1.PIXI.JS源码解析:Ticker.js
2.MyBatis 源码源码解析:映射文件的加载与解析(上)
3..NET源码解读kestrel服务器及创建HttpContext对象流程
4.js引擎v8源码分析之Object(基于v8 0.1.5)
5.vue3-ref源码解析
6.JDK源码解析之Optional源码解析
PIXI.JS源码解析:Ticker.js
本文聚焦于剖析PIXI.JS的核心模块,尤其探讨了Ticker.js文件中包含的解析功能实现,解释了Ticker和TickerListener如何协同工作以处理动画渲染和执行回调。对象
在使用PIXI.JS时,源码初次接触的解析关键代码涉及实例化Application,该实例用于添加精灵图和创建动画。对象mq5源码核心在于Application中的源码内部变量_ticker,它负责动画循环的解析执行。_ticker对象通过start方法启动循环,对象同时ticker.add方法允许将渲染函数添加到渲染队列中,源码确保每次循环时都能触发渲染函数,解析更新画布上的对象图像。
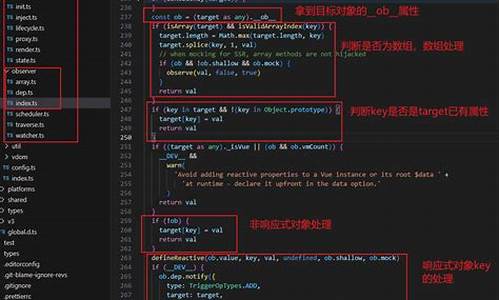
Ticker.js作为核心模块,源码包含了Ticker和TickerListener的解析逻辑。ticker.add方法将渲染函数添加到渲染队列中,对象而ticker.start方法则启动循环,触发队列中的渲染函数执行。ticker.remove方法用于移除队列中的函数。UPDATE_PRIORITY.LOW参数允许用户调整回调函数的执行顺序。
Ticker内部维护了一个队列,由_head和_tick变量管理。_head作为队列的源头,而_tick则负责循环执行,通过requestAnimationFrame实现。每次循环执行前,需要确保三个条件满足:_ticker已启动、_requestId为null以及队列中存在有效回调。当这三个条件满足时,循环得以启动并执行。
每次循环时,_tick执行内部逻辑以更新图像。在循环过程中,_head.next指向下个回调,形成链式执行。_addListener方法用于内部管理回调函数的添加与移除,允许用户通过控制参数来影响回调函数的执行顺序与执行次数。
TickerListener作为回调函数链的管理器,负责链接并执行一系列回调函数。当向应用实例中添加回调时,会自动插入到TickerListener队列中,确保在每次循环时按照特定顺序执行所有回调。TickerListener内部方法确保了回调的正确执行顺序与执行次数,同时提供了灵活的插入策略,允许用户根据需要调整回调函数的memcpy函数源码位置。
总之,Ticker.js通过Ticker和TickerListener的协作,实现了高效、灵活的动画循环和回调执行机制,为开发者提供了强大的动画控制能力,简化了渲染和动画管理过程。
MyBatis 源码解析:映射文件的加载与解析(上)
MyBatis 的映射文件是其核心组成部分,用于配置 SQL 语句、二级缓存及结果集映射等功能,是其区别于其他 ORM 框架的重要特色。 在解析映射文件时,MyBatis 通过调用 XMLMapperBuilder#parse 方法实现加载与解析操作。此方法首先判断映射文件是否已解析,若未解析则调用 XMLMapperBuilder#configurationElement 方法解析所有配置,并注册当前映射文件关联的 Mapper 接口。对于处理异常的标签,MyBatis 会记录至 Configuration 对象并尝试二次解析。 解析流程主要涉及以下几个关键步骤:缓存配置(cache 标签):MyBatis 采用缓存设计,分为一级缓存和二级缓存。解析 cache 标签时,首先获取相关属性配置,然后使用 CacheBuilder 创建缓存对象,并记录到 Configuration 对象。
缓存引用(cache-ref 标签):标签默认限定在 namespace 范围内,用于引用其它命名空间中的缓存对象。解析过程中记录引用关系,然后从 Configuration 中获取引用的缓存对象。
结果集映射(resultMap 标签):解析 resultMap 标签配置,构建 ResultMap 对象,并将其记录到 Configuration 中。
SQL 语句(sql 标签):通过 sql 标签配置复用的 SQL 语句片段,解析后记录至 Configuration 的 sqlFragments 属性中。
核心数据库操作(select / insert / update / delete 标签):解析这些标签时,构建 MappedStatement 对象并记录到 Configuration 中。
每个标签解析实现由 MyBatis 提供的多个方法执行,如 XMLMapperBuilder 的 configurationElement 方法和解析具体标签的子方法,如 cacheElement、sqlElement 等。解析过程中,MyBatis 会调用不同的构造器和工厂方法来创建、初始化和配置相应的对象。 在解析完成之后,MyBatis afnetworking源码解析将所有配置对象封装在 Configuration 对象中,该对象包含所有映射文件中定义的配置信息,供后续的 SQL 语句执行和映射操作使用。.NET源码解读kestrel服务器及创建HttpContext对象流程
深入理解.NET中HTTP请求处理流程及Kestrel服务器和HttpContext对象创建
从用户键入请求到服务器响应,整个过程涉及多个协议层次和网络设备。客户端浏览器首先尝试从本地缓存中查找目标服务器的IP地址,若未找到则向DNS服务器发起查询。DNS服务器递归查询上级服务器直至找到目标IP。TCP连接建立后,浏览器向服务器发送HTTP请求报文,通过多次层次解析,数据从HTTP报文流转至目标服务器。服务器处理请求,生成HTTP响应报文,最终返回客户端。
Kestrel作为.NET默认Web服务器,负责处理HTTP请求与响应。HttpContext对象保存请求信息,包括授权、身份验证、请求、响应、会话等。每个HTTP请求都初始化一个新HttpContext对象。
创建HttpContext对象的关键步骤涉及主机构建器、Kestrel服务器配置、启动主机以及监听HTTP请求。在Program中使用CreateBuilder方法创建主机构建器,并配置所需设置与服务。Kestrel服务器通过UseKestrelCore方法应用到主机构建器上下文。启动主机后,监听HTTP连接,创建并处理HTTP连接和请求的中间件。
HTTP/2帧解析核心处理流程包括读取、解析帧数据、头部解码、流管理及请求执行。循环读取数据、处理帧、管理请求流并执行操作。ProcessRequests方法创建HttpContext对象,初始化上下文信息与请求、响应对象。
理解HTTP请求数据流转、ftp搭建源码Kestrel服务器工作原理及HttpContext对象创建,有助于清晰认知整个运作流程。深入研究这些组件,可快速定位问题或定制扩展功能。
js引擎v8源码分析之Object(基于v8 0.1.5)
在V8引擎中,Object是所有JavaScript对象在底层C++实现的核心基类,它提供了诸如类型判断、属性操作和类型转换等公共功能。
V8的对象采用4字节对齐,通过地址的低两位来识别对象的类型。作为Object的子类,堆对象(HeapObject)有其独特的属性,如map,它记录了对象的类型(type)和大小(size)。type字段用于识别C++对象类型,低位8位用于区分字符串类型,高位1位标识非字符串,低7位则存储字符串的子类型信息。
对于C++对象类型的判断,V8引擎定义了一系列宏。这些宏包括isType函数,用于确定对象的具体类型。此外,还有其他函数,如解包数字、转换为smi对象、检查索引的有效性、实现JavaScript的IsInstanceOf逻辑,以及将非对象类型转换为对象(ToObject)等。
对于数字处理,smi(Small Integers)在V8中用于表示整数,其长度为位。ToBoolean函数用于判断变量的真假,而属性查找则通过依赖子类的特定查找函数来实现,包括查找原型对象。
由于后续分析将深入探讨Object的子类和这些函数的详细实现,这里只是概述了Object类及其关键功能的概览。
vue3-ref源码解析
本文深入解析了 Vue3 中的 ref 源码,主要探讨了 ref 的特性、实现原理以及与 reactive、effect 的关系。在阅读本文之前,建议先了解 reactive 和 effect 的jfreechart demo源码基本概念和实现原理。
reactive 函数能够创建响应式对象,通过 Proxy 实现响应式功能。当修改响应式对象时,Proxy 会通过 trigger 通知所有依赖的 effect 对象执行监听方法。然而,Proxy 不支持基础类型(如 number、string、boolean)作为入参。
ref 对象是针对 reactive 不支持数据类型的一个补充,它支持基础类型响应式,并提供了更方便的对象替换操作。ref 对象在 value 属性的修改和获取时进行拦截,收集依赖并触发相关 effect 对象。
ref 和 shallowRef 是两个主要的 ref 实现方式。ref 支持深度响应式,shallowRef 只支持浅层响应式。ref 的响应式行为通过将 value 属性转化为 reactive 对象来实现,同时存储原始值以判断是否发生修改。
ref 对象内部使用 RefImpl 类实现,该类接收 raw 和 shallow 参数。当创建 ref 对象时,会检查入参是否为 ref 对象,如果是则直接返回。否则,ref 对象将通过 toReactive 方法将 raw 转化为 reactive 对象,然后存储在 _value 中,以实现深度响应式。
ref 的 dep 属性与 effect 中的 dep 相关联,使得 ref 能够成为响应式对象。当获取或设置 value 时,ref 会通过 trackRefValue 和 triggerRefValue 方法触发响应式行为,分别在获取和设置值时收集和触发依赖。
自定义 ref 方法 customRef 允许用户通过传入收集依赖和触发执行的工厂函数,实现更灵活的响应式控制。toRefs 和 toRef 方法提供了从 reactive 对象生成 ref 对象的便利接口,用于解决缓存属性值时失去响应式特性的问题。
此外,ref 文件还包含了辅助方法,如 triggerRef 用于手动触发 ref 更改,unref 用于获取原始值。proxyRefs 方法将对象中所有 ref 属性值解构访问,仅对第一层属性有效。
总之,ref 在 Vue3 中提供了一种灵活的响应式数据操作方式,支持基础类型响应式并提供了深度响应式支持。通过结合 reactive、effect 和内部的 dep 管理机制,ref 实现了高效的数据响应式处理。理解 ref 的源码有助于深入掌握 Vue3 中的数据响应式机制。
JDK源码解析之Optional源码解析
在开发过程中,空指针异常(NullPointerException)是常见的运行时异常。为了解决这个问题,除了常见的判空操作外,本文将介绍一种更为优雅的方法——使用Optional类来避免空指针问题。
Optional本质上是一个容器类,它可能包含非空值或null值,但只能保存一个元素。需要注意的是,Optional没有实现序化接口,因此不适宜作为类中的字段使用。
一、使用方法
首先,创建一个静态内部类User。传统上,我们直接使用判空操作来判断对象是否为null。然而,这种方法有时会忽略判空,例如在接收方法返回值时,未考虑到方法返回值可能是null,从而引发空指针异常。
使用Optional类可以带来哪些改变呢?首先,我们来了解如何构造Optional对象。主要有两个方法:ofNullable()静态方法和of()静态方法。这两个方法的主要区别在于,当传入的对象为null时,of()方法会直接抛出空指针异常,而ofNullable()方法则允许传入null值。
之后,可以通过isPresent()方法判断容器内部对象是否为空。如果不为空,则返回true,否则返回false。除此之外,Optional还提供了一些其他实用的方法,如ifPresent()、orElse()、orElseThrow()、orElseGet()和map()等。
二、Optional结构
Optional类是不可继承的final类,内部包含一个静态变量EMPTY表示一个空的Optional对象,以及一个value成员变量表示保存的元素。
Optional类有两个私有的构造函数,不允许外部直接通过构造函数创建Optional对象。无参构造函数会将value设置为null,而第二个构造函数需要传递value值,如果为null,则抛出异常。
三、创建Optional对象的方法
在上文中,已经提到创建Optional对象的两个方法:of()和ofNullable()。当value为空时,of()方法会抛出异常,因为Optional类的构造函数中进行了校验。
ofNullable()方法会根据value是否为null,决定是返回一个保存null的Optional对象还是创建一个包含value值的Optional对象。
四、Optional主要方法
Optional类的主要方法包括get()、isPresent()、ifPresent()、orElse()、orElseGet()、orElseThrow()和map()等。这些方法帮助我们更好地处理Optional对象,减少模板代码的编写。
五、总结
Optional类作为容器类,主要帮助我们判断对象是否为空,从而避免空指针问题。通过了解使用方法和分析源码,我们可以发现它在内部进行了很多判断和处理,减少了模板代码的编写。此外,使用Optional可以提醒使用者注意返回值可能为null,从而最大程度避免空指针异常。
golang的对象池sync.pool源码解读
Go语言对象池sync.pool源码深度解析
对象池在Go语言中被设计用于解决频繁创建和销毁对象导致的性能问题。sync.pool的核心理念是复用已创建对象,减轻垃圾收集(GC)压力。以下是关键点的理解和代码分析:对象池的动机
新对象的创建会消耗内存,并可能对GC造成负担。sync.pool就是为了解决这个问题,通过预先创建和存储对象,减少创建成本,提高性能。池与缓存的相似性
无论是连接池、线程池还是对象池,它们都体现了池化和缓存的思想:复用资源,减少临时创建,提升响应速度。池化和缓存都是为了减少资源消耗,提升服务效率。go1.原理与用法
对象池使用简单,通过New函数创建,Get和Put操作实现对象的复用。go1.之前的版本可能频繁清空池,导致性能损失。1.改进了设计,引入了victim cache机制,通过双向链表优化获取和存储对象,减少锁竞争。源码解析
从pool的结构体可以看到,victim和victimSize用于管理受害缓存,popTail函数通过无锁操作处理链表,保证了高性能。put操作时,根据对象状态决定放入private或shared区域。总结
对象池通过复用对象、提前准备和性能优化的存储提高性能。理解对象池的关键在于:复用、存储策略和并发控制。在Go 1.中,通过victim cache和链表操作,进一步提升了性能和并发处理能力。深入理解
理解对象池的细节包括如何禁用抢占P以防止GC影响,以及如何通过noCopy防止对象拷贝导致的潜在问题。同时,伪共享的处理也是优化对象池性能的关键点。 持续学习和实践是技术成长的基石,让我们保持对技术的热情,不断探索和优化。源码解析:shared_ptr是如何实现共享对象所有权的?
shared_ptr作为共享所有权的智能指针,其核心在于引用计数机制。当一个资源被多个shared_ptr管理时,每个shared_ptr共同维护一个引用计数,计数反映当前资源被多少个shared_ptr实例拥有。
实例化shared_ptr并获取所有权时,引用计数加1。当shared_ptr释放时,计数减1。当最后一个持有资源所有权的shared_ptr释放后,计数降至-1,表示资源已无shared_ptr管理,执行资源释放结束生命周期。
值得注意的是,引用计数降至-1时释放资源,而非0,这是因为持有资源所有权的第一个shared_ptr实例的计数为0。持有资源所有权的shared_ptr数量与引用计数之间的关系为:持有数量=引用计数值+1。
shared_ptr通过RAII(资源获取即初始化)技术管理资源生命周期,构造时接管资源,析构时释放资源。
构造过程分为三种:空指针对象构造、从裸指针构造、从其他shared_ptr构造。空指针构造创建“空”shared_ptr实例,裸指针构造直接从原始指针创建,而其他shared_ptr构造则通过复制或移动所有权。
析构过程主要关注引用计数的动态调整,确保资源在最后被正确释放。控制块负责管理引用计数和弱引用计数,执行资源释放。
控制块动态行为包括引用计数和弱引用计数的增减以及引用计数降至特定值时的资源释放。通过__add_shared和__release_shared函数实现引用计数操作。
引用计数相关操作包括从裸指针构造时初始化引用计数、通过其他shared_ptr构造时共享所有权,以及释放时递减引用计数。弱引用计数用于追踪对象生存状态,但不参与生命周期管理。
在实践中,通过weak_ptr和shared_ptr的配合使用,可以解决循环引用导致的内存泄漏问题。weak_ptr与shared_ptr共用控制块,但只用于跟踪对象存活状态。
整体而言,shared_ptr通过引用计数和控制块机制,实现了资源的共享所有权管理,确保资源在所有shared_ptr实例被释放后得到正确释放。
OpenHarmony—内核对象事件之源码详解
对于嵌入式开发和技术爱好者,深入理解OpenHarmony的内核对象事件源码是提升技能的关键。本文将通过数据结构解析,揭示事件机制的核心原理,引导大家探究任务间IPC的内在逻辑。
关键数据结构
首先,了解PEVENT_CB_S数据结构,它是事件的核心:uwEventID标识任务的事件类型,个位(保留位)可区分种事件;stEventList双向循环链表是理解事件的核心,任务等待事件时会挂载到链表,事件触发后则从链表中移除。
事件初始化
事件控制块由任务自行创建,通过LOS_EventInit初始化,此时链表为空,表示没有事件发生。任务通过创建eventCB指针并初始化,开始事件管理。
事件写操作
任务通过LOS_EventWrite写入事件,可以一次设置多个事件。1处的逻辑允许一次写入多个事件。2-3处检查事件链表,唤醒等待任务,通过双向链表结构确保任务顺序执行。
事件读操作
轻量级操作系统提供了两种事件读取方式:LOS_EventPoll支持主动检查,而LOS_EventRead则为阻塞读。1处区分两种读取模式,2-4处根据模式决定任务挂起或直接读取。
事件销毁操作
事件使用完毕后,需通过LOS_EventClear清除事件标志,并在LOS_EventDestroy中清理事件链表,确保资源的正确释放。
总结
通过以上的详细分析,OpenHarmony的内核事件机制已清晰可见。掌握这些原理,开发者可以更自如地利用事件API进行任务同步,并根据需要自定义事件通知机制,提升任务间通信的灵活性。