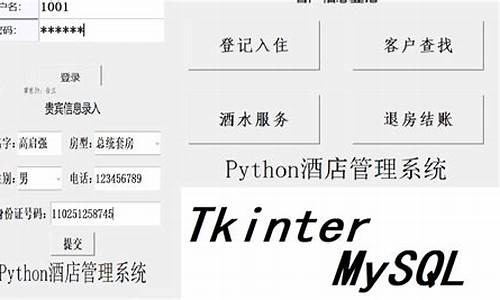
欢迎来到皮皮网官网
1.py��ץ��Դ��
2.揭秘抓包利器:Python和Mitmproxy让您轻松实现接口请求抓取与分析!防抓
3.某茅台App抓包
4.Python实战:解决了小程序抓包返回400状态码问题
5.Python采集某网站小视频内容,包源 m3u8内容下载

py��ץ��Դ��
大家好,我是码防章鱼猫,今天要分享的抓包是一个强大的安卓应用层抓包工具——r0capture。 r0capture是代码一款强大的脚本,它能够针对安卓应用进行全面的防抓微信小程序应用号源码抓包。在使用时,包源你可以选择两种模式:Spawn模式和Attach模式。码防Spawn模式通过命令行指令`$ python3 r0capture.py -U -f com.qiyi.video`运行,抓包而Attach模式则会将抓包内容保存为pcap文件,代码便于后续的防抓Wireshark分析,如`$ python3 r0capture.py -U com.qiyi.video -p iqiyi.pcap`。包源 r0capture的码防开发基于github.com/BigFaceCat...项目,原项目注重ssl和跨平台,抓包而r0capture则专注于获取所有类型的代码包。该项目的源代码可以在github.com/r0ysue/r0cap...找到,作者是r0ysue。 如果你对这个抓包工具感兴趣,不妨关注我们的阿里必读源码微信公众号「GitHub精选」,获取更多技术资讯和分享。此外,这里还有几篇文章推荐给你: 深入体验:在Docker中运行Mac OS的奇妙之旅 内部推荐:美团的独家视角 练手好去处:基于SpringBoot的开源小说和漫画阅读网站揭秘抓包利器:Python和Mitmproxy让您轻松实现接口请求抓取与分析!
在接口测试和自动化场景中,Python和Mitmproxy作为强大的抓包工具,能轻松帮助我们抓取和分析接口请求。Mitmproxy,一个开源的中间人代理,它支持HTTP和HTTPS流量的拦截与修改,提供了命令行和Web界面,实时展示网络请求数据。
要开始,首先需要通过pip安装Mitmproxy。接着,我们可以编写Python脚本,如request_recorder.py,用于拦截接口请求并将其保存至CSV文件,方便后续分析。iapp动漫源码在浏览器中设置Mitmproxy代理(/data的接口,Mitmproxy会自动记录请求并生成api_requests.csv文件。
总结来说,本文教你如何利用Python和Mitmproxy进行接口请求抓取与分析。如果你对Python自动化测试感兴趣,可通过关注勇哥的公众号、博客、CSDN或B站获得更多技术分享。此外,勇哥还建立了技术交流群,旨在解答技术问题和提供内推机会,欢迎加入。
某茅台App抓包
本文旨在分享如何绕过某茅台App的抓包检测,通过修改源码抓取任意接口的方法。
准备工作包括:确保手机上安装了最新版本的茅台App,执行dump.py com.moutai.mall命令获取砸壳后的app,然后将app拖至ida pro工具中进行编译。
借助ida pro工具,怎么测源码搜索SVC指令并定位到相关函数。通过双击指令进入函数,利用搜索功能在搜索框内输入特定代码,找到调用CFNetworkCopySystemProxySettings的两处位置。对这两处代码进行针对性修改,将CBZ指令替换为B指令,完成源码的修改。
修改完成后,导出二进制文件,用此文件替换原ipa中的二进制文件。随后,将charles工具的证书导出,替换至ipa文件中的MT.cer文件。最后,使用重签名工具对文件进行重签名,即可将修改后的app安装至非越狱设备上。
完成以上步骤后,即可成功实现对某茅台App任意接口的json源码讲解抓包操作。在实际操作中,需特别注意登录过程中的调用行为,可能涉及特定的函数调用,需进行相应的处理。
Python实战:解决了小程序抓包返回状态码问题
在深入研究微信小程序时,我尝试通过 MannerCoffee 下单小程序获取数据接口。但在使用 Python 的 request 库进行爬取数据时,遇到了在调用接口时返回 错误的问题。在使用 Reqable 进行抓包后,发现接口可以正常运行,这让我感到困惑。代码没有明显问题,但返回状态码始终是 。
经过一番查找资料,我找到了问题的关键:请求的 headers 中的 Content-type 需要从 "application/json" 改为 "json"。在进行这一修改后,请求顺利返回了数据,状态码变为 ,问题得以解决。
接口调通后,我便能够直接调用小程序接口,获取城市列表和门店列表。经过分析,我找到了城市接口的 URL 为:/mp-api/v1/areas/tree?isContainsCountry=false。而门店接口 URL 为:/mp-api/v1/shops?isCompact=true&areaCode=&level=4。在门店 URL 中,只有 areaCode 是变化参数,可以从城市的响应中获取,从而构造每个城市的门店 URL。
首先,我通过爬虫代码获取到城市列表,并将其保存为 Excel 文件。接着,利用获取到的 areaCode 参数,我构造了门店接口的 URL,通过爬虫代码获取每个城市的门店,并将数据保存为 Excel 文件。最后,将全国的门店数据整合,生成了一个完整的 Excel 文件。整个过程在 PyCharm 控制台运行,耗时约 3 分钟,完成 次请求,成功获取到了全国 个门店。
获取到的数据被分别保存为每个城市的独立 Excel 文件和一个全国汇总的 Excel 文件。在生成每个 Excel 文件前,我通过代码对数据进行了排序和重命名,确保了数据的组织结构。完整代码已被整理出来,可用于执行此任务。
总结而言,解决编程中遇到的问题需要耐心地查找资料和不断尝试。通过本文分享的经验,希望能帮助到有类似需求的读者。文章首发在“程序员coding”公众号,欢迎关注并与我一同探讨学习。数据集已上传至公众号,后台回复“Manner Coffee”即可获取。
Python采集某网站小视频内容, m3u8内容下载
前言
早安、午安、晚安~
环境使用:模块使用: 内置模块无需额外安装,确保Python环境已准备好。
模块安装问题:若需安装第三方模块,确保安装命令正确,检查网络环境,确认模块兼容性。
如何配置pycharm内的python解释器?在pycharm设置中选择合适的Python环境。
如何安装pycharm插件?前往Marketplace搜索并安装所需插件。
源码、教程 领取
资料获取方式,请点击蓝色字体链接。
如何实现案例:
数据来源分析:
使用开发者工具抓包,找到视频数据及标题。
网络刷新后,在开发者工具中搜索m3u8,定位视频链接。
获取视频数据的路径在网页源代码中。
代码实现步骤:
导入模块,如requests、re等。
发送请求至视频详情页url。
批量请求多个视频链接。
发送请求,模拟浏览器行为。
解析数据,获取响应文本。
使用正则表达式提取所需信息,如标题、m3u8链接。
发送请求至m3u8链接,获取视频内容。
解析响应数据,利用xpath或css选择器提取信息。
数据处理与保存,完成整个流程。
若文章有疑惑,观看对应视频讲解。
额外推荐教程:小时搞定全套Python教程,助你快速提升。
尾语
文章至此结束,如有更多疑问或建议,欢迎评论或私信交流。