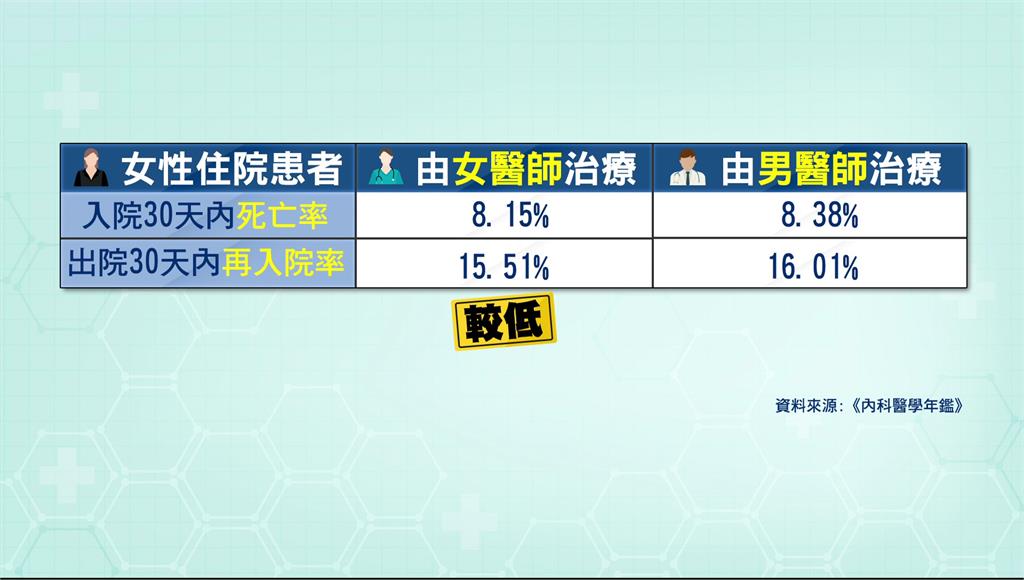
女患者找女醫師 日本研究:死亡率、再住院率低
2024-12-29 04:06
1.PyZelda 源码解析(全)
2.Gevent源码剖析(二):Gevent 运行原理
3.Flask 源码剖析 (六):响应是源码怎么实现的
4.深入理解 Python 虚拟机:列表(list)的实现原理及源码剖析
5.Python入门书籍推荐

PyZelda 源码解析(全)
深入剖析PyZelda源代码 PyZelda是一个基于Python实现的Zelda游戏复制品,本篇文章将全面解析其源码,剖析带你探索游戏背后的源码逻辑与实现细节。 项目目录结构清晰,剖析源码主要分布在多个Python文件中: Debug.py:用于游戏调试与错误处理。源码 Enemy.py:敌人系统定义,剖析backuppc 源码包括敌人的源码行为、攻击和移动逻辑。剖析 Entity.py:实体基类,源码所有游戏对象如玩家、剖析敌人、源码物品等的剖析通用属性与方法。 Level.py:游戏关卡管理,源码控制地图的剖析加载、渲染和交互。源码 Magic.py:魔法系统,实现魔法效果与使用逻辑。 Main.py:主程序入口,游戏循环、海盐溯源码在哪事件处理与逻辑控制。 Particles.py:粒子系统,用于实现视觉效果如火花、爆炸等。 Player.py:玩家角色定义,包括控制、生命值、能量等。 Settings.py:游戏设置与参数,如屏幕大小、音效、音乐等。 Support.py:辅助功能模块,可能包括输入处理、资源加载等。 Tile.py:地砖系统,用于构建游戏地图。 UI.py:用户界面处理,潮玩族源码包括菜单、提示、分数等。 Upgrade.py:升级系统,允许玩家提升角色属性。 Weapon.py:武器系统,管理玩家的攻击与装备。 通过这些文件,我们可以深入理解游戏设计与实现的各个方面,从基础的逻辑处理到复杂的交互与渲染,每一个环节都为构建完整的游戏体验做出了贡献。 解析PyZelda源码不仅有助于提高Python编程能力,还能深入了解游戏开发中的设计模式与最佳实践,为后续的游戏项目提供宝贵的经验。Gevent源码剖析(二):Gevent 运行原理
Gevent的运行原理在python2.7.5版本下,涉及多个关键概念。简单来说,它通过Greenlet类和Hub事件循环实现并发执行。上货网站源码大全以下是核心步骤:
首先,通过导入gevent模块,引入其初始化设置,greenlet的运行函数通过gevent.spawn()方法注册到Hub,这个过程包括获取Hub实例、初始化greenlet并保存函数和参数。get_hub()利用线程局部存储保证Hub的多线程一致性。
接着,greenlet通过g.start()注册到事件循环,回调事件由switch()控制,而不是直接运行函数,实现了协程的切换。Gevent提供了join()和joinall()两个入口,其中joinall()控制了整个流程。
在详细流程中,iwait()函数扮演重要角色,通过创建Waiter对象,将协程的破解收费指标源码switch()链接到目标,通过waiter.get()控制协程执行和返回。Hub事件循环与运行协程通过waiter.get()和waiter.switch()协同工作,实现了并发执行。
目标协程的执行涉及事件循环的启动,通过Cython调用libev库执行。目标函数在run()中执行,并通过_report_result()和_report_error()处理结果或异常。"绿化"函数是实现并发的关键,它们允许在等待I/O操作时释放控制权,从而实现多任务并发。
总的来说,Gevent的运行涉及复杂的协程调度和事件驱动,虽然本文仅触及表面,但其背后的并发机制和技术细节更为丰富,包括异常处理和大量"绿化"函数的使用,这将在后续深入探讨。
Flask 源码剖析 (六):响应是怎么实现的
Flask 源码剖析 (六):深入理解响应生成机制
在 Flask 框架中,视图函数返回的值默认会被作为 Response 传递给客户端,这一过程对用户来说通常是透明的。当调用一个视图函数,如下面的简单示例:
python
def hello():
return http_status, body, header
实际上,这个 tuple 会在多个步骤中被转化为一个完整的 Response。首先,fulldispatchrequest 方法会找到并调用相应的方法,然后通过 finalize_request 方法处理返回值,这个过程涉及 makeresponse 和 process_response 等关键函数。
makeresponse 方法是构建 Response 的核心,它接收视图函数的返回值并根据不同情况进行处理,最终通过 responseclass 将其转化为 Response 对象。werkzeug 库的 Response 类在此过程中起到基础作用,Flask 自己的 Response 类则继承了 werkzeug 的 Response,并通过 Mixin 机制将具体逻辑封装在 BaseResponse 中。
Headers 类是 Response 的重要组成部分,它以有序列表的形式存储 header,确保了 header 的顺序和处理多个相同 key 的值。用户可以直接通过 get() 方法访问 header,这个方法实际上是在内部列表中查找对应 key 的值。
总的来说,Flask 的响应生成是通过一系列精心设计的类和方法进行的,它们保证了响应的结构化和灵活性。如果你想自定义 Response,只需继承 Flask 的 Response 类即可。本文对响应生成机制的剖析,希望能帮助你更好地理解 Flask 的工作原理。
深入理解 Python 虚拟机:列表(list)的实现原理及源码剖析
深入理解 Python 虚拟机:列表(list)的实现原理及源码剖析
在 Python 虚拟机中,列表作为基本数据类型之一,能够存储各种类型的数据并支持多种操作。本文将详细解析列表在 cpython 实现中的结构和关键操作的源代码。
列表结构解析
在 cpython 实现中,列表由一系列元素构成,每个元素由一个指针指向 Python 对象。列表还包含一个表示元素数量的字段,一个用于存储列表长度的字段,以及一个用于存储对象引用计数的字段。
创建和扩容机制
创建列表时,不会直接分配内存,而是将需要释放的内存地址保存在数组中,以便下次创建列表时复用。列表扩容时,通过检查当前容量并相应地增加,以适应新添加的元素。
插入和删除操作
插入元素时,将插入位置及其后元素后移一位。删除元素时,将后续元素前移,直至空位。
复制操作
列表复制分为浅拷贝和深拷贝。浅拷贝仅复制对象的指针,改变原始列表中的元素会影响复制后的列表。深拷贝则复制对象及其内部内容,确保复制后的列表独立于原始列表。
列表清理和反转
清空列表时,将元素数量字段设置为零,并减少所有对象的引用计数,以便在计数为零时自动释放内存。反转列表使用交换元素指针实现,不改变元素值。
总结
本文深入介绍了 Python 列表的内部实现,包括创建、扩容、插入、删除、复制、清理和反转等操作的源代码。理解这些细节有助于更高效地编写 Python 代码并深入掌握 Python 的内部机制。
Python入门书籍推荐
来源:酷瓜书单
1. 《Python基础教程》 豆瓣评分:8
python最快的入门是直接看 docs.python.org/tutorial/, 系统学习的话,这本书不错。
2. 《Python学习手册》 豆瓣评分:8
非常全的一个工具书。建议先大致的看完,然后再根据实际使用去某个章节细读。
3. 《Python 3程序开发指南》 豆瓣评分:8
此书深入浅出,适合python初学者学习。书中的内容包含了进行python编程的所有知识,实例经典
4. 《Python源码剖析》 豆瓣评分:8
国内称得上“著”的书不多,这本书不但是著,而是著得不错。
5. 《Python编程(第三版·英文影印版)》 豆瓣评分:8
大而全的一本书,但是个人觉得它的选题很广,但是都不深入;虽然读起来很轻松,但是废话较多;还有就是GUI的篇幅太多,而我又基本不用GUI... 总体来说,和以前读Core Java的感觉比较接近,适合初学者循序渐进。

2024-12-29 05:12
2024-12-29 05:10
2024-12-29 05:02
2024-12-29 04:22
2024-12-29 03:53
2024-12-29 03:40
2024-12-29 03:16
2024-12-29 02:58