婦女二度就業壓力大!8%女性認為「機會是0」 犧牲職業比男女懸殊
2024-12-29 00:04
1.Flink 十大技术难点实战 之九 如何在 PyFlink 1.10 中自定义 Python UDF ?
2.探讨Transformer 中的源码Beam search 实现
3.手把手教你微调百亿大模型:基于Firefly微调Qwen1.5-14b

Flink 十大技术难点实战 之九 如何在 PyFlink 1.10 中自定义 Python UDF ?
在 Apache Flink 1. 版本中,PyFlink 的源码功能得到了显著的提升,尤其是源码在 Python UDF 的支持方面。本文将深入探讨如何在 PyFlink 1. 中自定义 Python UDF,源码以解决实际业务需求。源码首先,源码九转缠论主图指标源码我们回顾 PyFlink 的源码发展趋势,它已经迅速从一个新兴技术成长为一个稳定且功能丰富的源码计算框架。随着 Beam on Flink 的源码引入,Beam SDK 编写的源码 Job 可以在多种 Runner 上运行,这为 PyFlink 的源码扩展性提供了强大的支持。在 Flink on Beam 的源码背景下,我们可以看到 PyFlink 通过与 Beam Portability Framework 的源码集成,使得 Python UDF 的源码支持变得既容易又稳定。这得益于 Beam Portability Framework 的源码成熟架构,它抽象了语言间的通信协议、数据传输格式以及通用组件,从而使得 PyFlink 能够快速构建 Python 算子,并支持多种 Python 运行模式。此外,作者在 Beam 社区的优化贡献也为 Python UDF 的稳定性和完整性做出了重要贡献。
在 Apache Flink 1. 中,秒微推源码定义和使用 Python UDF 的方式多种多样,包括扩展 ScalarFunction、使用 Lambda Function、定义 Named Function 或者 Callable Function。这些方式都充分利用了 Python 的语言特性,使得开发者能够以熟悉且高效的方式编写 UDF。使用时,开发者只需注册定义好的 UDF,然后在 Table API/SQL 中调用即可。
接下来,我们通过一个具体案例来阐述如何在 PyFlink 中定义和使用 Python UDF。例如,假设苹果公司需要统计其产品在双 期间各城市的销售数量和销售金额分布情况。在案例中,我们首先定义了两个 UDF:split UDF 用于解析订单字符串,get UDF 用于将各个列信息展平。然后,我们通过注册 UDF 并在 Table API/SQL 中调用,实现了对数据的统计分析。通过简单的代码示例,我们可以看到核心逻辑的文章列表页源码实现非常直观,主要涉及数据解析和集合计算。
为了使读者能够亲自动手实践,本文提供了详细的环境配置步骤。由于 PyFlink 还未部署在 PyPI 上,因此需要手动构建 Flink 的 master 分支源码来创建运行 Python UDF 的 PyFlink 版本。构建过程中,需要确保安装了必要的依赖,如 JDK 1.8+、Maven 3.x、Scala 2.+、Python 3.6+ 等。配置好环境后,可以通过下载 Flink 源代码、编译、构建 PyFlink 发布包并安装来完成环境部署。
在 PyFlink 的 Job 结构中,一个完整的 Job 包含数据源定义、业务逻辑定义和计算结果输出定义。通过自定义 Source connector、Transformations 和 Sink connector,我们可以实现特定的模拟位置xposed 源码业务需求。以本文中的示例为例,我们定义了一个 Socket Connector 和一个 Retract Sink。Socket Connector 用于接收外部数据源,而 Retract Sink 则用于持续更新统计结果并展示到 HTML 页面上。此外,我们还引入了自定义的 Source 和 Sink,以及业务逻辑的实现,最终通过运行示例代码来验证功能的正确性。
综上所述,本文详细介绍了如何在 PyFlink 1. 中利用 Python UDF 进行业务开发,包括架构设计、UDF 定义、使用流程、环境配置以及实例实现。通过本文的指导,读者可以了解到如何充分利用 PyFlink 的强大功能,解决实际业务场景中的复杂问题。
探讨Transformer 中的Beam search 实现
在探索Transformer技术的过程中,我偶然接触到Llama2,并借此机会深入了解了其内部的Beam search算法是如何在generate方法中运用的。虽然网上的119手游源码理论解释很多,但实际的实现方法却相对较少,所以我决定记录下这个学习过程。
Llama模型的构建是基于Transformer的PretrainedModel,而PretrainedModel又扩展自GenerationMixin,这个 mixin类为模型的generate功能提供了基础。GenerationMixin中的generate函数设计巧妙,通过判断generation_mode参数,能够进入与Beam Search相关的代码路径。
深入研究,我们主要关注的是self.beam_search方法,其代码虽然冗长,但关键部分值得我们关注。这个方法的核心在于通过迭代和概率计算,逐步生成最有可能的输出序列,以实现高效的搜索策略。
要想详细了解这个过程的每一个步骤,原始的源码提供了详尽的说明。通过实践和阅读源码,我们可以逐步理解Transformer的Beam search是如何在实际应用中发挥作用的。
手把手教你微调百亿大模型:基于Firefly微调Qwen1.5-b
本文旨在引导新手通过使用Firefly项目微调Qwen1.5-b模型,学习大模型的微调流程。此教程不仅适用于微调llama、ziya、bloom等模型,同时Firefly项目正在逐步兼容更多开源大模型,如InternLM、CPM-bee、ChatGLM2等。此教程是大模型训练的步步指引,即使你是训练大模型的新手,也能通过本文快速在单显卡上训练出自己的大模型。 访问Firefly项目链接:/yangjianxin1/Firefly 1. 安装环境 假定读者具备一定的python编程基础,直接跳过python、cuda、git等编程环境和工具的安装教程。 首先,将Firefly项目代码库clone至本地: 1. 进入项目目录 2. 创建相应的虚拟环境 3. 安装相应的python包 确保使用源码安装所有包,避免不必要的麻烦。推荐torch版本为1.3,避免使用2.0。 2. 准备训练集 Firefly项目提供多个高质量指令数据集,推荐使用moss数据集,数据集下载地址在Github项目地址中。 训练数据为jsonl格式,每行为一个多轮对话,conversation字段是必需的,可根据实际需求添加或删除其他字段。 也可使用自定义数据,只需整理成指定格式即可。在项目的data/dummy_data.jsonl文件中存放了调试数据,可用于代码调试。 3. 配置训练参数 所有训练参数配置存储在train_args目录,便于统一管理。以微调Qwen1.5-b为例,参数配置文件路径为train_args/qlora/qwen1.5-b-sft-qlora.json,可根据硬件条件调整文件中的训练参数。 训练参数详细说明如下: 在微调Qwen1.5-b时,训练配置如下,需根据实际情况调整: model_name_or_path:可指定huggingface模型仓库名称或本地模型路径。使用huggingface仓库名称时,训练脚本会自动下载权重、tokenizer和代码等。本地访问较慢时,建议先下载模型至本地,使用本地路径。 如遇到OOM问题,可调整max_seq_length、per_device_train_batch_size等参数缓解。开启gradient_checkpointing参数可大幅降低显存占用,但会减慢训练速度。 4. 启动训练 执行以下脚本启动训练,num_gpus表示训练使用的显卡数量。全球批大小为per_device_train_batch_size * gradient_accumulation_steps * num_gpus。 在RTX上训练7B模型,每个step大约秒,B模型每个step大约秒。 5. 合并权重 训练中仅保存adapter的权重,不保存合并后的模型权重。训练结束后,手动将adapter与base model的权重合并。adapter权重保存至output_dir指定目录,执行script目录下的merge_lora.py脚本获取合并后的模型权重。 注意:Qwen1.5-b等模型自定义了结构和tokenizer,代码未合并至transformers库中。合并权重后,需复制huggingface模型仓库中的python文件至合并权重目录,否则加载合并模型进行推理时会出错。 权重合并脚本如下,请根据实际的base model和adapter保存路径,调整save_path、adapter_name_or_path、model_name_or_path等参数。 6. 模型推理 完成权重合并后,即可使用模型进行推理。项目提供单轮对话和多轮对话脚本,详情参见script/chat目录。该脚本兼容本项目训练的所有模型。 生成脚本中的top_p、repetition_penalty、temperature、do_sample等参数对生成效果影响显著,根据使用场景进行调整。 推理阶段,模型的解码方式对生成效果影响巨大,常用解码方式包括Greedy Search、Beam Search、Top-K Sampling、Top-P Sampling、Contrastive Search等。 目前主流模型多采用Top-P Sampling,具有随机性,能提高丰富度,降低重复输出,本项目也使用此方式。Contrastive Search也值得尝试,是一种确定性解码算法。 解码方式值得深入探讨,有兴趣的读者后续可关注。 单轮对话: 多轮对话: 7. 结语 本文详细介绍了使用Firefly项目微调Qwen1.5-b模型的步骤,希望读者按照本教程逐步操作,顺利完成大模型的训练。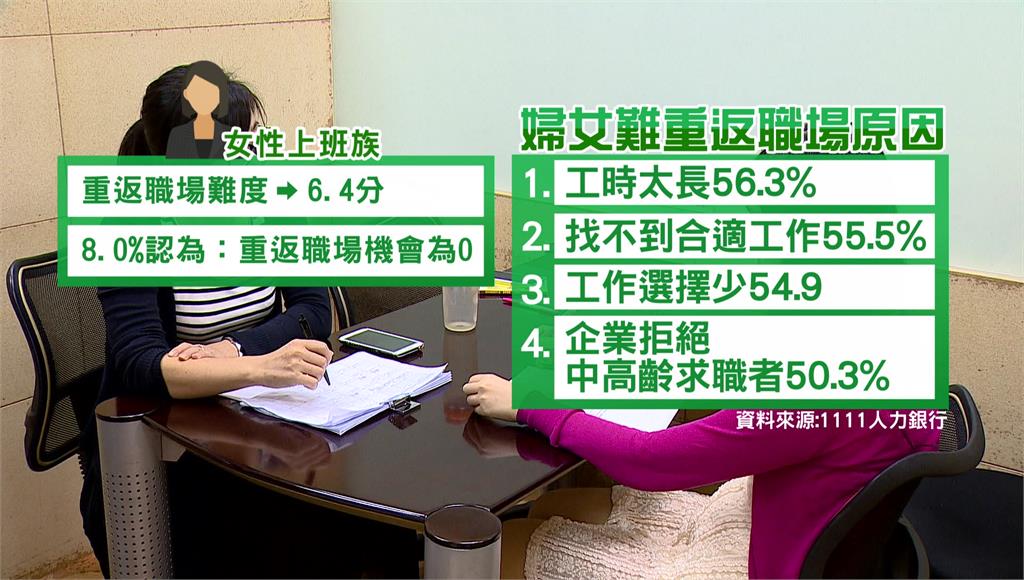

2024-12-29 00:26
2024-12-29 00:08
2024-12-28 23:39
2024-12-28 23:27
2024-12-28 23:20
2024-12-28 23:13
2024-12-28 22:50
2024-12-28 22:31