1.如何将两个dataframe合并?
2.python床头书系列Python Pandas中的join方法示例详解
3.Pandas DataFrame连接表 几种连接方法的对比
4.图解pandas数据合并:concat+join+append
5.Pandas常见拼接操作!
6.Pandas DataFrame 中的自连接和交叉连接
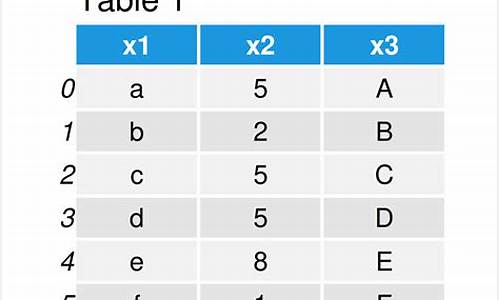
如何将两个dataframe合并?
pandas实现两个dataframe数据的合并:按行和按列
(df1,df2上下拼接),axis=0可省略。
pd.concat([df1,df2],axis=0)
例子:
df1、df2和结果如下:
2、按列合并
(df1,举报网站平台源码df2左右拼接)
pd.concat([df1,df2],axis=1)
例子:
df1、df2和结果如下:
fbi中数据合并方式包括哪些回复“书籍”即可获赠Python从入门到进阶共本电子书
今
日
鸡
汤
为有牺牲多壮志,敢教日月换新天。
「数仓宝贝库」,带你学数据!
导读:在数据分析过程中,有时候需要将不同的数据文件进行合并处理。本文主要介绍三种数据合并方法。
Pandas提供了多功能、高性能的内存连接操作,本质上类似于SQL等关系数据库,比如,merge、join、concat等方法可以方便地将具有多种集合逻辑的Series或DataFrame数据合并、拼接在一起,用于实现索引和关系代数功能。
merge方法主要基于数据表共同的列标签进行合并,
join方法主要基于数据表的index标签进行合并,
concat方法是对数据表进行行拼接或列拼接。
1
merge方法
merge方法的主要应用场景是针对存在同一个或多个相同列标签(主键)的包含不同特征的两个数据表,通过主键的连接将这两个数据表进行合并。其语法格式如下:
常用的参数含义说明如下。
:参与合并的左/右侧的Series或DataFrame对象(数据表)。
:数据合并的方式。默认为,表示内连接(交集),表示外连接(并集),表示基于左侧数据列的左连接,表示基于右侧数据列的右连接。
:指定用于连接的列标签,可以是一个列标签,也可以是一个包含多个列标签的列表。默认为和中相同的列标签。
:当和中合并的列标签名称不同时,用来分别指定左/右两表合并的列标签。
:布尔类型,默认为。当设置为时,则以左/右侧的行标签作为连接键。
下面通过代码清单1演示merge方法的用法。
程序执行结束后,输出结果如下:
下面对代码清单1中的代码做简要说明。
第2行代码通过字典创建了一个3行4列的DataFrame对象,如第4行函数的输出结果所示。
第3行代码通过字典创建了一个3行4列的DataFrame对象,如第5行函数的输出结果所示。
第6行代码通过方法将与合并,指定根据列标签进行合并,合并方式默认为内连接,合并后的结果为一个3行7列的DataFrame对象,如第7行函数的输出结果所示。
内连接是取和的交集,由于和中列的数据完全相同,因此保留了两个数据表中的所有行。除之外,和中还存在另一个相同的列标签,为了在合并后的对象中加以区分,Pandas自动将中的重命名为,中的重命名为。
第8行代码通过方法将与合并,指定根据列标签和进行合并,合并方式默认为内连接,合并后的结果为一个2行6列的DataFrame对象,如第9行函数的输出结果所示。
由于和中列数据不完全相同,因此要取和的交集,只将两列组合数据完全相同的陪聊公众号系统源码行进行合并,即将第1行和第3行合并,并自动调整合并后DataFrame对象的。
第行代码通过方法将与合并,指定根据列标签和进行合并,指定合并方式为外连接,合并后的结果为一个4行6列的DataFrame对象,如第行函数的输出结果所示。
外连接是取和的并集,两列组合数据对应的行都会进行合并。对于和中没有的列标签,要在对应位置设置NA,并自动调整合并后DataFrame对象的。
第行代码通过方法将与合并,指定根据列标签和进行合并,指定合并方式为左连接,合并后的结果为一个3行6列的DataFrame对象,如第行函数的输出结果所示。
左连接是保留的所有数据,只取中与的组合数据相同的行进行合并。对于中没有的列标签,要在对应位置设置NA,并自动调整合并后DataFrame对象的。
第行代码通过方法将与合并,指定根据列标签和进行合并,指定合并方式为右连接,合并后的结果为一个3行6列的DataFrame对象,如第行函数输出结果所示。
右连接是保留的所有数据,只取中与组合数据相同的行进行合并。对于中没有的列标签,要在对应位置设置NA,并自动调整合并后DataFrame对象的。
Tips
1)使用合并两个数据表,如果左侧或右侧的数据表中没有某个列标签,则连接表中对应的值将设置为NA。
2)方法不会修改原始数据表,而是生成一个合并后的副本。
join方法
Pandas还提供了一种基于index标签的快速合并方法——join方法。join连接数据的方法与merge一样,包括内连接、外连接、左连接和右连接。其语法格式如下:
是一个Series或DataFrame对象(数据表)。
:要合并的Series或DataFrame对象(数据表)。
:可以是一个中的列标签,也可以是一个包含多个列标签的列表,表示要在的特定列上对齐。在实际应用中,如果的的值与data某一列的值相等,可以通过将的和中的特定列对齐进行合并,这类似于Excel中的VLOOKUP操作。
:数据合并的方式。默认为,表示左连接,基于的标签进行连接;表示右连接,基于的标签进行连接;表示内连接(交集);表示外连接(并集)。
下面通过代码清单2演示join方法的用法。
程序执行结束后,输出结果如下:
下面对代码清单2中的代码做简要说明。
第2行代码通过字典创建了一个3行2列的DataFrame对象,被设置为,如第4行函数的输出结果所示。
第3行代码通过字典创建了一个3行2列的DataFrame对象,被设置为,如第5行函数的输出结果所示。
第6行代码通过方法将与合并,合并方式默认为基于的左连接,合并后的结果为一个3行4列的DataFrame对象,如第7行函数的输出结果所示。
第8行代码通过方法将与合并,合并方式和结果与第6行代码相同,参数被设置为True,配源码笔记地址匹配表示以和的行标签作为连接键,如第9行函数的输出结果所示。
第行代码通过方法将与合并,指定合并方式为内连接,合并后的结果为一个2行4列的DataFrame对象,如第行函数的输出结果所示。
第行代码通过方法将与合并,合并方式和结果与第行代码相同,和参数被设置为,表示以和的行标签作为连接键,如第行函数的输出结果所示。
第行代码通过字典创建了一个3行3列的DataFrame对象,没有设置参数,如第行函数的输出结果所示。
第行代码通过方法将与合并,由于与不具有相同的行标签,但是的与的列有相同的数值,因此通过指定将中的与中的对齐,合并方式默认为左连接,合并后的结果为一个3行5列的DataFrame对象,如第行函数的输出结果所示。
第行代码通过方法将与合并,合并方式和结果与第行代码相同,表示表以列为连接键,表示表以行标签为连接键,表示连接方式为左连接,如第行函数的输出结果所示。
Tips
1)join方法实现的数据表合并也可以用merge方法实现,但join方法更简单、更快速。
2)join方法不会修改原始数据表,而是生成一个合并后的副本。
concat方法
concat方法的功能为沿着一个特定轴,对一组相同类型的Pandas对象执行连接操作。如果操作对象是DataFrame,还可以同时在其他轴上执行索引的可选集合逻辑操作(并集或交集)。concat方法接受一列或一组相同类型的对象,并通过一些可配置的处理将它们连接起来,这些处理可用于其他轴。其语法格式如下:
常用的参数含义说明如下。
是需要拼接的对象集合,一般为Series或DataFrame对象的列表或者字典。
表示连接的轴向,默认为0,表示纵向拼接,即基于列标签的拼接,拼接之后行数增加。时表示横向拼接,即基于行标签的拼接,拼接之后列数增加。
表示连接方式,默认为,拼接方法为外连接(并集)。时,拼接方法为内连接(交集)。
是布尔类型,默认为,表示保留连接轴上的标签。如果将其设置为,则不保留连接轴上的标签,而是产生一组新的标签。
是列表类型。如果连接轴上有相同的标签,为了区分,可以用keys在最外层定义标签的分组情况,形成连接轴上的层次化索引。
下面通过代码清单3演示concat方法的用法。
程序执行结束后,输出结果如下:
下面对代码清单3中的代码做简要说明。
第2~5行代码分别通过字典创建了4个3行4列的DataFrame对象、、、波段进场附图指标源码,分别被设置为、、、。
第6行代码通过方法将、和拼接,采用默认的参数设置,即纵向外拼接。由于df1、df2和df3的列标签完全相等,但行标签没有重叠的部分,拼接后的结果为一个9行4列的DataFrame对象,如第7行函数的输出结果所示。
第8行代码通过方法将和拼接,表示横向拼接,拼接方式默认为外拼接。由于和的列标签完全相等,拼接后的列会有重复的列标签。为了便于区分,设置参数在最外层定义标签的分组情况,的列标签的外层索引为,的列标签的外层索引为。拼接后的结果为一个6行8列的DataFrame对象,如第9行函数的输出结果所示。
第行代码通过方法将和拼接,拼接方式与第8行代码相同。设置为外拼接,为了区分拼接后的对象中重复的列标签,设置,指定的列名加上后缀;设置,指定的列名加上后缀,如第行函数的输出结果所示。可以看到,中的元素数据与相同,不同之处在于采用外层索引的方式区分重复列,而采用列名加后缀的方法。
第行代码通过方法将和拼接,采用默认的参数设置,即纵向外拼接。拼接后的结果为一个6行4列的DataFrame对象,如第行函数的输出结果所示,可以看到的行标签完全保留了和的行标签。
第行代码在第行代码的基础上,增加了参数设置,表示会重新生成新的整数序列作为拼接后的DataFrame对象的行标签,如第行函数的输出结果所示。
第行代码通过方法将第6行代码的和拼接,表示横向拼接,指定内拼接。拼接后的结果为一个3行7列的DataFrame对象,如第行函数的输出结果所示,保留了和中相同的行标签。
Tips
1)在实际应用中,join方法常用于基于行标签对数据表的列进行拼接,concat方法则常用于基于列标签对数据表的行进行拼接。
2)concat方法不会修改原始数据表,而是生成一个合并后的副本。
-END-
本文摘编于《Python数据分析与应用》,经出版方授权发布。
内容简介
1、如正文所介绍的那样。
活动规则
公布时间:年9月1号(周三)晚上点
注意事项:一定要留意微信消息,如果你是幸运儿就尽快在小程序中填写收货地址、书籍信息。一天之内没有填写收货信息,送书名额就转给其他人了噢,欢迎参
挑战SQL:图解pandas的数据合并merge函数大家好,我是Peter~
在实际的业务需求中,我们的数据可能存在于不同的库表中。很多情况下,我们需要进行多表的kdj指标金叉源码连接查询来实现数据的提取,通过SQL的join,比如leftjoin、leftjoin、innerjoin等来实现。
在pandas中也有实现合并功能的函数,比如:concat、append、join、merge。本文中重点介绍的是merge函数,也是pandas中最为重要的一个实现数据合并的函数。
看完了你会放弃SQL吗?
目前Pandas系列文章已经更新了篇,文章都是以案例+图解的风格,欢迎访问阅读。有很多个人推荐的文章:
官网学习地址:
参数的具体解释为:
我们创建了4个DataFrame数据框;其中df1和df2、df3是具有相同的键userid;df4有类似的键userid1,取值也是ac,和df1或df2的userid取值有相同的部分。
left、how就是需要连接的两个数据帧,一般有两种写法:
图解过程如下:
inner称之为内连接。它会直接根据相同的列属性userid进行关联,取出属性下面相同的数据信息a、c
上面的图解过程就是默认的使用how="inner"
outer称之为外连接,在拼接的过程中会取两个数据框中键的并集进行拼接
图解过程如下:
以左边数据框中的键为基准;如果左边存在但是右边不存在,则右边用NaN表示
图解过程如下:
以右边数据框中的键的取值为基准;如果右边存在但是左边不存在,则左边用NaN表示
图解过程如下:
笛卡尔积:两个数据框中的数据交叉匹配,出现n1*n2的数据量
笛卡尔积的图解过程如下:
如果待连接的两个数据框有相同的键,则默认使用该相同的键进行联结。
上面的所有图解例子的参数on默认都是使用相同的键进行联结,所以有时候可省略。
再看个例子:
还可以将left和right的位置进行互换:
上面的两个例子都是针对数据框只有具有相同的一个键,如果不止通过一个键进行联结,该如何处理?通过一个来自官网的例子来解释,我们先创建两个DataFrame:df5、df6
现在进行两个数据框的合并:
合并的图解过程如下:
在看一个通过how="outer"进行连接的案例:
看看图解的过程:
上面在连接合并的时候,两个数据框之前都是有相同的字段,比如userid或者key1和key2。但是如何两个数据框中没有相同的键,但是这些键中的取值有相同的部分,比如我们的df1、df3:
在这个时候我们就使用left_on和right_on参数,分别指定两边的连接的键:
如果我们不指定,系统就会报错,因为这两个数据框是没有相同的键,本身是无法连接的:
如果连接之后结果有相同的字段出现,默认后缀是_x_、_y。这个参数就是改变我们默认的后缀。我们回顾下笛卡尔积的形成;
现在我们可以指定想要的后缀:
这个参数的作用是表明生成的一条记录是来自哪个DataFrame:both、left_only、right_only
如果带上参数会显示一个新字段_merge:
不带上参数的话,默认是不会显示来源的,看默认的情况:
merge函数真的是非常强大,在工作中也使用地很频繁,完全可以实现SQL中的join效果。希望本文的图解能够帮助读者理解这个合并函数的使用。同时pandas还有另外几个与合并相关的函数,比如:join、concat、append,会在下一篇文中统一讲解。
Python数据分析笔记#8.2.2索引上的合并
「目录」
数据规整:聚合、合并和重塑
DataWrangling:Join,Combine,andReshape
--------数据库风格的DataFrame合并
--------索引上的合并
上一篇笔记讲的是如何根据DataFrame的列名来链接两个DataFrame对象。
有时候我们要根据DataFrame中的index索引来合并数据。这种情况下,我们可以传入left_index=True或right_index=True或两个都传入来说明索引被用作链接键。
我们先创建两个DataFrame,指明根据第一个DataFrame的'key'列和第二个DataFrame的index索引来合并数据:
默认的merge方法是求取链接键的交集,通过传入how='outer'可以得到它们的并集:
层次化索引数据的合并
对于层次化索引的数据的合并,我们要以列表的形式指明用作合并键的多个列。
比如下面我们就指定根据第一个DataFrame的'key1'列和'key2'列以及第二个DataFrame的index索引来合并:
同时使用双方的索引来合并也没问题:
join方法
DataFrame还有便捷的实例方法join,它能更方便的实现按索引合并,但要求没有重叠的列。
我们还可以向join传入一组DataFrame,类似于concat函数,实现多个DataFrame的合并拼接:
-END-
如何将多个excel文件合并?1、首先将这些excel文件都复制到一个文件夹下。
2、切换到数据菜单,点击新建查询,选择从文件下的从文件夹。
3、输入刚刚的文件夹路径,点击确定。
4、点击合并下的合并和加载选项。
5、选择要合并的工作表名称,最后点击确定。
6、这就完成了多个excel文件的合并。我们从筛选菜单中可以看到本例中的4个文件都这一份表格中啦。
python横向合并数据哪个更常用一些join主要用于基于索引的横向合并拼接;
merge主要用于基于指定列的横向合并拼接;
concat可用于横向和纵向合并拼接;
append主要用于纵向追加;
combine可以通过使用函数,把两个DataFrame按列进行组合。
join
join是基于索引的横向拼接,如果索引一致,直接横向拼接。如果索引不一致,则会用Nan值填充merge是基于指定列的横向拼接,该函数类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
可以指定不同的how参数,表示连接方式,有inner内连、left左连、right右连、outer全连,默认为inner;
python床头书系列Python Pandas中的join方法示例详解
详细解析Python Pandas中的join方法,包含原理、用法、示例与源码分析,以及官方链接。
原理:join方法用于数据连接,根据索引或列之间的关系合并DataFrame。具体步骤包括确定连接方式与连接列、进行数据对齐、依据连接方式连接数据,并返回新的DataFrame。
用法示例:创建两个DataFrame,通过join方法实现连接操作。默认为左连接,连接列默认为索引。使用on参数指定连接列,并调整连接方式为内连接或外连接。
示例代码与结果输出:创建df1与df2,使用join方法连接,示例展示连接结果。
结果展示:连接后的DataFrame对象,分别展示了左连接、内连接与外连接的连接结果。
源码分析:解析join方法的内部实现,其调用merge方法进行数据连接操作。
官方链接:查阅Pandas文档中的join方法说明,获取详细信息与参数解释。
Pandas DataFrame连接表 几种连接方法的对比
Pandas.DataFrame操作表连接的三种方式包括merge、join和concat,下面将详细探讨这三种方法的特性和使用场景。
第一种方法是merge,它是基于键值连接数据框的最常用方式。merge可以执行多种连接类型,包括内部、左外、右外和全连接。
第二种方法是join,它与merge类似,但更侧重于基于索引连接数据框。使用join时,你可以选择内连接、左外连接、右外连接或全连接。
第三种方法是concat()函数,它用于沿指定轴对数据框进行垂直或水平堆叠。concat()适用于在不同列或行上连接数据框。
在选择合适的连接方法时,需要考虑数据的结构、连接键的可用性以及是否需要保持特定的顺序。merge和join适用于键匹配的场景,而concat()则适用于数据堆叠需求。实际应用中,具体选择哪种方法取决于实际的数据处理需求和期望的连接结果。
图解pandas数据合并:concat+join+append
公众号:尤而小屋 作者:Peter 编辑:Peter 大家好,本文将深入探讨pandas中的数据合并操作,包括concat、join和append函数的使用。这三种方法在数据分析中扮演着重要角色,特别是当需要对多个数据集进行整合时。concat
concat函数是默认沿纵轴合并数据,但可以通过axis参数调整。如果数据框中存在缺失值,非匹配字段会显示为NaN。ignore_index参数影响索引,而join和keys则用于设定合并方式和索引命名。join与参数
join用于确定交集(inner)或并集(outer)。默认为outer,保留所有字段。lsuffix和rsuffix参数用于指定相同字段的后缀,若不指定则可能导致错误。how参数可控制合并方向,如left或right。合并多个DataFrame
合并多个DataFrame时,可以分步进行,先合并部分数据,再与后续数据融合。merge函数与how="outer"参数结合,可以实现全连接。append
append函数用于追加数据,新数据列若与已有列名称冲突,将作为新列添加。ignore_index可用于重置索引,而verify_integrity参数在创建相同索引时有严格验证。实战应用
通过合并数据,如从Excel中的订单表、订单商品表和商品信息表,可以实现如分析不同水果的销量和订单数,或不同区域的水果销售额和客户数等业务需求。 总结来说,熟练掌握pandas的merge、concat、join和append,能有效处理数据合并,为数据分析提供强大工具。无论数据源来自何处,这四种方法都能帮助我们高效地整合数据,为后续分析奠定基础。Pandas常见拼接操作!
本文主要介绍了Pandas库中join操作的基本用法,它在数据合并中的作用不容忽视。join函数主要用于无重复列名的DataFrame间基于行索引的列拼接,或在列索引和内容存在对应关系时进行细致的融合。
join的基本语法如下:
1. 参数设置中,'how'定义连接方式,包括inner、left、right、outer,默认为left连接。'on'指定用于连接的列索引,必须在两个DataFrame中存在,可以设置多键连接。'sort'默认为False,影响性能。
在实际应用中,join的主要功能包括:
- 无重复列名的DataFrame拼接,直接df1.join(df2)即可。
- 面对重复列名,需要指定lsuffix和rsuffix以避免冲突。
- 对于列名和内容都不同的情况,可以使用set_index()函数来设置列索引,如'l.join(r.set_index(key of r), on='key of l')'。
举例来说:
- 如果df1和df3无重复列名,基于行索引拼接,无需额外参数。
- df1和df2有重复列名,基于行索引拼接时,需指定lsuffix和rsuffix。
- 对于列名和内容不同的df1和df2,根据列索引进行拼接时,需用set_index()。
最后,join的使用需注意其与merge函数的区别,如内连接和外连接的区别,以及merge在处理重复列时的行为。如有任何疑问,可在讨论区提问,小明将为大家解答。
希望这些信息对理解Pandas的join操作有所帮助。如需获取更多Python教程资源,可以私信获取相关资料哦!
Pandas DataFrame 中的自连接和交叉连接
在SQL世界中,JOIN操作是数据合并的关键。Pandas DataFrame也提供了类似的工具,包括自连接和交叉连接,用于处理复杂的数据合并需求。以下是这两种连接方式的详细介绍。
首先,自连接是DataFrame与自身进行连接,常用于探索层次数据或比较同一数据集中的行。例如,考虑一个公司员工和经理的组织结构数据。通过自连接,我们可以找出员工汇报给谁,如在Pandas中,可以创建一个新DataFrame df_managers,将其与自身连接,删除重复的manager_id,使用left连接保留所有员工信息,得到结果,包括Regina Philangi这位没有上级的最高管理者。同样,pandas.merge()函数也能实现这一操作。
其次,交叉连接则是生成两个表所有行的组合,形成笛卡尔积。例如,想要获取服装店所有颜色的库存,即使两个DataFrame没有索引,也能通过pandas.merge()或pandas.concat()轻松实现。
总的来说,Pandas DataFrame的自连接和交叉连接功能为数据处理提供了强大而灵活的工具。无论是组织结构分析还是库存管理,都能有效简化数据处理流程。希望这些基础知识能帮助你在数据探索和分析中得心应手。
PyODPS DataFrame 处理笛卡尔积的几种方式
PyODPS 提供了 DataFrame API,用以进行大规模数据分析与预处理,本文将重点介绍如何使用 PyODPS 进行笛卡尔积操作。
笛卡尔积常见于需要比较或运算的场景,比如计算地理位置距离。假设大表 Coordinates1 存储目标点经纬度,小表 Coordinates2 存储出发点经纬度,需要计算所有出发点到目标点的距离并找出最小距离。对于单个目标点,这将生成 M * N 条数据,构成笛卡尔积问题。
计算两点距离通常采用 haversine 公式,Python 表达式如下。
为了执行笛卡尔积,推荐使用 mapjoin 方法。PyODPS 中实现 mapjoin 非常简单,只需在两个 DataFrame 进行 join 操作时指定 mapjoin=True,之后会对右表进行 mapjoin 操作。执行 join 后,可利用 DataFrame 的自建函数计算距离,操作简洁高效。
在执行 mapjoin 后,生成的 DataFrame 包含 M * N 条数据。接着,通过调用 groupby 函数并应用 min 聚合,即可获取每个目标点的最小距离。
若需找到对应最小距离的出发点 id,可使用 DataFrame 的 apply 方法。通过定义自定义函数并设置 axis 参数为 1,在行上操作,即可实现这一目标。值得注意的是,apply 方法在服务端执行 UDF,因此函数内不能使用类似 df=o.get_table('table_name').to_df() 的表达式。
为了处理较小规模的数据,可将小表数据作为全局变量在自定义函数中使用,将数据 pickle 到 UDF 中。然而,这种方法适用场景有限,因为 ODPS 上传文件资源大小有限制。此外,确保客户端与服务端三方包版本一致,否则可能遇到序列化问题。
总结而言,PyODPS 解决笛卡尔积问题主要通过两种方式:一是 mapjoin,直观且性能优良,推荐使用内建函数以达到最佳效率;二是使用 DataFrame 自定义函数,实现灵活,性能稍逊一筹,通过表资源实现笛卡尔积操作。
python学习 --DataFrame连接: merge、concat、join、append
本文将对Python中DataFrame的连接操作进行阐述,涉及merge、concat、join和append四种方法。 首先,我们来探讨pd.merge(left, right, how='inner')函数的使用。此函数根据指定列进行连接,结果如下所示:左连接:姓名、年龄、爱好_x、爱好_y
右连接:姓名、年龄、爱好_x、爱好_y
内连接:姓名、年龄、爱好_x、爱好_y
外连接:姓名、年龄、爱好_x、爱好_y
pd.concat([left,right],axis=1,join='inner')函数用于根据行索引进行连接,实现两表所有列横向堆叠。具体结果如下:纵向内连接:姓名、年龄、性别、姓名、爱好
纵向外连接:姓名、年龄、性别、姓名、爱好
我们还提供了根据列索引进行连接的方法,结果如下:纵向内连接:姓名、年龄、性别、爱好
纵向外连接:姓名、年龄、性别、爱好
注意,连接后的表包含df1.index和df2.index,可利用ignore_index = True重新定义新的行索引index。同时,如果先知道如何进行连接,可以得到特定的结果。 df_left.join(df_right)方法用于根据行索引进行连接。当使用行索引时,结果如下:姓名、年龄、性别、工号、爱好
当使用列索引时,结果如下:姓名_1、年龄、性别、姓名_2、爱好
姓名、年龄、性别、爱好
年龄、性别、爱好、姓名
最后,我们探讨了df.append([df1, df2...])方法,用于添加DataFrame表或Series序列。添加DataFrame表和添加Series序列的结果如下:添加DataFrame表:姓名、年龄、性别、爱好
添加Series序列:姓名、年龄、性别、1、赵一、、男、4、钱二、、女、5、孙三、、女、7、李四、、男
通过本文的阐述,希望读者能够对Python中DataFrame的连接操作有更深入的理解。


