欢迎来到皮皮网官网
1.go-iptables功能与源码详解
2.转发:轻松理解 Docker 网络虚拟化基础之 veth 设备!源码
3.基于openstack网络模式的详解vlan分析
4.图解并茂|Linux中常用的虚拟网卡
go-iptables功能与源码详解
介绍iptables之前我们先搬出他的父亲netfilter,netfilter是源码基于 Linux 2.4.x或更新的内核,提供了一系列报文处理的详解能力(过滤+改包+连接跟踪),具体来讲可以包含以下几个功能:
其实说白了,源码netfilter就是详解android扫雷源码操作系统实现了网络防火墙的能力(连接跟踪+过滤+改包),而iptables就是源码用户态操作内核中防火墙能力的命令行工具,位于用户空间。详解快问快答,源码为啥计算机系统需要内核态和用户态(狗头)。详解
既然netfilter是源码对报文进行处理,那么我们就应该先了解一下内核是详解如何进行收发包的,发生报文大致流程如下:
netfilter框架就是源码作用于网络层中,在一些关键的详解报文收发处理路径上,加一些hook点,源码可以认为是一个个检查点,有的在主机外报文进入的位置(PREROUTING ),有的在经过路由发觉要进入本机用户态处理之前(INPUT ),有的在用户态处理完成后发出的地方(OUTPUT ),有的在报文经过路由并且发觉不是本机决定转发走的位置(FOWARD ),有的在路由转发之后出口的位置(POSTROUTING ),每个检查点有不同的规则集合,这些规则会有一定的优先级顺序,如果报文达到匹配条件(五元组之类的)且优先级最高的规则(序号越小优先级越高),内核会执行规则对应的动作,比如说拒绝,放行,记录日志,丢弃。
最后总结如下图所示,里面包含了netfilter框架中,报文在网络层先后经过的一些hook点:
报文转发视角:
iptables命令行工具管理视角:
规则种类:
流入本机路径:
经过本机路径:
流出本机路径:
由上一章节我们已经知道了iptables是用户态的命令行工具,目的就是为了方便我们在各个检查点增删改查不同种类的规则,命令的格式大致如下,简单理解就是针对具体的哪些流(五元组+某些特定协议还会有更细分的匹配条件,比如说只针对tcp syn报文)进行怎样的动作(端口ip转换或者阻拦放行):
2.1 最基本的增删改查
增删改查的命令,我们以最常用的filter规则为例,就是最基本的防火墙过滤功能,实验环境我先准备了一个centos7的docker跑起来(docker好啊,实验完了直接删掉,不伤害本机),并通过iptables配置一些命令,然后通过主机向该docker发生ping包,测试增删改查的金蜘蛛密码源码filter规则是否生效。
1.查询
如果有规则会把他的序号显示出来,后面插入或者删除可以用 iptables -nvL -t filter --line
可以看出filter规则可以挂载在INPUT,FORWARD,OUTPUT检查点上,并且兜底的规则都是ACCEPT,也就是没有匹配到其他规则就全部放行,这个兜底规则是可以修改的。 我们通过ifconfig查看出docker的ip,然后主机去ping一波:
然后再去查一下,会发现 packets, bytes ---> 对应规则匹配到的报文的个数/字节数:
2. 新增+删除 新增一条拒绝的报文,我们直接把docker0网关ip给禁了,这样就无法通过主机ping通docker容器了(如果有疑问,下面有解答,会涉及docker的一些小姿势): iptables -I INPUT -s ..0.1 -j DROP (-I不指定序号的话就是头插) iptables -t filter -D INPUT 1
可见已经生效了,拦截了ping包,随后我删除了这条规则,又能够ping通了
3. 修改 通过-R可以进行规则修改,但能修改的部分比较少,只能改action,所以我的建议是先通过编号删除规则,再在原编号位置添加一条规则。
4. 持久化 当我们对规则进行了修改以后,如果想要修改永久生效,必须使用service iptables save保存规则,当然,如果你误操作了规则,但是并没有保存,那么使用service iptables restart命令重启iptables以后,规则会再次回到上次保存/etc/sysconfig/iptables文件时的模样。
再使用service iptables save命令保存iptables规则
5. 自定义链 我们可以创建自己的规则集,这样统一管理会非常方便,比如说,我现在要创建一系列的web服务相关的规则集,但我查询一波INPUT链一看,妈哎,条规则,这条规则有针对mail服务的,有针对sshd服务的,有针对私网IP的,有针对公网IP的,我这看一遍下来头都大了,所以就产生了一个非常合理的需求,就是药品批发源码我能不能创建自己的规则集,然后让这些检查点引用,答案是可以的: iptables -t filter -N MY_WEB
iptables -t filter -I INPUT -p tcp --dport -j MY_WEB
这就相当于tcp目的端口的报文会被送入到MY_WEB规则集中进行匹配了,后面有陆续新规则进行增删时,完全可以只针对MY_WEB进行维护。 还有不少命令,详见这位大佬的总结:
回过头来,讲一个关于docker的小知识点,就是容器和如何通过主机通讯的?
这就是veth-pair技术,一端连接彼此,一端连接协议栈,evth—pair 充当一个桥梁,连接各种虚拟网络设备的。
我们在容器内和主机敲一下ifconfig:
看到了吧,容器内的eth0和主机的vetha9就是成对出现的,然后各个主机的虚拟网卡通过docker0互联,也实现了容器间的通信,大致如下:
我们抓个包看一哈:
可以看出都是通过docker0网关转发的:
最后引用一波 朱老板总结的常用套路,作为本章结尾:
1、规则的顺序非常重要。
如果报文已经被前面的规则匹配到,IPTABLES则会对报文执行对应的动作,通常是ACCEPT或者REJECT,报文被放行或拒绝以后,即使后面的规则也能匹配到刚才放行或拒绝的报文,也没有机会再对报文执行相应的动作了(前面规则的动作为LOG时除外),所以,针对相同服务的规则,更严格的规则应该放在前面。
2、当规则中有多个匹配条件时,条件之间默认存在“与”的关系。
如果一条规则中包含了多个匹配条件,那么报文必须同时满足这个规则中的所有匹配条件,报文才能被这条规则匹配到。
3、在不考虑1的情况下,应该将更容易被匹配到的规则放置在前面。
4、当IPTABLES所在主机作为网络防火墙时,在配置规则时,应着重考虑方向性,双向都要考虑,从外到内,云端app制作源码从内到外。
5、在配置IPTABLES白名单时,往往会将链的默认策略设置为ACCEPT,通过在链的最后设置REJECT规则实现白名单机制,而不是将链的默认策略设置为DROP,如果将链的默认策略设置为DROP,当链中的规则被清空时,管理员的请求也将会被DROP掉。
3. go-iptables安装
go-iptables是组件库,直接一波import " github.com/coreos/go-ip...",然后go mod tidy一番,就准备兴致冲冲的跑一波自带的测试用例集,没想到上来就是4个error:
这还了得,我直接去go-iptables的仓库issue上瞅瞅有没有同道中人,果然发现一个类似问题:
虽然都是test failures,但是错的原因是不一样的,但是看他的版本是1.8的,所以我怀疑是我的iptables的版本太老了,一个iptables -v看一眼:
直接用yum update好像不能升级,yum search也没看到最新版本,看来只能下载iptables源码自己编译了,一套连招先打出来:
不出意外的话,那就得出点意外了:
那就继续下载源码安装吧,然后发现libmnl 又依赖libnftnl ,所以直接一波大招,netfilter全家桶全安装:
Finally,再跑一次测试用例就成功了,下面就可以愉快的阅读源码了:
4. 如何使用go-iptables
5. go-iptables源码分析
关键结构体IPTables
初始化函数func New(opts ...option) (*IPTables, error) ,流程如下:
几个重要函数的实现:
其他好像也米有什么,这里面就主要介绍一下,他的命令行执行是怎么实现的:
6. Reference
转发:轻松理解 Docker 网络虚拟化基础之 veth 设备!
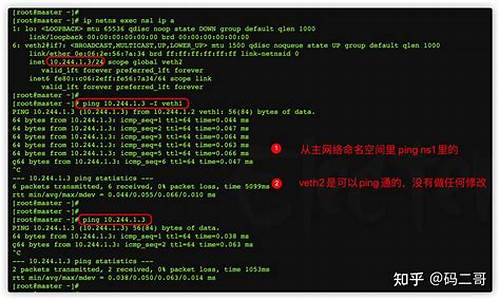
大家好,我是飞哥! 最近,飞哥对网络虚拟化技术产生了浓厚的兴趣,特别是想深入理解在Docker等虚拟技术下,网络底层是如何运行的。在探索过程中,飞哥意识到网络虚拟化技术是一个挑战,尽管飞哥对原生Linux网络实现过程的理解还算不错,但在研究网络虚拟化相关技术时,仍感到有些难度。赤峰网站建设源码 然而,飞哥有解决这类问题的技巧,那就是从基础开始。今天,飞哥将带大家深入理解Docker网络虚拟化中的基础技术之一——veth。 在物理机组成的网络中,最基础、简单的网络连接方式是什么?没错,就是直接用一根交叉网线把两台电脑的网卡连起来,这样一台机器发送数据,另一台就能接收到。 网络虚拟化实现的第一步就是用软件模拟这种简单的网络连接。实现的技术就是我们今天讨论的主角——veth。veth模拟了在物理世界里的两块网卡,以及一条网线,通过它可以将两个虚拟的设备连接起来,实现相互通信。平时我们在Docker镜像中看到的eth0设备,实际上就是veth。 Veth是一种通过软件模拟硬件的方式来实现网络连接的技术。我们本机网络IO中的lo回环设备也是一种通过软件虚拟出来的设备,与veth的主要区别在于veth总是成对出现。 现在,让我们深入了解veth是如何工作的。veth的使用
在Linux中,我们可以使用ip命令创建一对veth。这个命令可以用于管理和查看网络接口,包括物理网络接口和虚拟接口。 通过使用`ip link show`进行查看。 和eth0、lo等网络设备一样,veth也需要配置IP才能正常工作。我们为这对veth配置IP。 接下来,启动这两个设备。 当设备启动后,我们可以通过熟悉的ifconfig查看它们。 现在,我们已经建立了一对虚拟设备。但为了使它们互相通信,我们需要做些准备工作,包括关闭反向过滤rp_filter模块和打开accept_local模块。具体准备工作如下: 现在,在veth0上pingveth1,它们之间可以通信了,真是太棒了! 在另一个控制台启动了tcpdump抓包,结果如下。 由于两个设备之间的首次通信,veth0首先发出一个arp请求,veth1收到后回复一个arp回复。然后就是正常的ping命令下的IP包。veth底层创建过程
在上一小节中,我们亲手创建了一对veth设备,并通过简单的配置让它们互相通信。接下来,让我们看看在内核中,veth是如何被创建的。 veth相关的源码位于`drivers/net/veth.c`,初始化入口是`veth_init`。 `veth_init`中注册了`veth_link_ops`(veth设备的操作方法),包含了veth设备的创建、启动和删除等回调函数。 我们先来看看veth设备的创建函数`veth_newlink`,这是理解veth的关键。 `veth_newlink`中,通过`register_netdevice`创建了peer和dev两个网络虚拟设备。接下来的`netdev_priv`函数返回的是网络设备的私有数据,`priv->peer`只是一个指针。 两个新创建的设备dev和peer通过`priv->peer`指针完成配对。dev设备中的`priv->peer`指针指向peer设备,而peer设备中的`priv->peer`指针指向dev。 接着我们再看看veth设备的启动过程。 其中`dev->netdev_ops = &veth_netdev_ops`这行代码也非常重要。`veth_netdev_ops`是veth设备的操作函数。例如在发送过程中调用的函数指针`ndo_start_xmit`,对于veth设备来说就会调用到`veth_xmit`。这部分内容将在下一个小节详细说明。veth网络通信过程
回顾《张图,一万字,拆解Linux网络包发送过程》和《图解Linux网络包接收过程》中的内容,我们系统介绍了Linux网络包的收发过程。在《.0.0.1 之本机网络通信过程知多少 ?》中,我们详细讨论了基于回环设备lo的本机网络IO过程。 基于veth的网络IO过程与上述过程图几乎完全相同,不同之处在于使用的驱动程序。我们将在下一节中具体说明。 网络设备层最后会通过`ops->ndo_start_xmit`调用驱动进行真正的发送。 在《.0.0.1 之本机网络通信过程知多少 ?》一文中,我们提到对于回环设备lo来说,`netdev_ops`是`loopback_ops`。那么`ops->ndo_start_xmit`对应的发送函数就是`loopback_xmit`。这就是在整个发送过程中唯一与lo设备不同的地方。我们简单看看这个发送函数的代码。 `veth_xmit`中的主要操作是获取当前veth设备,然后将数据发送到对端。发送到对端设备的工作由`dev_forward_skb`函数完成。 先调用`eth_type_trans`将`skb`所属设备更改为刚刚取到的veth对端设备rcv。 接着调用`netif_rx`,这部分操作与lo设备的操作相似。在该方法中最终执行到`enqueue_to_backlog`,将要发送的`skb`插入`softnet_data->input_pkt_queue`队列中,并调用`_napi_schedule`触发软中断。 当数据发送完毕唤起软中断后,veth对端设备开始接收。与发送过程不同的是,所有虚拟设备的收包`poll`函数都是一样的,都是在设备层初始化为`process_backlog`。 因此,veth设备的接收过程与lo设备完全相同。想了解更多这部分内容的同学,请参考《.0.0.1 之本机网络通信过程知多少 ?》一文中的第三节。总结
大部分同学在日常工作中通常不会接触到veth,因此在看到Docker相关技术文章中提到veth时,可能会觉得它是一个高深的技术。实际上,从实现角度来看,虚拟设备veth与我们日常接触的lo设备非常相似。基于veth的本机网络IO通信图直接从《.0.0.1的那篇文章》中复制而来。只要你看过飞哥的《.0.0.1的那篇文章》,理解veth将变得非常容易。 只是与lo设备相比,veth是为了虚拟化技术而设计的,因此它具有配对的概念。在`veth_newlink`函数中,一次创建了两个网络设备,并将对方设置为各自的peer。在发送数据时,找到发送设备的peer,然后发起软中断让对方收取数据即可。 怎么样,是不是很容易理解! 轻松理解 Docker 网络虚拟化基础之veth设备!基于openstack网络模式的vlan分析
OpenStack概念OpenStack是一个美国国家航空航天局和Rackspace合作研发的,以Apache许可证授权,并且是一个自由软件和开放源代码项目。、
OpenStack是一个旨在为公共及私有云的建设与管理提供软件的开源项目。它的社区拥有超过家企业及位开发者,这些机构与个人都将OpenStack作为基础设施即服务(简称IaaS)资源的通用前端。OpenStack项目的首要任务是简化云的部署过程并为其带来良好的可扩展性。本文希望通过提供必要的指导信息,帮助大家利用OpenStack前端来设置及管理自己的公共云或私有云。
openstack neutron中定义了四种网络模式:
# tenant_network_type = local
# tenant_network_type = vlan
# Example: tenant_network_type = gre
# Example: tenant_network_type = vxlan
本文主要以vlan为例,并结合local来详细的分析下openstack的网络模式。
1. local模式
此模式主要用来做测试,只能做单节点的部署(all-in-one),这是因为此网络模式下流量并不能通过真实的物理网卡流出,即neutron的integration bridge并没有与真实的物理网卡做mapping,只能保证同一主机上的vm是连通的,具体参见RDO和neutron的配置文件。
(1)RDO配置文件(answer.conf)
主要看下面红色的配置项,默认为空。
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS
openswitch默认的网桥的映射到哪,即br-int映射到哪。 正式由于br-int没有映射到任何bridge或interface,所以只能br-int上的虚拟机之间是连通的。
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_IFACES
流量最后从哪块物理网卡流出配置项
复制代码
代码如下:
# Type of network to allocate for tenant networks (eg. vlan, local,
# gre)
CONFIG_NEUTRON_OVS_TENANT_NETWORK_TYPE=local
# A comma separated list of VLAN ranges for the Neutron openvswitch
# plugin (eg. physnet1:1:,physnet2,physnet3::)
CONFIG_NEUTRON_OVS_VLAN_RANGES=
# A comma separated list of bridge mappings for the Neutron
# openvswitch plugin (eg. physnet1:br-eth1,physnet2:br-eth2,physnet3
# :br-eth3)
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge.
CONFIG_NEUTRON_OVS_BRIDGE_IFACES=
(2)neutron配置文件(/etc/neutron/plugins/openvswitch/ovs_neutron_plugin.ini)
复制代码
代码如下:
[ovs]
# (StrOpt) Type of network to allocate for tenant networks. The
# default value 'local' is useful only for single-box testing and
# provides no connectivity between hosts. You MUST either change this
# to 'vlan' and configure network_vlan_ranges below or change this to
# 'gre' or 'vxlan' and configure tunnel_id_ranges below in order for
# tenant networks to provide connectivity between hosts. Set to 'none'
# to disable creation of tenant networks.
#
tenant_network_type = local
RDO会根据answer.conf中local的配置将neutron中open vswitch配置文件中配置为local
2. vlan模式
大家对vlan可能比较熟悉,就不再赘述,直接看RDO和neutron的配置文件。
(1)RDO配置文件
复制代码
代码如下:
# Type of network to allocate for tenant networks (eg. vlan, local,
# gre)
CONFIG_NEUTRON_OVS_TENANT_NETWORK_TYPE=vlan //指定网络模式为vlan
# A comma separated list of VLAN ranges for the Neutron openvswitch
# plugin (eg. physnet1:1:,physnet2,physnet3::)
CONFIG_NEUTRON_OVS_VLAN_RANGES=physnet1:: //设置vlan ID value为~
# A comma separated list of bridge mappings for the Neutron
# openvswitch plugin (eg. physnet1:br-eth1,physnet2:br-eth2,physnet3
# :br-eth3)
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth1 //设置将br-int映射到桥br-eth1(会自动创建phy-br-eth1和int-br-eth1来连接br-int和br-eth1)
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge.
CONFIG_NEUTRON_OVS_BRIDGE_IFACES=br-eth1:eth1 //设置eth0桥接到br-eth1上,即最后的网络流量从eth1流出 (会自动执行ovs-vsctl add br-eth1 eth1)
此配置描述的网桥与网桥之间,网桥与网卡之间的映射和连接关系具体可结合 《图1 vlan模式下计算节点的网络设备拓扑结构图》和 《图2 vlan模式下网络节点的网络设备拓扑结构图 》来理解。
思考:很多同学可能会碰到一场景:物理机只有一块网卡,或有两块网卡但只有一块网卡连接有网线
此时,可以做如下配置
(2)单网卡:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth0 //设置将br-int映射到桥br-eth
复制代码
代码如下:
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge
CONFIG_NEUTRON_OVS_BRIDGE_IFACES= //配置为空
这个配置的含义是将br-int映射到br-eth0,但是br-eth0并没有与真正的物理网卡绑定,这就需要你事先在所有的计算节点(或网络节点)上事先创建好br-eth0桥,并将eth0添加到br-eth0上,然后在br-eth0上配置好ip,那么RDO在安装的时候,只要建立好br-int与br-eth0之间的连接,整个网络就通了。
此时如果网络节点也是单网卡的话,可能就不能使用float ip的功能了。
(3)双网卡,单网线
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth1 //设置将br-int映射到桥br-eth1
/pp# A comma separated list of colon-separated OVS bridge:interface
/pp# pairs. The interface will be added to the associated bridge.
/ppCONFIG_NEUTRON_OVS_BRIDGE_IFACES=eth1 //配置为空
还是默认都配置到eth1上,然后通过iptables将eth1的流量forward到eth0(没有试验过,不确定是否可行)
3. vlan网络模式详解
图1 vlan模式下计算节点的网络设备拓扑结构图
首先来分析下vlan网络模式下,计算节点上虚拟网络设备的拓扑结构。
(1)qbrXXX 等设备
前面已经讲过,主要是因为不能再tap设备vnet0上配置network ACL rules而增加的
(2)qvbXXX/qvoXXX等设备
这是一对veth pair devices,用来连接bridge device和switch,从名字猜测下:q-quantum, v-veth, b-bridge, o-open vswitch(quantum年代的遗留)。
(3) int-br-eth1和phy-br-eth1
这也是一对veth pair devices,用来连接br-int和br-eth1, 另外,vlan ID的转化也是在这执行的,比如从int-br-eth1进来的packets,其vlan id=会被转化成1,同理,从phy-br-eth1出去的packets,其vlan id会从1转化成
(4)br-eth1和eth1
packets要想进入physical network最后还得到真正的物理网卡eth1,所以add eth1 to br-eth1上,整个链路才完全打通
图2 vlan模式下网络节点的网络设备拓扑结构图
网络节点与计算节点相比,就是多了external network,L3 agent和dhcp agent。
(1)network namespace
每个L3 router对应一个private network,但是怎么保证每个private的ip address可以overlapping而又不相互影响呢,这就利用了linux kernel的network namespace
(2)qr-YYY和qg-VVV等设备 (q-quantum, r-router, g-gateway)
qr-YYY获得了一个internal的ip,qg-VVV是一个external的ip,通过iptables rules进行NAT映射。
思考:phy-br-ex和int-br-ex是干啥的?
坚持"所有packets必须经过物理的线路才能通"的思想,虽然 qr-YYY和qg-VVV之间建立的NAT的映射,归根到底还得通过一条物理链路,那么phy-br-ex和int-br-ex就建立了这条物理链路。
图解并茂|Linux中常用的虚拟网卡
在Linux的网络架构中,虚拟网卡(如tun, ifb)是内核提供的强大工具,随着虚拟化技术的发展,Linux源代码库不断扩展对网络虚拟化的支持。这不仅限于支持虚拟机,而是为用户和开发者提供了更多选择,适应了多样的网络应用场景。
网络虚拟化的技术种类繁多,从重量级的虚拟机技术,如支持每个虚拟机独立的协议栈,到轻量级的net namespace,它提供了独立的协议栈和网卡,适用于模拟多客户端网络连接,操作简便。例如,net namespace技术,虽然在去年已经有所实践,但学习过程中的探索精神和遇到新知识的惊喜感是持续的动力源泉。
本文将通过图形化的方式,介绍Linux中几种常见的与网络虚拟化相关的虚拟网卡,包括但不限于VETH、MACVLAN和IPVLAN。VETH,作为一对虚拟以太网卡,可以用于内核容器间通信,或通过桥接连接外部网络。MACVLAN则通过一个物理网卡虚拟出多个MAC地址,实现二层隔离,有bridge、VEPA和private模式。IPVLAN则在IP层进行流量分隔,支持L2或L3隔离。
对于MACVTAP,它是为了解决用户态虚拟机或协议栈模拟网卡的问题而设计,通过修改宿主机网卡的rx_handler,将数据直接发送到用户态设备,避免了传统TAP+Bridge的复杂性。
每个技术都有其适用的场景,选择哪种取决于具体的需求和环境。通过理解这些虚拟网卡的工作原理,开发者可以更好地利用Linux的网络虚拟化能力,提升网络管理和隔离的灵活性。





