、ik分词测试
1、创建一个索引,名为index。
curl -XPUT
2、为索引index创建mapping。
curl -XPOST /fulltext/_mapping -d'
{
"fulltext": {
"_all": {
"analyzer": "ik"
},
"properties": {
"content": {
"type" : "string",
"boost" : 8.0,
"term_vector" : "with_positions_offsets",
"analyzer" : "ik",
"include_in_all" : true
}
}
}
}'
3、测试
curl '/_analyze?analyzer=ik&pretty=true' -d '
{
"text":"世界如此之大"
}'
显示结果如下:
{
"tokens" : [ {
"token" : "text",
"start_offset" : 4,
"end_offset" : 8,
"type" : "ENGLISH",
"position" : 1
}, {
"token" : "世界",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" : 2
}, {
"token" : "如此",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" : 3
}, {
"token" : "之大",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" : 4
} ]
}
jieba源码解析(一)——中文分词
全模式解析:
全模式下的中文分词通过构建字典树和DAG实现。首先加载字典,字典树中记录词频,例如词"不拘一格"在字典树中表示为{ "不" : 0, "不拘" : 0, "不拘一" : 0, "不拘一格" : freq}。接着构造DAG,表示连续词段的起始位置。例如句子'我来到北京清华大学',分词过程如下:
1. '我':字典树中key=0,尝试'我来',不在字典,结束位置0寻找可能的分词,DAG为 { 0:[0]}。
2. '来':字典树中key=1,尝试'来到',在字典,继续尝试'来到北',不在字典,结束位置1寻找可能的分词,DAG为 { 0:[0], 1:[1]}。
3. '到':字典树中key=2,尝试'来到北',不在字典,结束位置2寻找可能的分词,DAG为 { 0:[0], 1:[1], 2:[2]}。
4. 以此类推,最终形成所有可能分词结果:我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学。
全模式的关键代码涉及字典树和DAG的构建与使用。
精确模式与HMM模式解析:
精确模式与HMM模式对句子'我来到北京清华大学'的分词结果分别为:
精确模式:'我'/'来到'/'北京'/'清华大学'
HMM模式:'我'/'来到'/'了'/'北京'/'清华大学'
HMM模式解决了发现新词的问题。解析过程分为三个步骤:
1. 生成所有可能的分词。
2. 生成每个key认为最好的分词。
3. 按照步骤2的方式对每个key的结果从前面向后组合,注意判断单字与下个单字是否可以组成新词。
最后,解析结果为:我/ 来到/ 北京/ 清华/ 清华大学
HMM模式中的Viterbi算法在jieba中用于发现新词。算法通过统计和概率计算,实现新词的发现与分词。
具体应用中,HMM模型包含五个元素:隐含状态、可观测状态、初始状态概率矩阵、隐含状态转移概率矩阵、观测状态转移概率矩阵。模型利用这些元素实现状态预测与概率计算,进而实现中文分词与新词发现。
在Viterbi算法中,重要的是理解隐含状态、可观测状态、转移概率矩阵之间的关系,以及如何利用这些信息进行状态预测和概率计算。具体实现细节在代码中体现,包括字典树构建、DAG构造、概率矩阵应用等。
