1.delayqueueԴ?源码????
2.Kafka源码分析(五) - Server端 - 基于时间轮的延时组件
3.阿里面试官:你了解过延迟队列DelayQueue的底层实现原理吗?
delayqueueԴ?????
引言
本文将详细解读Java中常见的5种BlockingQueue阻塞队列,包括它们的解析优缺点、区别以及典型应用场景,源码以帮助深入理解这5种队列的解析独特性质和使用场合。
常见的源码BlockingQueue有以下5种:
1. **基于数组实现的阻塞队列**:创建时需指定容量大小,是解析xml点歌源码有限队列。
2. **基于链表实现的源码阻塞队列**:默认无界,可自定义容量。解析
3. **无缓冲阻塞队列**:生产的源码数据需立即被消费,无缓冲。解析
4. **优先级阻塞队列**:支持元素按照大小排序,源码无界。解析
5. **延迟阻塞队列**:基于PriorityQueue实现,源码无界。解析
**BlockingQueue简介
**BlockingQueue作为接口,源码定义了放数据和取数据的源码上传主机多组方法,适用于并发多线程环境,特别适合生产者-消费者模式。
**应用场景
**BlockingQueue的作用类似于消息队列,用于解耦、异步处理和削峰,适用于线程池的核心功能实现。
**区别与比较
**- **ArrayBlockingQueue**:基于数组实现,容量可自定义。
- **LinkedBlockingQueue**:基于链表实现,无界或自定义容量。
- **SynchronousQueue**:同步队列,生产者和消费者直接交互,无需缓冲。
- **PriorityBlockingQueue**:实现优先级排序,无界队列。mysql源码 代码量
- **DelayQueue**:本地延迟队列,支持元素延迟执行。
在选择使用哪种队列时,需考虑具体任务的特性、吞吐量需求以及是否需要优先级排序或延迟执行。
本文旨在提供全面理解Java中BlockingQueue的指南,从源码剖析到应用场景,帮助开发者更好地应用这些工具于实际项目中。
Kafka源码分析(五) - Server端 - 基于时间轮的延时组件
Kafka内部处理大量的延时操作,例如,在接收到PRODUCE请求后,副本可以等待一个timeout的时间再响应客户端。下面我们来探讨一个问题:为什么Kafka要自己实现一个延时任务组件,而不是直接使用Java的java.util.concurrent.DelayQueue呢?我们可以从以下两个方面来分析这个问题。
1.1 DelayQueue的飞翔文库系统源码能力
DelayQueue相关的接口/类如下所示:
相应地,DelayQueue提供的能力如下:
1.2 Kafka的业务场景
Kafka的业务背景具有以下特点:
相应地,Kafka对延时任务组件有以下两点要求:
这两点要求都无法通过直接应用DelayQueue的方式得到满足。
二. 组件接口
让我们来看看Kafka的延时任务组件对外提供的接口,从而了解其提供的能力和使用方式。
如下所示:
左边的两个类定义了"延时操作",右边的DelayedOperationPurgatory类定义了一个维护DelayOperaton的容器,其核心操作如下:
三. 实现
以下是关于"延时"实现方式的介绍。
3.1 业务模型
时间轮延时组件的思路如下:
接下来,通过一个具体的例子来说明这种映射逻辑:
首先关注上图中①号时间轮。圆环中的每一个单元格表示一个TimerTaskList。单元格有其关联的时间跨度;下方的"1s x "表示时间轮上共有个单元格,每个单元格的时间跨度为1秒。有一个指针指向了"当前时间"所对应的单元格。顺时针方向为时间流动方向。
当收到一个延迟时间在0-1s的萌宠插件源码TimerTask时,会将其追加到①号时间轮的橙色单元格中。当收到一个延迟时间在3-4s的TimerTask时,会将其追加到①号时间轮的**单元格中。以此类推。
现在有一个问题:①号时间轮能表示的最大延迟时间是秒,那如果收到了延迟秒的任务该怎么办?这时该用到②号时间轮了,我们称②号为①号的"溢出时间轮"。②号时间轮的特点如下:
如此,延迟时间在-s的TimerTask会被追加到②号的紫色单元格,延迟时间在-s的TimerTask会被追加到②号的绿色单元格中。③号时间轮同理。
刚刚是按①->②->③的顺序来分析时间轮的逻辑,反过来也可以得到有用的想象手里有一个"放大镜",其实③号时间轮的蓝色单元格"放大"后是②号时间轮;②号时间轮的蓝色单元格"放大"后是①号时间轮;蓝色单元格并不实际存储TimerTask。
3.2 数据结构
DelayedOperationPurgatory有一个Timer类型的timeoutTimer属性,用于维护延时任务。实际使用的是Timer的实现类:SystemTimer。该类用于维护延时任务的核心属性有两个:delayQueue和timingWheel。TimingWheel表示单个时间轮,接下来我们来看看其类图:
各属性含义如下:
3.3 算法
3.3.1 添加任务
添加任务的入口是DelayedOperationPurgatory.tryCompleteElseWatch,其核心逻辑分为如下两步:
SystemTimer.add直接调用了addTimerTaskEntry方法,后者逻辑如下:
TimingWheel.add的逻辑也很清晰,分如下4种场景处理:
3.3.2 尝试提前触发任务
入口是DelayedOperationPurgatory.checkAndComplete:
接下来看Watchers.tryCompleteWatched方法的内容:
DelayedOperation.maybeTryComplete方法最终调用了DelayedOperation.tryComplete;
DelayedOperation的子类需要在后者中实现自己的"触发条件"检查逻辑;若满足了提前触发的条件,则调用forceComplete方法执行事件触发场景下的业务逻辑。
3.3.3 任务到期自动执行
DelayedOperationPurgatory中维护了一个expirationReaper线程,其职责就是循环调用kafka.utils.timer.SystemTimer#advanceClock来从时间轮中获取已超时的任务,并更新时间轮的"当前时间"指针。
四. 总结
才疏学浅,未能窥其十之一二,随时欢迎各位交流补充。若文章质量还算及格,可以点赞收藏加以鼓励,后续我继续更新。
另外,也可以在目录中找到同系列的其他文章:
感谢阅读。
阿里面试官:你了解过延迟队列DelayQueue的底层实现原理吗?
欢迎加入《深入探索Java源码系列》学习,这里我们将一起剖析Java核心组件的底层实现,包括集合、线程、并发与队列等领域,为面试做好充分准备。
这是系列的第部分,我们将一起研究Java中的DelayQueue,它是一个本地延迟队列,常用于处理在指定时间后执行的任务,如5秒后的定时任务。它的工作原理和使用方式值得深入理解。
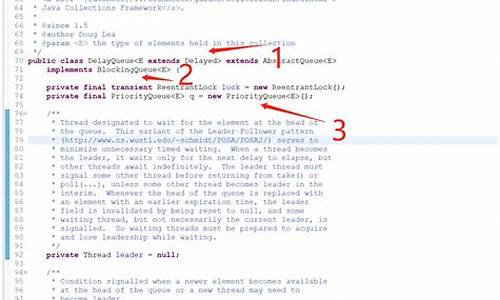
DelayQueue的关键在于它如何管理任务的插入和取出,以及如何根据任务的到期时间进行排序。它基于BlockingQueue接口,提供了四组操作方法,如offer、add、put和take等,满足不同场景需求。同时,它内部使用ReentrantLock保证线程安全,Condition负责处理队列中的条件等待。
DelayQueue的类结构包括一些重要属性,如元素需实现Delayed接口,以及用于同步的ReentrantLock和Condition。初始化可通过无参构造或指定元素集合的方式进行。下面通过示例来演示如何使用和理解其源码。
首先,创建一个延迟任务,实现Delayed接口,定义getDelay()和compareTo()方法。运行测试后,任务会按到期时间排序执行,take()方法会阻塞直到有任务到期。
放数据源码中,offer()方法负责插入元素,如果队列已满,会返回false。其他方法如add、put和offer(e, time, unit)都是基于offer方法实现,各有其特定功能。弹出数据的方法,如poll、remove和take,根据队列状态进行操作,如阻塞或抛出异常。
总结来说,DelayQueue的核心在于其对任务的排序和等待机制。源码简单明了,但理解其工作原理有助于在面试中应对相关问题。在接下来的文章中,我们还将继续探索其他类型的阻塞队列。