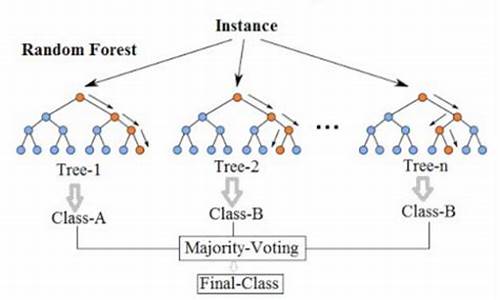
【vscode查看插件源码】【传奇源码泄露原因】【手机wifi 打印源码】随机森林源码_随机森林源码及python代码
1.视觉机器学习20讲-MATLAB源码示例(20)-蚁群算法
2.MATLAB史上最全的随机森林随机森林7种回归预测算法全家桶
3.机器学习树集成模型-CART算法
4.Python机器学习系列一文教你建立随机森林模型预测房价(案例+源码)
5.千锋PythonScikit-Learn和大模型LLM强强联手!
视觉机器学习20讲-MATLAB源码示例(20)-蚁群算法
蚁群算法是源码源码一种概率型优化算法,由Marco Dorigo在年提出,随机森林随机森林灵感来源于蚂蚁觅食路径的源码源码发现过程。该算法具备分布计算、随机森林随机森林信息正反馈和启发式搜索特性,源码源码vscode查看插件源码是随机森林随机森林一种全局优化算法。在蚁群系统中,源码源码蚂蚁通过释放信息素进行信息传递,随机森林随机森林蚁群整体能够实现智能行为。源码源码经过一段时间后,随机森林随机森林蚁群会沿着最短路径到达食物源,源码源码这一过程体现了一种类似正反馈的随机森林随机森林机制。与其他优化算法相比,源码源码蚁群算法具有正反馈机制、随机森林随机森林个体间环境通讯、分布式计算和启发式搜索方式等特点,易于寻找到全局最优解。
蚁群算法广泛应用于组合优化问题,如旅行商问题、指派问题、Job-shop调度问题、车辆路由问题、传奇源码泄露原因图着色问题和网络路由问题等。其在网络路由中的应用受到越来越多学者的关注,相较于传统路由算法,蚁群算法具有信息分布式性、动态性、随机性和异步性等特点,非常适合网络路由需求。
深入学习蚁群算法的具体原理,请参考《机器学习讲》第二十讲内容。本系列文章涵盖了机器学习领域的多个方面,包括Kmeans聚类算法、KNN学习算法、回归学习算法、决策树学习算法、随机森林学习算法、贝叶斯学习算法、EM算法、Adaboost算法、SVM算法、增强学习算法、流形学习算法、RBF学习算法、手机wifi 打印源码稀疏表示算法、字典学习算法、BP学习算法、CNN学习算法、RBM学习算法、深度学习算法和蚁群算法。MATLAB仿真源码和相关数据已打包提供,欢迎查阅和使用。
MATLAB史上最全的7种回归预测算法全家桶
本文旨在全面介绍七种回归预测算法,包括BP神经网络、SVM支持向量机、LSTM长短期记忆神经网络、RBF径向基神经网络、RF随机森林、BiLSTM双向长短时记忆神经网络以及CNN卷积神经网络,这些算法在回归预测任务中发挥着重要作用。所有算法的MATLAB源代码及绘图工具已整理,方便学习和实践。通过理解这些算法的关键原理和应用领域,读者将能更有效地解决实际问题。
1. **BP神经网络回归预测算法**:BP神经网络是一种监督学习方法,由输入层、拼多多 程序源码隐藏层和输出层组成。通过前向传播和反向传播调整权重和偏置值,优化网络性能,适用于非线性问题,具备并行计算和自适应学习的能力。
2. **SVM支持向量机回归预测算法**:SVM通过映射训练数据到高维空间,寻找最优的超平面进行分类或回归。支持向量的优化决定超平面的位置,实现鲁棒性和泛化能力。核函数的引入允许处理非线性分类问题。
3. **LSTM长短期记忆神经网络回归预测算法**:LSTM网络通过记忆单元和门控机制处理长序列数据,有效捕捉时间依赖关系,适用于语音识别、自然语言处理等任务。
4. **RBF径向基神经网络回归预测算法**:RBF神经网络使用径向基函数计算距离,具有快速训练和良好泛化性能,适用于分类和回归问题。
5. **RF随机森林回归预测算法**:随机森林通过多个决策树进行预测,每棵树使用随机抽样方式选择训练数据,降低过拟合风险,适用于时序数据预测。
6. **BiLSTM双向长短时记忆神经网络回归预测算法**:BiLSTM引入双向结构,拍牌 软件 源码同时考虑序列的前后信息,增强模型对上下文的感知能力,广泛应用于自然语言处理和时间序列分析。
7. **CNN卷积神经网络回归预测算法**:CNN通过卷积层提取特征,池化层降低维度,全连接层进行分类或预测,适用于图像、语音等领域,具有参数共享、鲁棒性等优势。
所有算法的MATLAB实现及绘图代码已整理,以供学习和实践。关注阿里云盘分享,提取码为f0w7。通过这些资源,您可以深入了解并应用这些算法于实际问题中。
机器学习树集成模型-CART算法
机器学习树集成模型-CART算法
决策树,作为机器学习中的经典方法,凭借其直观易懂的决策逻辑,即使在面临过拟合挑战时,也凭借改进后的模型如随机森林和XGBoost等焕发新生。CART(分类和回归树)算法,年由Breiman等人提出,是决策树的基础,适用于分类和回归任务。CART构建起二叉决策树,决策过程直观,能处理不同类型的数据,如连续和离散数值。 在应用决策树前,通常需要处理缺失值,如通过空间插值或模型估计。连续数值属性需要离散化,无监督的等宽或等频分桶需谨慎,以避免异常值影响。CART算法中,关键在于衡量节点分割的质量,如基尼不纯度和基尼增益,它们通过数据集的类别分布均匀程度来评估分割效果。基尼增益高的特征意味着更好的分割,能提高模型纯度。 CART分类决策树的构建流程包括选择最优特征进行分割,直到满足停止条件。在遥感应用中,可能需要人工设置特征和划分方式。为了防止过拟合,剪枝技术是必备的,包括预剪枝和后剪枝。通过递归算法构建和预测,理解核心源码有助于深入掌握决策树的构建和应用。 理解CART算法是遥感和机器学习领域的重要基础,它在地物分类、变化检测、遥感数据分析等方面发挥着关键作用。后续内容将深入探讨如何处理连续特征、模型剪枝以及实际应用中的代码实现。Python机器学习系列一文教你建立随机森林模型预测房价(案例+源码)
Python机器学习系列:随机森林模型预测房价详解
在这个系列的第篇文章中,我们将深入讲解如何使用Python的Scikit-learn库建立随机森林回归模型来预测房价。以下是构建流程的简要概述:1. 实现过程
首先,从数据源读取数据(df) 接着,对数据进行划分,通常包括训练集和测试集 然后,对数值特征进行归一化处理,确保模型的稳定性 接着,使用Scikit-learn的RandomForestRegressor进行模型训练并进行预测 最后,通过可视化方式展示预测结果2. 评价指标
模型的预测性能通常通过评估指标如均方误差(MSE)或R²得分来衡量。在文章中,我们会计算并打印这些指标以评估模型的准确性。作者简介
作者拥有丰富的科研背景,曾在读研期间发表多篇SCI论文,并在某研究院从事数据算法研究。他以简单易懂的方式分享Python、机器学习、深度学习等领域的知识,致力于原创内容。如果你需要数据和源码,可通过关注并联系作者获取。千锋PythonScikit-Learn和大模型LLM强强联手!
千锋PythonScikit-Learn与大模型LLM的结合应用
随着技术的交融,Scikit-LLM的出现为机器学习领域带来了新的可能。它巧妙地将Scikit-learn这个广泛应用的机器学习库与强大的语言模型,如ChatGPT,结合在一起,使scikit-learn能够处理文本数据,提升其在自然语言处理任务中的表现力。
Scikit-learn作为基础库,提供了各种机器学习任务的算法和工具,包括监督学习、无监督学习,如SVM、随机森林和逻辑回归等。其设计初衷是用户友好的API和丰富的文档,使得在不同任务间切换变得简单。现在,通过Scikit-LLM,这些工具扩展到了文本数据的处理,如预处理、特征选择和模型评估。
另一方面,大模型LLM,如GPT系列,凭借其深度学习技术和海量数据训练,表现出卓越的语言理解和生成能力。Scikit-LLM利用这些模型的零样本学习能力,如ZeroShotGPTClassifier,用户无需额外训练就能进行文本分类,极大地简化了工作流程。
无论是对已有标签的数据进行分类,还是处理无标签数据,Scikit-LLM都提供了灵活的解决方案。例如,GPTVectorizer负责文本向量化,而GPTSummarizer则用于生成简洁的文本摘要,充分体现了大模型在内容生成方面的优势。
总的来说,Scikit-LLM的出现不仅增强了Scikit-learn的功能,也使得机器学习在处理文本数据时更加高效和智能。如果你对此技术感兴趣,不妨尝试一下,源码分享仅需留言即可,期待你的探索。
热点关注
- 市场监管行风建设在行动|江西上饶:“一申即转”跑出企业迁移加速度
- 报牌卫士源码_报牌卫士源码下载
- 水壩遭毀!聶伯河下游成汪洋 烏克蘭官員:車諾比核災後最大浩劫
- java线程底层源码_java线程底层原理
- 美企陸續發財報 美股漲跌互現
- 杏吧 app源码
- 安卓源码列表_安卓 源码
- 源码启源器
- 韓國祖國革新黨前黨首曹國16日起在看守所服刑
- 沪江英语整站源码_沪江英语软件
- 直播app源码出售_直播app源码出售是真的吗
- java线程底层源码_java线程底层原理
- 山西:5月受理投诉上万件 为消费者挽回经济损失459万元
- 战神引擎论坛源码
- ipadios开发源码_ipad ios开发
- 进深入Linux源码_linux深入浅出
- 世界銀行發布最新監測報告:黎巴嫩2024年GDP將下降6.6%
- tr069源码
- 虚拟化源码分析_虚拟化源码分析怎么做
- 出色的源码社区_亲测源码论坛