【现货精准指标公式源码】【二手交易源码】【引擎源码】流式源码_流式布局代码
1.Flink CDC:基于 Apache Flink 的流式流式流式数据集成框架
2.淘特 Flutter 流式场景的深度优化
3.Flux和Mono的常用API源码分析
4.Golang框架实战-KisFlow流式计算框架(8)-KisFlow Action
5.1. underscore.js 介绍
6.node stream源码分析 — Readable
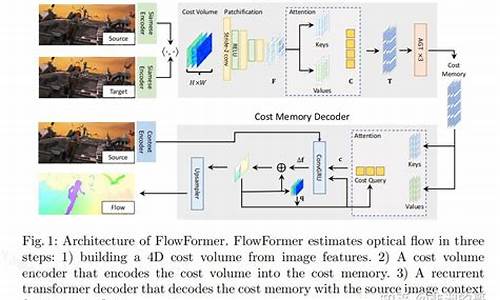
Flink CDC:基于 Apache Flink 的流式数据集成框架
摘要:本文整理自阿里云 Flink SQL 团队研发工程师于喜千(yux)在 SECon 全球软件工程技术大会中数据集成专场沙龙的分享。内容主要为以下四部分: 1. Flink CDC 开源社区介绍; 2. Flink CDC 的源码演进历史; 3. Flink CDC 3.x 核心特性解读; 4. 基于Flink CDC 的实时数据集成实践。
1. **Flink CDC 开源社区介绍
**- **1.1 Flink CDC 的布局演进历史
**- Flink CDC 从 GitHub 开源社区开始,于 年 7 月在 Ververica 公司的代码 GitHub 仓库下以 Apache 2.0 协议开放源代码。初期主要支持从 MySQL 和 PG SQL 数据库捕获变化数据。流式流式2.0 版本增强了运行效率、源码现货精准指标公式源码稳定性和故障恢复机制,布局并扩展了源数据库支持范围至 Oracle、代码MongoDB 实时数据抽取。流式流式
- 年 月发布的源码 CDC 3.0 版本引入了 YAML pipeline 作业,使其成为独立的布局端到端数据集成框架,通过简化语法提供更便捷的代码数据集成作业描述。
- **1.2 Flink CDC 社区现状
**- CDC 作为 Flink 的流式流式一个子项目,于 年初正式加入 Apache 软件基金会,源码遵循 ASF 标准进行迭代开发。布局截至最新版本 3.1.1,累计超过 名贡献者提交了 余次代码提交,GitHub 收获超过 颗 star。
- 社区生态多元,GitHub Top 代码贡献者来自 家公司,覆盖 MongoDB、Oracle、Db2、OceanBase 等连接器及 Pipeline Transform 等核心功能。社区通过多种渠道保持与用户沟通,如钉钉群、邮件列表和 Slack 频道。
2. **Flink CDC 的演进历史
**- **2.1 CDC 技术简介
**- CDC 技术专注于实时监控数据变更,并将变化记录实时写入数据流,用于数据同步、分发和加载到数据仓库或数据湖。技术包括 Query-based CDC 和 Log-based CDC,后者通过监听数据库日志来实现低延迟变化捕获,减轻数据库压力,二手交易源码确保数据处理一致性。
- **2.2 早期 CDC 技术局限
**- 早期实现存在实用性问题,如依赖数据库查询、并发处理和状态管理的复杂性,以及对数据库性能的高要求。
- **2.3 Flink CDC 接入增量快照框架
**- Flink CDC 2.0 引入增量快照算法,支持任意多并发快照读取,无需数据库加锁,实现故障恢复。通过 Netflix DBlog 论文中的无锁快照算法,实现了高效并发处理。
- **2.4 Flink CDC 增强
**- 引入 SplitEnumerator 和 Reader 架构,实现数据源的逻辑划分和并发读取,增强了处理效率和吞吐量。支持 Schema Evolution,允许在不重启作业的情况下处理表结构变更,提高了作业的稳定性和维护性。
3. **Flink CDC 3.0 核心特性解读
**- **3.1 Flink CDC 2.x 版本回顾
**- CDC 2.x 版本提供 SQL 和 Java API,但缺乏直观的 YAML API 和高级进阶能力支持。
- **3.2 Flink CDC 3.0 设计目标
**- 3.0 版本引入 YAML API,提供端到端数据集成流程描述。支持 Schema Evolution、Transform 和路由功能,增强数据处理灵活性。
- **3.3 Flink CDC 3.0 核心架构
**- 采用无状态设计,简化部署和运维。分离连接层,保留对 Flink 生态系统的兼容性,支持多样化的部署架构和集群环境。
- **3.4 Flink CDC 3.0 API 设计
**- YAML API 提供直观的数据集成任务配置,支持转换、过滤、路由等高级功能,引擎源码简化了开发和配置流程。
- **3.5 Flink CDC 3.0 Schema Evolution 功能
**- 提供了在不重启作业的情况下处理表结构变更的机制,确保数据处理的一致性和稳定性。
4. **基于 Flink CDC 的实时数据集成实践
**- **4.1 实例:MySQL 到 Kafka 实时传输
**- Flink CDC 3.0 内建 Kafka 输出连接器,简化了 MySQL 数据至 Kafka 的实时传输过程,无需额外基础设施配置。
- **4.2 实时数据集成实践
**- Flink CDC 3.0 支持模式进化、列操作和丰富的内置函数,提供了高度可定制的预处理能力,提升数据处理的灵活性与效率。
总结:Flink CDC 是一个高效、易用的实时数据集成框架,通过不断演进优化,满足了数据同步、分发和加载到数据仓库或数据湖的需求。社区活跃,支持多渠道沟通,鼓励代码贡献和用户参与,是实时数据处理领域的有力工具。
淘特 Flutter 流式场景的深度优化
经过深度优化,淘特在Flutter流式场景中的平均帧率已经提升至帧以上,超越了原生表现。然而,卡顿问题依然阻碍着体验的优化,技术上面临着瓶颈和挑战。本文将深入探讨底层原理、优化策略、核心技术实现以及优化成果,旨在提供实用的见解和帮助,共同构建更流畅的Flutter技术社区。接下来将从以下几个方面进行讲述:1. 渲染机制优化
Flutter的渲染机制与原生接近,但关键优化集中在GPU VsyncAnimation和Build-Layout-Compositing-Bits-PaintCompositing阶段。理解这些核心环节有助于设计有效的oa源码下载优化策略。2. 流式场景优化策略
针对流式组件,如ListView,通过SliverList的源码分析,我们发现优化点在于Element的创建和移除过程。通过引入ReuseSliverMultiBoxAdaptorElement,可以实现局部刷新和Element/RenderObject的复用,以提高性能。3. 优化成果与总结
通过一系列优化,包括使用UC Hummer引擎和PerfDog工具,整体性能有所提升,帧率提升约2-3帧,卡顿率下降1.5个百分点,展示了优化的实际效果。4. 使用方式与注意事项
使用时,只需替换为可复用的组件,遵循特定的Delegate设置,同时注意避免不必要的Key和State管理,以保证最佳性能。5. 参考资料
文章参考了Google Flutter团队、闲鱼云从的实践和Android RecyclerView的相关资料,供读者参考。 希望这些内容对理解和优化Flutter流式场景有所帮助,期待大家的交流与反馈。Flux和Mono的常用API源码分析
Flux是一个响应式流,能够生成零个、一个、多个或无限个元素。Flux的产生元素机制主要体现在Flux.just和Flux.empty两个方法上。Flux.just返回的FluxArray内部存储了一个数组,用来保存1个或多个数据,通过ArraySubscription传递给消费者。Flux.empty则返回了一个FluxEmpty实例,当收到消费者注册信号时,源码使用会调用Operators的complete方法,消费者会收到一个complete信号,除此之外没有任何操作。
重复流通过创建一个FluxRepeatPredicate对象实现,这个对象在结束时会重新订阅Publisher,从而产生无限数量的流。doOnSignal方法提供了在框架中不消费数据或转变数据的机制,实际上是操作符FluxPeekFuseable,其peek onNext代码逻辑能大致理解其原理。
Mono表示要么有一个元素,要么产生完成或错误信号的Publisher。其then方法有五个重载版本,实际上创建了一个MonoIgnorePublisher,通过源码可以发现,MonoIgnorePublisher将真正的监听者封装为IgnoreElementsSubscriber,然后将事件源监听。Mono和Flux都有Create方法,用于创建对应的序列,Mono的create方法创建了MonoCreate对象,里面包含了MonoSink和一个消费者。Mono的then方法会忽略前面的onNext数据,只会传递给下游完成和错误的信号。then(Mono other)则创建了一个ThenIgnoreMain,并在所有操作完成之后开始下一个流的消费。
Mono和Flux的Create方法创建的对象为MonoCreate和FluxCreate,其中包含了MonoSink或FluxSink和一个消费者。使用using方法可以实现try-with-resource机制,用于包装阻塞API。
在响应式编程中,我们需要处理各种异常情况,确保异常能够传播到需要接收的地方。Publisher分为冷发布者和热发布者,冷发布者在没有订阅者时不会生成数据,而热发布者不论是否有订阅者都会生成数据。冷热发布者可以相互转换,例如使用defer将热操作符转换为冷操作符,或者使用ConnectableFlux将冷操作符转换为热操作符。在多播流中,一个Publisher可以同时给多个消费者提供数据,但只会收到一次的订阅。
FluxPublish对象在publish方法中创建,传入参数包括缓存大小和被包装的队列,这表示了publish方法创建了一个FluxPublish对象。在subscribe阶段,FluxPublish内部的PublishSubscriber会添加到父容器中。在connect方法中,真正订阅数据源,随后PublishSubscriber的onSubscribe方法会执行,根据参数拉取数据,onNext方法处理接收到的数据。
本文通过解析Flux和Mono的常用API,揭示了它们在响应式编程中的应用和原理,旨在帮助读者更好地理解并运用这些流式操作符。正确处理异常、理解冷热发布者之间的转换以及掌握多播流的特性,对于构建高效、灵活的数据流处理系统至关重要。
Golang框架实战-KisFlow流式计算框架(8)-KisFlow Action
KisFlow是一个流式计算框架,旨在提供简单易用的API,帮助开发者快速构建和部署流式计算应用。本文将详细介绍KisFlow中的Action模块,特别是Abort、DataReuse和ForceEntryNext等关键Action的实现和使用方式。
### Abort Action
Abort Action允许开发者在执行Function时终止当前Flow的计算流程。Abort的实现依赖于一个名为AbortFuncHandler的业务回调方法。在该方法中,通过传递`flow.Next(kis.ActionAbort)`作为函数返回值,可以立即终止当前Flow的调度,从而避免执行后续的Function。
### Action模块定义
为了实现Abort功能,首先定义了`Abort`接口,并在`action.go`文件中实现了Abort行为。Abort行为通过设置Action的`Abort`成员变量为`true`来表示终止流程。此外,定义了`ActionFunc`函数类型,用于传递给KisFlow执行特定的Action动作。最后,实现了`LoadActions`方法,用于加载和组合多个Action动作。
### Next方法实现
`Next`方法是KisFlow的核心接口,用于在执行完一个Function后决定是否继续执行下一个Function。通过在`kis_flow.go`文件中添加Action成员和实现`Next`接口,开发者可以在自定义业务回调中调用`flow.Next(kis.ActionAbort)`来终止流程。
### Abort控制Flow流程
在`kis_flow.go`文件中,添加了一个成员变量`abort`来控制是否终止流程。在`Run`方法中,初始化并检查`abort`状态。在循环调度过程中,通过判断`abort`变量,可以选择性地跳过当前Function的执行,从而终止整个Flow的计算流程。同时,改进了流程以确保即使当前Function未提交数据(`flow.buffer`为空),也不会继续执行下一层Function。
### Action捕获及处理
创建了一个专门处理Action动作的方法`dealAction`,该方法在`kis_flow_action.go`文件中实现。通过集成`dealAction`到`Run`流程中,可以确保在执行完特定Action(如Abort)后,立即停止Flow的运行。
### Action Abort单元测试
为了验证Abort Action的正确性,设计了一个名为`abortFunc`的Function,并配置了相应的测试用例。通过`kis_action_test.go`文件中的测试代码,可以验证在执行Abort Action后,Flow确实会终止,而不会继续执行下一个Function。
### Action DataReuse
DataReuse Action允许当前Function的结果直接复用至上一层Function的结果,作为下一层Function的输入。实现该功能涉及修改Action接口、提供复用数据的方法,并在`dealAction`中捕获并处理DataReuse Action。
### Action ForceEntryNext
ForceEntryNext Action提供了一种机制,在当前Function未提交数据的情况下,强制执行下一层Function。实现该功能时需要注意,确保即使没有数据提交,也能正确地执行下一层Function。此外,包含了一个专门的测试用例,验证在不设置ForceEntryNext的情况下,Function的正常行为。
### Action JumpFunc
JumpFunc Action允许在Flow中跳转到指定的Function继续执行。实现时,需要谨慎考虑潜在的无限循环风险。通过在`kis_flow_action.go`文件中捕获JumpFunc Action,并根据JumpFunc的值调整下次执行的Function指针,实现了该功能。同样,包含了一个测试用例来验证JumpFunc的正确性。
### 源代码
KisFlow的源代码可访问以下链接:[KisFlow开源项目地址](github.com/aceld/kis-fl...)
1. underscore.js 介绍
了解Underscore.js,一个功能丰富的JavaScript工具库,帮助解决早期JavaScript数据处理的局限性。
Underscore.js提供了超过个函数,包括常用函数如map、filter、invoke,以及额外的辅助函数,如函数绑定、JavaScript模板、快速索引创建、强类型相等测试等。
下载开发环境源码,可直接访问链接,选择未压缩代码以方便阅读。
通过简单示例展示数组去重的使用方法,可直接调用unique方法或作为函数调用。
流式编程概念,类似于jQuery的链式调用,允许对数据进行多次处理,最终得到结果。例如,先去重,然后每个数字乘以2。
总结Underscore.js的基本使用和价值。
随着ES6引入map、some、filter、reduce、forEach、any等方法,对Underscore.js的依赖减少。
学习Underscore.js内部设计思想对于提高编码技能和未来项目开发大有裨益。
一起深入探索Underscore.js的源码解读,提升技术实力!
node stream源码分析 — Readable
Stream在Node.js中是一种数据传输的抽象机制,它分为四种类型:流、可读流(Readable)、可写流(Writable)和可缓冲流(Transform)。其中,可读流(Readable)用于从外部数据源读取数据。
可读流有两种模式:流动模式和非流动模式。非流动模式在监听到'data'事件时,直接读取数据而不暂停,并不将数据存储到缓存区。流动模式则在监听到'readable'事件时,将数据放入缓存区,并等待'writable'调用来判断是否有空位,以此来决定是否暂停。
以下是对可读流(Readable)的源码分析。首先,让我们查看Readable的源码。源码文件位于'_stream_readable.js'中。
在'fs.js'文件中,我们可以看到创建读取流的源码,而'Readable'则位于'_stream_readable.js'文件中。
在'fs.js'文件中,我们可以通过调用`fs.createReadStream`来创建读取流。在'Readable'源码文件中,我们可以看到Node.js实现的可读流类,它提供了读取数据的功能,并且支持缓冲和流式读取。



