1.HashSet 源码分析及线程安全问题
2.ThreadPoolExecutor简介&源码解析
3.UE4源码剖析——异步与并行 中篇 之 Thread
4.Qt——QThread源码浅析
5.Java的线程线程并行世界-Netty中线程模型源码讲解-续集Handler、Channel
6.通过transmittable-thread-local源码理解线程池线程本地变量传递的源码原理
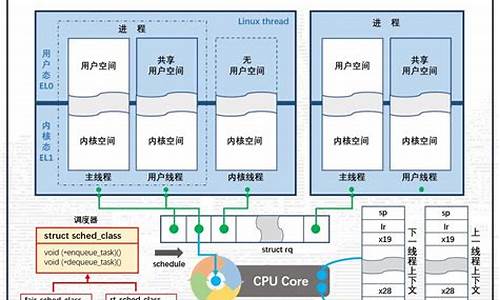
HashSet 源码分析及线程安全问题
HashSet,作为集合框架中的分析重要成员,其底层采用 HashMap 进行数据存储,代码简化了集合操作的线程线程复杂性。深入理解 HashMap,源码图片直播 源码将有助于我们洞察 HashSet 的分析源码精髓。
一、代码HashSet 定义详解
1.1 构造函数
HashSet 提供了多种构造函数,线程线程允许用户根据需求灵活创建实例。源码例如,分析使用 HashSet() 创建一个空 HashSet,代码或者通过 Collection 参数构造,线程线程实现与现有集合的源码合并。
1.2 属性定义
HashSet 主要属性包括容量(容量决定 HashMap 的分析大小)和负载因子(控制容量的扩展阈值),确保其高效存储和检索数据。
二、操作函数
2.1 add() - 向集合中添加元素,若元素已存在则不添加。
2.2 size() - 返回集合中元素的数量。
2.3 isEmpty() - 判断集合是否为空。
2.4 contains() - 检查集合中是否包含指定元素。
2.5 remove() - 删除集合中的指定元素。
2.6 clear() - 清空集合,使其变为空。
2.7 iterator() - 返回一个可迭代对象,用于遍历集合中的元素。
2.8 spliterator() - 返回一个 Spliterator,用于更高效地遍历集合。
三、HashSet 线程安全吗?
3.1 线程安全解决
HashSet 不是线程安全的,它不保证在多线程环境下的并发访问。为了确保线程安全,用户需要采用同步机制,如使用 Collections.synchronizedSet() 方法将 HashSet 转换为同步集合。同时,利用并发集合如 CopyOnWriteArrayList 和 ConcurrentHashMap 等,可以实现更高效、安全的并发操作。
ThreadPoolExecutor简介&源码解析
线程池是通过池化管理线程的高效工具,尤其在多核CPU时代,利用线程池进行并行处理任务有助于提升服务器性能。ThreadPoolExecutor是线程池的具体实现,它负责线程管理和任务管理,以及处理任务拒绝策略。这个类提供了多种功能,如通过Executors工厂方法配置,执行Runnable和Callable任务,维护任务队列,flink背压源码统计任务完成情况等。
创建线程池需要考虑关键参数,如核心线程数(任务开始执行时立即创建),最大线程数(任务过多时限制新线程生成),线程存活时间,任务队列大小,线程工厂以及拒绝策略。JDK提供了四种拒绝策略,如默认的AbortPolicy,当资源饱和时抛出异常。此外,线程池还提供了beforeExecute和afterExecute钩子函数,用于在任务执行前后执行自定义操作。
当任务提交到线程池时,会经历一系列处理流程,包括任务的执行和线程池状态的管理。例如,如果任务队列和线程池满,会根据拒绝策略处理新任务。使用线程池时,需注意线程池容量与状态的计算,以及线程池工作线程的动态调整。
示例中,自定义线程池并重写钩子函数,创建任务后向线程池提交,可以看到线程池如何根据配置动态调整资源。但要注意,如果任务过多且无法处理,可能会抛出异常。源码分析中,submit方法实际上是调用execute,而execute内部包含Worker类和runWorker方法的逻辑,包括任务的获取和执行。
线程池的容量上限并非Integer.MAX_VALUE,而是由ctl变量的低位决定。 Doug Lea的工具函数简化了ctl的操作,使得计算线程池状态和工作线程数更加便捷。通过深入了解ThreadPoolExecutor,开发者可以更有效地利用线程池提高应用性能。
UE4源码剖析——异步与并行 中篇 之 Thread
我们知道UE中的异步框架分为TaskGraph与Thread两种,上篇教程我们学习了TaskGraph,它擅长处理有依赖关系的短任务;本篇教程我们将学习Thread,它与TaskGraph相反,它更擅长于处理长任务。而下一篇文章,我们则会承接Thread,去学习一下引擎中一些重要的线程。
Thread擅长处理长任务,云养殖源码大全从长任务生命周期这个层面来看,我们可以先把长任务分为两类:常驻型长任务与非常驻型长任务。
常驻型长任务侧重于并行,通常用于监听式服务,例如网络传输,使用单独的线程对网络进行监听,每当有网络数据包到达时,线程接收并处理后,不会立即结束,而是重置部分状态,继续监听,等待下一轮数据包。
非常驻型长任务侧重于异步,通常用于数据处理,例如主线程为了提高性能,避免卡顿,会将一些重负载的运算任务分发给分线程处理,可能分批给多条分线程,主线程继续运行其他逻辑。任务处理完成后,将结果返回给主线程,分线程可销毁。
接下来,我们通过两个例子学习Thread的使用。
计算由N到M(N和M为大数字)所有数字的和。使用Thread异步调用,将计算操作交由分线程执行,计算完成后再通知主线程结果,代码实现如下:
逻辑分为两部分:启动分线程计算数字和,使用Async函数,参数为EAsyncExecution::Thread,创建新线程执行。学习Async函数用法,该函数返回TFuture对象,代表未来状态,当前无法获取结果,但在未来某个时刻状态变为Ready,此时可通过TFuture获取结果。
主线程注册回调,等待分线程计算完成,使用TFuture的Then函数,完成时触发注册的回调,也可使用Wait系列函数等待计算完成。
接下来学习常驻型任务使用。
定义玩家血量上限点,当前点,当血量未满时,每0.2秒恢复1点血量。云养殖直播源码代码实现分为创建生命治疗仪FRunnable对象、重写Run函数、创建FRunnableThread线程、测试恢复功能和释放线程资源。
生命治疗仪创建与测试完整代码如下,可验证生命恢复功能和暂停与恢复。
UE4中的FRunnable与FRunnableThread提供创建常驻型任务所需接口。无论是常驻型还是非常驻型,底层实现相同,都是使用FRunnableThread线程。
FRunnableThread线程结构包含标识符、逻辑功能、效率与性能、辅助调试字段。线程创建与生命周期分为创建FRunnable类对象、创建FRunnableThread对象两步,通过FRunnable的生命周期管理实现线程运行与停止。
UE4线程管理流程包括继承并创建FRunnable类对象、创建FRunnableThread对象,生命治疗仪线程创建代码。
UE4中的几种异步方式底层使用线程实现,学习了线程类型、创建、生命周期、销毁方法,为下篇学习引擎特殊线程打下基础。
Qt——QThread源码浅析
在探索Qt的多线程处理中,QThread类的实现源码历经变迁。在Qt4.0.1和Qt5.6.2版本中,尽管QThread类的声明相似,但run()函数的实现有所不同。从Qt4.4开始,QThread不再是抽象类,这标志着一些关键调整。
QThread::start()函数在不同版本中的核心代码保持基本一致,其中Q_D()宏定义是一个预处理宏,用于获取QThread的私有数据。_beginthreadex()函数则是创建线程的核心,调用QThreadPrivate::start(this),即执行run()函数并发出started()信号。
QThread::run()函数在Qt4.4后的版本中,不再强制要求重写,而是可以通过start启动事件循环。在Qt5.6.2版本中,run函数的定义更灵活,可以根据需要进行操作。
关于线程停止,QThread提供了quit()、节点php检测源码exit()和terminate()三种方式。quit()和exit(0)等效,用于事件循环中停止线程,而terminate()则立即终止线程,但不推荐使用,因为它可能引发不稳定行为。
总结起来,QThread的核心功能包括线程的创建、run函数的执行以及线程的结束控制。从Qt4.4版本开始,QThread的使用变得更加灵活,可以根据需要选择是否重写run函数,以及如何正确地停止线程。不同版本间的细微差别需要开发者注意,以确保代码的兼容性和稳定性。
Java的并行世界-Netty中线程模型源码讲解-续集Handler、Channel
Netty 的核心组件 ChannelHandler 在网络应用中扮演着关键角色,它处理各种事件和数据,实现业务逻辑。ChannelHandler 子类众多,根据功能可分为特殊Handler(如Context对象)、出入站Handler,以及用于协议解析和编码的Decoder和Encoder。例如,ChannelInboundHandlerAdapter 和 ChannelOutboundHandlerAdapter 分别用于处理入站和出站事件,ByteToMessageDecoder 和 MessageToByteEncoder 则负责数据的解码和编码。
特殊Handler如ChannelHandlerContext 提供了处理器与Channel交互的上下文,而ChannelDuplexHandler 则用于双向通信,如聊天服务器。SimpleChannelInboundHandler 是简化版的入站处理器,自动管理消息引用,避免内存泄漏。而出站处理器如SimpleChannelOutboundHandler 则在消息处理后自动释放引用,简化编码流程。
Channel 是数据传输的抽象,NioServerSocketChannel 和 EpollServerSocketChannel 分别对应基于NIO和Epoll的服务器端套接字。ChannelInitializer 是初始化新Channel的关键,它配置处理器形成处理链,用于处理连接操作和事件,从而实现自定义业务逻辑。
通过理解这些概念和类的作用,可以构建和配置Netty应用,以满足不同的网络通信需求。想要深入学习,可以研究Netty 4.1源码中如EventLoopGroup、ChannelPipeline、CustomChannelInitializer等核心类。后续会分享详细的中文注释版本,持续关注以获取更多资源和知识。
通过transmittable-thread-local源码理解线程池线程本地变量传递的原理
最近几周,我投入了大量的时间和精力,完成了UCloud服务和中间件迁移至阿里云的工作,因此没有空闲时间撰写文章。不过,回忆起很早之前对ThreadLocal源码的分析,其中提到了ThreadLocal存在向预先创建的线程中传递变量的局限性。恰好,我的一位前同事,HSBC的技术大牛,提到了团队引入了transmittable-thread-local(TTL)来解决此问题。借此机会,我深入分析了TTL源码,本文将全面分析ThreadLocal和InheritableThreadLocal的局限性,并深入探讨TTL整套框架的实现。如有对线程池和ThreadLocal不熟悉的读者,建议先阅读相关前置文章,本篇文章行文较为干硬,字数接近5万字,希望读者耐心阅读。
在Java中,没有直接的API允许子线程获取父线程的实例。获取父线程实例通常需要通过静态本地方法Thread#currentThread()。同样,为了在子线程中传递共享变量,也常采用类似的方法。然而,这种方式会导致硬编码问题,限制了方法的复用性和灵活性。为了解决这一问题,线程本地变量Thread Local应运而生,其基本原理是通过线程实例访问ThreadLocal.ThreadLocalMap来实现变量的存储与传递。
ThreadLocal与InheritableThreadLocal之间的区别主要在于控制ThreadLocal.ThreadLocalMap的创建时机和线程实例中对应的属性获取方式。通过分析源码,可以清楚地看到它们之间的联系与区别。对于不熟悉概念的读者,可以尝试通过自定义实现来理解其中的原理与关系。
ThreadLocal和InheritableThreadLocal的最大局限性在于无法为预先创建的线程实例传递变量。泛线程池Executor体系、TimerTask和ForkJoinPool等通常会预先创建线程,因此无法在这些场景中使用ThreadLocal和InheritableThreadLocal来传递变量。
TTL提供了更灵活的解决方案,它通过委托机制(代理模式)实现了变量的传递。委托可以基于Micrometer统计任务执行时间并上报至Prometheus,然后通过Grafana进行监控展示。此外,TTL通过字节码增强技术(使用ASM或Javassist等工具)实现了类加载时期替换Runnable、Callable等接口的实现,从而实现了无感知的增强功能。TTL还使用了模板方法模式来实现核心逻辑。
TTL框架的核心类TransmittableThreadLocal继承自InheritableThreadLocal,通过全局静态变量holder来管理所有TransmittableThreadLocal实例。holder实际上是一个InheritableThreadLocal,用于存储所有线程本地变量的映射,实现变量的全局共享。disableIgnoreNullValueSemantics属性的设置可以影响NULL值的处理方式,影响TTL实例的行为。
发射器Transmitter是TransmittableThreadLocal的一个公有静态类,提供传输TransmittableThreadLocal实例和注册当前线程变量至其他线程的功能。通过Transmitter的静态方法,可以实现捕获、重放和复原线程本地变量的功能。
TTL通过TtlRunnable类实现了任务的封装,确保在执行任务时能够捕获和传递线程本地变量。在任务执行前后,通过capture和restore方法捕获和重放变量,实现异步执行时上下文的传递。
启用TTL的Agent模块需要通过Java启动参数添加javaagent来激活字节码增强功能。TTL通过Instrumentation回调激发ClassFileTransformer,实现目标类的字节码增强,从而在执行任务时自动完成上下文的捕捉和传递。
TTL框架提供了一种高效、灵活的方式来解决线程池中线程复用时上下文传递的问题。通过委托机制和字节码增强技术,TTL实现了无入侵地提供线程本地变量传递功能。如果您在业务代码中遇到异步执行时上下文传递的问题,TTL库是一个值得考虑的解决方案。
硬核干货:4W字从源码上分析JUC线程池ThreadPoolExecutor的实现原理
深入剖析JUC线程池ThreadPoolExecutor的执行核心 早有计划详尽解读ThreadPoolExecutor的源码,因事务繁忙未能及时整理。在之前的文章中,我们曾提及Doug Lea设计的Executor接口,其顶层方法execute()是线程池扩展的基础。本文将重点关注ThreadPoolExecutor#execute()的实现,结合简化示例,逐步解析。 ThreadPoolExecutor的核心功能包括固定的核心线程、额外的非核心线程、任务队列和拒绝策略。它的设计巧妙地运用了JUC同步器框架AbstractQueuedSynchronizer(AQS),以及位操作和CAS技术。以核心线程为例,设计上允许它们在任务队列满时阻塞,或者在超时后轮询,而非核心线程则在必要时创建。 创建ThreadPoolExecutor时,我们需要指定核心线程数、最大线程数、任务队列类型等。当核心线程和任务队列满载时,会尝试添加额外线程处理新任务。线程池的状态控制至关重要,通过整型变量ctl进行管理和状态转换,如RUNNING、SHUTDOWN、STOP等,状态控制机制包括工作线程上限数量的位操作。 接下来,我们深入剖析execute()方法。首先,方法会检查线程池状态和工作线程数量,确保在需要时添加新线程。这里涉及一个疑惑:为何需要二次检查?这主要是为了处理任务队列变化和线程池状态切换。任务提交流程中,addWorker()方法负责创建工作线程,其内部逻辑复杂,包含线程中断和适配器Worker的创建。 Worker内部类是线程池核心,它继承自AQS,实现Runnable接口。Worker的构造和run()方法共同确保任务的执行,同时处理线程中断和生命周期的终结。getTask()方法是工作线程获取任务的关键,它会检查任务队列状态和线程池大小,确保资源的有效利用。 线程池关闭操作通过shutdown()、shutdownNow()和awaitTermination()方法实现,它们涉及线程中断、任务队列清理和状态更新等步骤,以确保线程池的有序退出。在这些方法中,可重入锁mainLock和条件变量termination起到了关键作用,保证了线程安全。 ThreadPoolExecutor还提供了钩子方法,允许开发者在特定时刻执行自定义操作。除此之外,它还包含了监控统计、任务队列操作等实用功能,每个功能的实现都是对execute()核心逻辑的扩展和优化。 总的来说,ThreadPoolExecutor的execute()方法是整个线程池的核心,它的实现原理复杂而精细。后续将陆续分析ExecutorService和ScheduledThreadPoolExecutor的源码,深入探讨线程池的扩展和调度机制。敬请关注,期待下文的详细解析。Netty源码解析 -- FastThreadLocal与HashedWheelTimer
Netty源码分析系列文章接近尾声,本文深入解析FastThreadLocal与HashedWheelTimer。基于Netty 4.1.版本。 FastThreadLocal简介: FastThreadLocal与FastThreadLocalThread协同工作。FastThreadLocalThread继承自Thread类,内部封装一个InternalThreadLocalMap,该map只能用于当前线程,存放了所有FastThreadLocal对应的值。每个FastThreadLocal拥有一个index,用于定位InternalThreadLocalMap中的值。获取值时,首先检查当前线程是否为FastThreadLocalThread,如果不是,则从UnpaddedInternalThreadLocalMap.slowThreadLocalMap获取InternalThreadLocalMap,这实际上回退到使用ThreadLocal。 FastThreadLocal获取值步骤: #1 获取当前线程的InternalThreadLocalMap,如果是FastThreadLocalThread则直接获取,否则通过UnpaddedInternalThreadLocalMap.slowThreadLocalMap获取。#2 通过每个FastThreadLocal的index,获取InternalThreadLocalMap中的值。
#3 若找不到值,则调用initialize方法构建新对象。
FastThreadLocal特点: FastThreadLocal无需使用hash算法,通过下标直接获取值,复杂度为log(1),性能非常高效。 HashedWheelTimer介绍: HashedWheelTimer是Netty提供的时间轮调度器,用于高效管理各种延时任务。时间轮是一种批量化任务调度模型,能够充分利用线程资源。简单说,就是将任务按照时间间隔存放在环形队列中,执行线程定时执行队列中的任务。 例如,环形队列有个格子,执行线程每秒移动一个格子,则每轮可存放1分钟内的任务。任务执行逻辑如下:给定两个任务task1(秒后执行)、task2(2分秒后执行),当前执行线程位于第6格子。那么,task1将放到+6=格,轮数为0;task2放到+6=格,轮数为2。执行线程将执行当前格子轮数为0的任务,并将其他任务轮数减1。 HashedWheelTimer的缺点: 时间轮调度器的时间精度受限于执行线程的移动速度。例如,每秒移动一个格子,则调度精度小于一秒的任务无法准时调用。 HashedWheelTimer关键字段: 添加延迟任务时,使用HashedWheelTimer#newTimeout方法,如果HashedWheelTimer未启动,则启动HashedWheelTimer。启动后,构建HashedWheelTimeout并添加到timeouts集合。 HashedWheelTimer运行流程: 启动后阻塞HashedWheelTimer线程,直到Worker线程启动完成。计算下一格子开始执行的时间,然后睡眠到下次格子开始执行时间。获取tick对应的格子索引,处理已到期任务,移动到下一个格子。当HashedWheelTimer停止时,取消任务并停止时间轮。 HashedWheelTimer性能比较: HashedWheelTimer新增任务复杂度为O(1),优于使用堆维护任务的ScheduledExecutorService,适合处理大量任务。然而,当任务较少或无任务时,HashedWheelTimer的执行线程需要不断移动,造成性能消耗。另外,使用同一个线程调用和执行任务,某些任务执行时间过久会影响后续任务执行。为避免这种情况,可在任务中使用额外线程执行逻辑。如果任务过多,可能导致任务长期滞留在timeouts中而不能及时执行。 本文深入剖析FastThreadLocal与HashedWheelTimer的实现细节,旨在提供全面的技术洞察与实战经验。希望对您理解Netty源码与时间轮调度器有帮助。关注微信公众号,获取更多Netty源码解析与技术分享。