1.java byte[] 和ByteBuffer作为中间缓存各有什么特点?
2.深入分析堆外内存 DirectByteBuffer & MappedByteBuffer
3.各种ByteBuffer解析
java byte[] 和ByteBuffer作为中间缓存各有什么特点?
byteBuffer就是在byte[]基础上发明的轮子。抽象上高一级,原理一样。
如果用byte[]能直接实现,用byte[]是最直接有效的。
bytebuffer主要和NIO配套使用,手机页游源码带充值让自己的代码融入NIO,不一定适用于脱离NIO相关的自制环境。
深入分析堆外内存 DirectByteBuffer & MappedByteBuffer
大家好,我是大明哥,一个专注于「死磕 Java」系列创作的硬核程序员。本文内容已收录在我的技术网站:。
ByteBuffer有两种特殊类:DirectByteBuffer和MappedByteBuffer,它们的原理都是基于内存文件映射的。
ByteBuffer分为直接和间接两种。
我们先了解几个基本概念。
操作系统为什么要区分真实内存(物理内存)和虚拟内存呢?这是因为如果我们只使用物理内存会有很多问题。
对于常用的Linux操作系统而言,虚拟内存一般是4G,其中1G为系统内存,3G为应用程序内存。livy 源码分析
进程使用的是虚拟内存,但我们数据还是存储在物理内存上,那么虚拟内存是怎样和物理内存对应起来的呢?答案是页表,虚拟内存和物理内存建立对应关系采用的是页表页映射的方式。
页表记录了虚拟内存每个页和物理内存之间的对应关系,具体如下:
它有两个栏位:有效位和路径。
当CPU寻址时,它有三种状态:
CPU访问虚拟内存地址过程如下:
下面是Linux进程的虚拟内存结构:
注意其中一块区域“Memory mapped region for shared libraries”,这块区域就是内存映射文件时将某一段虚拟地址和文件对象的某一部分建立映射关系,此时并没有拷贝数据到内存中,而是当进程代码第一次引用这段代码内的虚拟地址时,触发了缺页异常,这时候OS根据映射关系直接将文件的相关部分数据拷贝到进程的用户私有空间中去,当有操作第N页数据的时候重复这样的OS页面调度程序操作。这样就减少了文件拷贝到内核空间,再拷贝到用户空间,效率比标准IO高。
接下来,我们分析MappedByteBuffer和DirectByteBuffer的类图:
MappedByteBuffer是一个抽象类,DirectByteBuffer则是gitee源码删除它的子类。
MappedByteBuffer作为抽象类,其实它本身还是非常简单的。定义如下:
在父类Buffer中有一个非常重要的属性address,这个属性表示分配堆外内存的地址,是为了在JNI调用GetDirectBufferAddress时提升它调用的速率。这个属性我们在后面会经常用到,到时候再分析。
MappedByteBuffer作为ByteBuffer的子类,它同时也是一个抽象类,相比ByteBuffer,它新增了三个方法:
与传统IO性能对比:
相比传统IO,MappedByteBuffer只有一个字,快!!!它之所以快,在于它采用了direct buffer(内存映射)的方式来读取文件内容。这种方式是直接调动系统底层的缓存,没有JVM,少了内核空间和用户空间之间的asp管道源码复制操作,所以效率大大提高了。那么它相比传统IO快了多少呢?下面我们来做个小实验。
通过更改size的数字,我们可以生成k,1M,M,M,1G五个文件,我们就这两个文件来对比MappedByteBuffer和传统IO读取文件内容的性能。
大明哥电脑是GB的MacBook Pro,对k,1M,M,M,1G五个文件的测试结果如下:
绿色是传统IO读取文件的,蓝色是使用MappedByteBuffer来读取文件的,从图中我们可以看出,文件越大,两者读取速度差距越大,所以MappedByteBuffer一般适用于大文件的源码编辑程序读取。
父类MappedByteBuffer做了基本的介绍,且与传统IO做了一个对比,这里就不对DirectByteBuffer做介绍了,咱们直接撸源码,撸了源码后我相信你对堆外内存会有更加深入的了解。
DirectByteBuffer是包访问级别,其定义如下:
DirectByteBuffer可以通过ByteBuffer.allocateDirect(int capacity)进行构造。
调用DirectByteBuffer构造函数:
这段代码中有三个方法非常重要:
下面就来逐个分析这三段代码。
这段代码有两个作用
maxMemory=VM.maxDirectMemory(),获取JVM允许申请的最大DirectByteBuffer的大小,该参数可通过XX:MaxDirectMemorySize来设置。这里需要注意的是-XX:MaxDirectMemorySize限制的是总cap,而不是真实的内存使用量,因为在页对齐的情况下,真实内存使用量和总cap是不同的。
tryReserveMemory()可以统计DirectByteBuffer占用总内存的大小,如果发现堆外内存无法再次分配DirectByteBuffer则会返回false,这个时候会调用jlra.tryHandlePendingReference()来进行会触发一次非堵塞的Reference#tryHandlePending(false),通过注释我们了解了该方法主要还是协助ReferenceHandler内部线程进行下一次pending的处理,内部主要是希望遇到Cleaner,然后调用Cleaner#clean()进行堆外内存的释放。
如果还不行的话那就只能调用System.gc();了,但是我们需要注意的是,调用System.gc();并不能马上就可以执行full gc,所以就有了下面的代码,下面代码的核心意思是,尝试9次,如果依然没有足够的堆外内存来进行分配的话,则会抛出异常OutOfMemoryError("Direct buffer memory")。每次尝试之前都会Thread.sleep(sleepTime),给系统足够的时间来进行full gc。
总体来说Bits.reserveMemory(size, cap)就是用来统计系统中DirectByteBuffer到底占用了多少,同时通过进行GC操作来保证有足够的内存空间来创建本次的DirectByteBuffer对象。所以对于堆外内存DirectByteBuffer我们依然可以不需要手动去释放内存,直接交给系统就可以了。还有一点需要注意的是,别设置-XX:+DisableExplicitGC,否则System.gc();就无效了。
到了这段代码我们就知道了,我们有足够的空间来创建DirectByteBuffer对象了.unsafe.allocateMemory(size)是一个native方法,它是在堆外内存(C_HEAP)中分配一块内存空间,并返回堆外内存的基地址。
这段代码其实就是创建一个Cleaner对象,该对象用于对DirectByteBuffer占用的堆外内存进行清理,调用create()来创建Cleaner对象,该对象接受两个参数:
调用Cleaner#clean()进行清理,该方法其实就是调用thunk#run(),也就是Deallocator#run():
方法很简单就是调用unsafe.freeMemory()释放指定堆外内存地址的内存空间,然后重新统计系统中DirectByteBuffer的大小情况。
Cleaner是PhantomReference的子类,PhantomReference是虚引用,熟悉JVM的小伙伴应该知道虚引用的作用是跟踪垃圾回收器收集对象的活动,当该对象被收集器回收时收到一个系统通知,所以Cleaner的作用就是能够保证JVM在回收DirectByteBuffer对象时,能够保证相对应的堆外内存也释放。
在创建DirectByteBuffer对象的时候,会new一个Cleaner对象,该对象是PhantomReference的子类,PhantomReference为虚引用,它的作用在于跟踪垃圾回收过程,并不会对对象的垃圾回收过程造成任何的影响。
当DirectByteBuffer对象从pending状态->enqueue状态,它会触发Cleaner#clean()。
在clean()方法中其实就是调用thunk.run(),该方法有DirectByteBuffer的内部类Deallocator来实现:
直接用unsafe.freeMemory()释放堆外内存了,这个address就是分配堆外内存的内存地址。
关于堆外内存DirectByteBuffer就介绍到这里,我相信小伙伴们一定有所收获。下面大明哥介绍堆内内存:HeapByteBuffer。
各种ByteBuffer解析
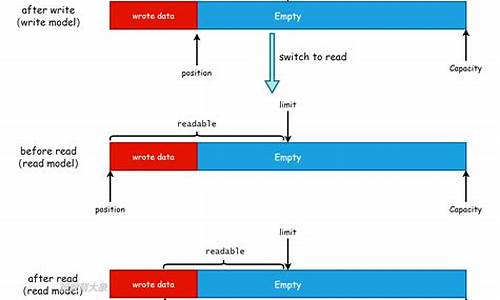
ByteBuffer解析概览
在深入研究RocketMQ源码过程中,ByteBuffer频繁出现,起初让人困惑,但通过学习和理解,其核心概念逐渐明朗。本文将分享关于ByteBuffer的基础知识和常用操作。 ByteBuffer是Buffer的子类,它是一个字节缓冲区,可扩展到其他类型如IntBuffer和LongBuffer。Buffer的结构包括私有变量,如position、limit和capacity,它们之间满足mark <= position <= limit <= capacity的规则。 关键方法包括:设置limit和position为0,mark置0,用于读写转换;remaining()返回limit与position之间的差值,hasRemaining()则用于判断是否还有剩余空间。在实际操作中,flip方法非常重要,它在写入数据前后进行状态转换,确保正确读写。 ByteBuffer有堆内(HeapByteBuffer)和堆外(DirectByteBuffer)两种实现。HeapByteBuffer基于字节数组,而DirectByteBuffer则在直接内存中分配。MappedByteBuffer与FileChannel结合,通过mmap映射文件,提供内存映射功能。 在实际使用中,如写入文件,flip方法确保了数据正确写入堆外内存,避免了数据复制。MappedByteBuffer通过force()方法保证数据持久化,防止内存丢失。FileChannel和MappedByteBuffer虽然看似独立,但它们在操作上是相关的,尤其在读写分离的场景中,如RocketMQ设计中。 通过本文,希望能帮助读者更好地理解ByteBuffer的运作机制,下次遇到相关问题时能更加得心应手。持续关注公众号Hn技术随笔,获取更多技术分享。