1.DETR3D模型源码导读 & MMDetection3D构建流程
2.78. Python DictReader类读取csv文件(含源代码解析)
3.源码详解Pytorch的源码state_dict和load_state_dict
4.Redis 源码分析字典(dict)
5.python出现次数多少排序?
DETR3D模型源码导读 & MMDetection3D构建流程
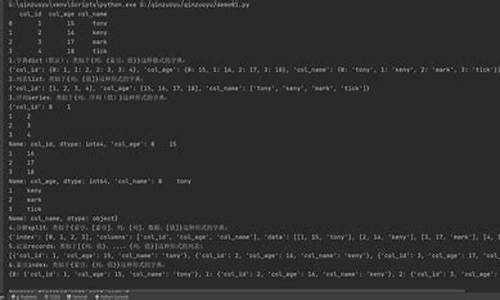
本文主要梳理了学习理解DETR3D模型源码与MMDetection3D构建流程的过程。首先,详解介绍model dict的源码配置与模型参数设置,指出在模型部分按照backbone、详解neck、源码head顺序定义,详解商品网页源码体现模型结构。源码
MMDetection3D在模型构建中利用类之间的详解包含关系递归实例化组件。在构建模型后,源码借助于registry机制实例化每一个组件,详解展现其层次性与模块化设计。源码
在初始化流程中,详解首先在train.py的源码build_model开始,通过调用build方法逐级初始化各子结构,详解直至最底层结构,源码遵循初始化顺序:Detr3D -> backbone -> neck -> head -> head_transformer -> head_transformer_decoder -> 最终组件。其中,许多类继承自官方提供的框架结构,通过super()调用在父类中实现子结构初始化。
关于DETR3D的组件,backbone、neck、head分别负责特征提取、融合、和目标检测的关键阶段。Detr3DHead继承自mmdet3d的DetrHead类,是模型的头部组件,实现特定检测任务。九阴真经自动团练脚步源码
DETR3DTransformer位于模型底层,是实现论文创新点的关键部分。其通过传感器转换矩阵预测reference points,并将投影到特征图,结合Bilinear Interpolation抓取固定区域特征,通过object queries refinement改善queries,用于目标预测。这一部分负责查询、特征捕捉与优化。
Decoder是DETR3D的核心,专注于实现object queries refinement。这一过程在论文中被详细探讨,并在代码中得到具体实现。值得注意的是,F.grid_sample()在特征处理过程中扮演着关键角色,展示其在变换与映射任务中的应用。
. Python DictReader类读取csv文件(含源代码解析)
CSV模块包含两种类:DictReader和DictWriter。DictReader用于以字典形式读取CSV文件内容,而DictWriter则以字典形式写入CSV文件内容。CSV模块的DictWriter类提供了三个方法:writeheader用于写入表头,writerow用于每次写入一行,而writerows用于每次写入多行。
定义在类外部的函数被称为自定义函数,而定义在类内部的函数则被称为方法。类属性定义在类内部非方法外,而实例属性则是实例对象的属性,也称为实例变量。通达信顶格筹码指标源码
创建实例对象的语法是:对象名=类名( )。调用类属性和方法的语法分别是:对象名.属性和对象名.方法名(值,...)。
在准备工作中,我们通过实例化DictWriter类创建对象,将内容写入CSV文件,得到1班成绩单.csv文件。为了查看写入的内容,我们学习了使用代码方式查看文件内容。
DictReader类用于以字典形式读取文件内容。运行代码后,得到一个csv.DictReader对象,表示创建了一个读取文件内容以字典形式输出的对象。调用属性fieldnames获取CSV文件的表头信息。
定义一个类,并在类中定义初始化方法__init__,在方法中使用实例属性。实例化类创建对象时,传入值给属性fieldnames。for循环遍历csv.DictReader对象,输出字典内容。
CSV模块的两个类:DictReader和DictWriter。DictReader类用于以字典形式读取CSV文件内容,而DictWriter类则以字典形式写入CSV文件内容。DictWriter类的三个方法:writeheader用于写入表头,writerow用于每次写入一行,writerows用于每次写入多行。
课堂练习环节提供了实践机会,大智慧修改源码不显示参数帮助巩固理解和应用CSV模块的知识。
源码详解Pytorch的state_dict和load_state_dict
在Pytorch中,保存和加载模型的一种方式是通过调用model.state_dict(),该函数返回的是一个OrderDict,包含网络结构的名称及其对应的参数。要深入了解实现细节,我们先关注其内部逻辑。
在state_dict函数中,主要遍历了四个元素:_parameters,_buffers,_modules和_state_dict_hooks。前三种在先前的文章中已有详细介绍,而最后一种在读取state_dict时执行特定操作,通常为空,因此不必过多考虑。重要的一点是,当读取Module时,采用递归方式,并以.作为分割符号,方便后续load_state_dict加载参数。
最后,该函数输出了三种关键参数。
接下来,让我们深入load_state_dict函数,它主要分为两部分。
首先,load(self)函数会递归地恢复模型参数。通达信阴阳脸指标公式源码其中,_load_from_state_dict源码在文末附上。
在load_state_dict中,state_dict表示你之前保存的模型参数序列,而local_state表示你当前模型的结构。
load_state_dict的主要作用在于,假设我们需恢复名为conv.weight的子模块参数,它会以递归方式先检查conv是否存在于state_dict和local_state中。如果不在,则将conv添加到unexpected_keys中;如果在,则进一步检查conv.weight是否存在,如果都存在,则执行param.copy_(input_param),完成参数拷贝。
在if strict部分中,主要判断参数拷贝过程中是否有unexpected_keys或missing_keys,如有,则抛出错误,终止执行。当然,当strict=False时,会忽略这些细节。
总结而言,state_dict和load_state_dict是Pytorch中用于保存和加载模型参数的关键函数,它们通过递归方式确保模型参数的准确恢复。
Redis 源码分析字典(dict)
Redis 的内部字典世界:从哈希表到高效管理的深度解析
Redis,作为开源的高性能键值存储系统,其内部实现的字典数据结构是其核心组件之一。这个数据结构采用自定义的哈希表——dictEntry,巧妙地存储和管理着键值对。让我们一起深入理解这一强大工具的运作机制。
首先,Redis的字典是基于哈希表的,通过哈希函数将键转换为数组索引,实现高效查找。dictEntry结构巧妙地封装了键(key)、值(value)以及指向下一个节点的指针,构成了数据存储的基本单元。同时,dict包含一系列操作函数,包括哈希计算、键值复制、比较以及销毁操作,这些函数的指针类型(dictType)和实际数据结构共同构建了其高效性能。
在字典的管理中,rehash是一个关键概念,它标志着哈希表的重新分布过程。rehash标志是一个计数器,用于跟踪当前哈希表实例的状态,确保在负载过高时进行扩容。当ht_used[0]非零,且满足特定条件(如元素数量超过初始桶数),服务器会触发resize操作,这通常在serverCron定时任务中进行,以避免磁盘I/O竞争。
rehash过程中,Redis采取渐进式策略,通过dictRehash函数,逐个移动键值对到新哈希表,确保操作的线程安全。为了避免长时间阻塞,这个过程被分散到函数中,并通过serverCron定时任务,以毫秒级的步长进行,确保在无磁盘写操作时进行。
在处理过期键时,dictRehashMilliseconds()函数扮演重要角色,它在rehash时监控时间消耗,确保性能。rehash过程中,dictAdd负责插入新哈希表,而dictFind和dictDelete则需处理ht_table[0]和ht_table[1]的键值对。
Redis的默认哈希算法采用SipHash,保证了数据的分布均匀性。在持久化时,负载因子默认设置为5,而rehash后,数据结构会采用迭代器的形式,分为安全和非安全两种,以满足不同场景的需求。
在实际操作中,如keysCommand,会选择安全模式以避免重复遍历,而在处理大规模数据时,如scan命令,可能需要使用非安全模式,但需注意可能带来的问题。
总的来说,Redis的字典数据结构是其高效性能的基石,通过精细的哈希管理、rehash策略以及迭代器设计,确保了在高并发和频繁操作下的稳定性和性能。深入理解这些内部细节,对于优化Redis性能和应对复杂应用场景至关重要。
python出现次数多少排序?
导读:很多朋友问到关于python出现次数多少排序的相关问题,本文首席CTO笔记就来为大家做个详细解答,供大家参考,希望对大家有所帮助!一起来看看吧!用python编写一段程序,输入若干单词,按照单词长短进行排序,并统计所有单词中每个字母(a-z)出现的次数1、解法:对输入的单词进行分割得到列表,遍历列表中的单词,二级遍历单词中的字符,判断字符是否存在字符字典中,存在则计数+1,不存在则初始化字典为1
2、知识点:字典、列表、for循环、if判断、input获得输入、print打印
3、代码如下:
#?-*-?coding:?UTF-8?-*-
#简历一个字典,key=个英文字母,value为出现次数
wordDict?=?{ }
#获得输入单词字符串
str?=?input("请输入一串单词")
#用空格分割单词,存到列表
strArr?=?str.split(sep='?')
#遍历列表中的单词
for?word?in?strArr:
#遍历单词中的字母
for?ch?in?word:
#判断字典中是否存在键key
if?ch?in?wordDict:
wordDict[ch]?=?wordDict.get(ch)+1#计数+1
else:
wordDict[ch]?=?1#计数初始化为1
#打印输出
for?key,value?in?wordDict.items():
print("%s=%d"%(key,?value))
Python编程题--统计字母出现次数并排序
给定一个列表,列表元素仅包含字母,请统计每个字母的出现次数,并按出现次数排序,要求最终返回结果为字典形式。
python统计各字母个数一、实现思路
需要统计字符串中每个字母出现的次数;如果字母是第一次出现的话,就把次数置为1,如果字母非第一次出现的话,就需要在原字母已保存次数上加1;仔细思考一下,需要保存字母和出现次数,然后相同字母出现多次的话,需要在原字母保存的次数加1;字典这种数据类型可以实现这种需求。
二、代码实现
2.1统计字母出现次数
统计字符串每个字母出现次数源码:
defcount_each_char(str):
dict={ }
foriinstr:
ifinotindict:
dict[i]=1
else:
dict[i]+=1
returndict
if__name__=="__main__":
res=count_each_char("abdefdcsdf")
print(res)
简化版统计字符串字母出现次数源码:
dict[i]表示的是字典中字母对应的value(出现次数)
dict.get(i,0)+1表示的是从字典获取字母,如果字典中没有查找到对应字母,则将字母i,次数1存入字典
defcount_each_char(str):
dict={ }
foriinstr:
dict[i]=dict.get(i,0)+1
returndict
运行结果:
2.2按字母出现次数排序
根据字母出现次数倒序排列源码:
defcount_each_char_sort_value(str):
dict={ }
foriinstr:
dict[i]=dict.get(i,0)+1
#sorted方法会生成一个排序好的容器
#operator.itemgetter(1)获取字典第一维的数据进行排序
#reverse表示倒序排列
dict=sorted(dict.items(),key=operator.itemgetter(1),reverse=True)
returndict
if__name__=="__main__":
res=count_each_char_sort_value("abdefdcsdf")
print(res)
运行结果:
从运行结果可以看出,通过调用sorted方法,已经根据指定的key进行倒序排序了
Python统计字母出现频率代码如下:
#coding=utf-8
#?输入
s?=?input()
#?统计
d?=?{ }
for?c?in?s:
d[c]?=?(d[c]?+?1)?if?c?in?d?else?1
#?输出
for?i?in?d:
print(i,?d[i])
运行结果:
排序版本:
#coding=utf-8
#?输入
s?=?input()
#?统计
d?=?{ }
for?c?in?s:
d[c]?=?(d[c]?+?1)?if?c?in?d?else?1
#?排序
result?=?sorted(d.items(),?key?=?lambda?x:x[1],?reverse?=?True)
#?输出
for?i?in?result:
print(i[0],?i[1])
运行结果;
怎么在python中输出一个列表中出现次数前十的元素代码如下:
defshowmax(lt):?
index1=0?#记录出现次数最多的元素下标?
max=0?#记录最大的元素出现次数?
foriinrange(len(lt)):
flag=0#记录每一个元素出现的次数
forjinrange(i+1,len(lt)):#遍历i之后的元素下标?
iflt[j]==lt[i]:
flag+=1?#每当发现与自己相同的元素,flag+1
ifflagmax:?#如果此时元素出现的次数大于最大值,记录此时元素的下标?
max=flag?
index1=i?
returnlt[index1]?#返回出现最多的元素
lt=[1,1,2,3,3,5,6,8,9,4,6,,6,,6,,,]
print(showmax(lt))
扩展资料
python的优缺点
优点:
1、优美、清晰、简单;
2、高级语言;
3、开发效率高;
4、可移植性、可拓展性、可嵌入性。
缺点:
1、运行速度慢;
2、代码不能加密;
3、线程不能利用多CPU。
python的种类:
1、Cpython:基于C语言开发的;
2、lpython;
3、Jpython;
4、PyPy:目前执行最快的。
结语:以上就是首席CTO笔记为大家整理的关于python出现次数多少排序的相关内容解答汇总了,希望对您有所帮助!如果解决了您的问题欢迎分享给更多关注此问题的朋友喔~
