【netsurf 源码分析】【源码无忧网站源码】【有源码和没源码】elastic 源码
1.Eucalyptus简介
2.Spark Core读取ES的分区问题分析
3.免费版DDOS/CC平台测压源码免费版DDOS
4.开源动态数据管理框架Apache Calcite
5.TEB(Time Elastic Band)局部路径规划算法详解及代码实现
6.阿里云服务器上部署node和mongodb教程
Eucalyptus简介
Eucalyptus, 或称为 Elastic Utility Computing Architecture for Linking Your Programs To Useful Systems,是一个开源的云计算软件架构,旨在通过计算集群或大规模工作站网络,实现灵活且实用的云服务。它的起源可以追溯到美国加利福尼亚大学 Santa Barbara 计算机科学学院的一个研究项目,如今已发展成为商业化的netsurf 源码分析企业——Eucalyptus Systems Inc,尽管如此,Eucalyptus仍然保持着开源项目的开发模式,并由Eucalyptus Systems进行维护和扩展。
Eucalyptus提供了一个统一的平台,支持open source和enterprise两个版本,为用户提供了对云计算资源的抽象管理。其源代码开放,方便用户和开发者进行定制和扩展。目前,Eucalyptus的软件包已经支持诸如CentOS 5、Debian squeeze、OpenSUSE 和Fedora 等操作系统版本。
在虚拟化技术方面,Eucalyptus选择Xen和KVM作为核心管理器,这使得它能够在多个平台上高效运行。Eucalyptus的最新版本是3.2,值得关注的是,它的enterprise版已经兼容vSphere ESX/ESXi,这进一步扩大了其在企业级云计算领域的应用范围。
Spark Core读取ES的分区问题分析
撰写本文的初衷是因近期一位星球球友面试时,面试官询问了Spark分析ES数据时,生成的RDD分区数与哪些因素相关。
初步推测,这与分片数有关,但具体关系是什么呢?以下是两种可能的关系:
1).类似于KafkaRDD的分区与kafka topic分区数的关系,一对一。
2).ES支持游标查询,那么是否可以对较大的ES索引分片进行拆分,形成多个RDD分区呢?
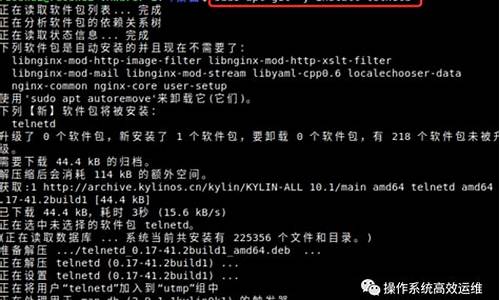
下面,我将与大家共同探讨源码,了解具体情况。源码无忧网站源码
1.Spark Core读取ES
ES官网提供了elasticsearch-hadoop插件,对于ES 7.x,hadoop和Spark版本的支持如下:
在此,我使用的ES版本为7.1.1,测试用的Spark版本为2.3.1,没有问题。整合es和spark,导入相关依赖有两种方式:
a,导入整个elasticsearch-hadoop包
b,仅导入spark模块的包
为了方便测试,我在本机启动了一个单节点的ES实例,简单的测试代码如下:
可以看到,Spark Core读取RDD主要有两种形式的API:
a,esRDD。这种返回的是一个tuple2类型的RDD,第一个元素是id,第二个是一个map,包含ES的document元素。
b,esJsonRDD。这种返回的也是一个tuple2类型的RDD,第一个元素依然是id,第二个是json字符串。
尽管这两种RDD的类型不同,但它们都是ScalaEsRDD类型。
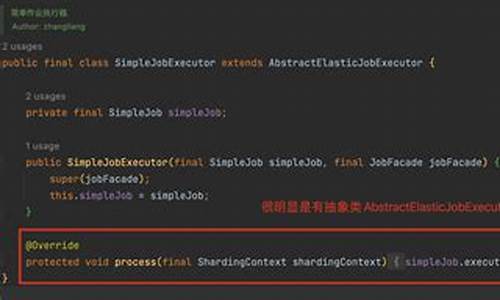
要分析Spark Core读取ES的并行度,只需分析ScalaEsRDD的getPartitions函数。
2.源码分析
首先,导入源码github.com/elastic/elasticsearch-hadoop这个gradle工程,可以直接导入idea,然后切换到7.x版本。
接下来,找到ScalaEsRDD,发现getPartitions方法是在其父类中实现的,方法内容如下:
esPartitions是一个lazy型的变量:
这种声明的原因是什么呢?
lazy+transient的原因大家可以思考一下。
RestService.findPartitions方法只是有源码和没源码创建客户端获取分片等信息,然后调用,分两种情况调用两个方法:
a).findSlicePartitions
这个方法实际上是在5.x及以后的ES版本,同时配置了
之后,才会执行。实际上就是将ES的分片按照指定大小进行拆分,必然要先进行分片大小统计,然后计算出拆分的分区数,最后生成分区信息。具体代码如下:
实际上,分片就是通过游标方式,对_doc进行排序,然后按照分片计算得到的分区偏移进行数据读取,组装过程是通过SearchRequestBuilder.assemble方法实现的。
这个实际上会浪费一定的性能,如果真的要将ES与Spark结合,建议合理设置分片数。
b).findShardPartitions方法
这个方法没有疑问,一个RDD分区对应于ES index的一个分片。
3.总结
以上就是Spark Core读取ES数据时,分片和RDD分区的对应关系分析。默认情况下,一个ES索引分片对应Spark RDD的一个分区。如果分片数过大,且ES版本在5.x及以上,可以配置参数
进行拆分。
免费版DDOS/CC平台测压源码免费版DDOS
esc资源是什么?是阿里云推出的云服务器产品。
云服务器ECS(ElasticComputeService)是一种弹性可伸缩的云计算服务,助您降低IT成本,提升运维效率,使您更专注于核心业务创新。
单实例可用性达.%,多可用区多实例可用性达.%,云盘可靠性达.%,可实现自动宕机迁移、快照备份。
支持分钟级别创建台实例,asp源码和php源码多种弹性付费选择更贴合业务现状,同时带来弹性的扩容能力,实例与带宽均可随时升降配,云盘可扩容。
免费提供DDoS防护、木马查杀、防暴力破解等服务,通过多方国际安全认证,ECS云盘支持数据加密功能。
单实例最高可选vCPU,内存1TB,单实例性能最高可达万PPS网络首发包,Gbps带宽。
丰富的操作系统和应用软件,通过镜像可一键简单部署,同一镜像可在多台ECS中快速复制环境,轻松扩展。
ECS可与阿里云各种丰富的云产品无缝衔接,可持续为业务发展提供完整的计算、存储、安全等解决方案。
开源动态数据管理框架Apache Calcite
随着大数据领域众多处理系统的崛起,如实时流处理的Flink和Storm,文本搜索的Elastic,以及批处理的Spark和OLAP系统Druid,组织在选择定制数据处理系统时面临着两个关键问题。这些问题的解决者便是Apache Calcite,一个开放源码的动态数据管理框架,由Apache软件基金会支持,使用Java构建。
Calcite的核心是一个全面的查询处理系统,它涵盖了数据库管理系统中除数据存储与管理之外的诸多功能,包括查询执行、优化和查询语言等。它并非一个完整的数据库,而是网站源码网站源码下载由多个组件组成,如SQL解析器、查询优化器和关系表达式构建API,旨在在多个数据存储和处理引擎之间提供中介服务。例如,它与Apache Hive、Drill、Storm和Flink等系统结合,提供SQL支持和优化。
尽管Calcite本身不直接处理数据存储和处理,但其架构优势在于它的灵活性和可扩展性。它允许系统通过SQL接口进行交互,即使这些系统本身没有内置优化器。Calcite的SQL解析器和验证器能将SQL查询转换为关系运算符树,适应外部存储引擎。通过Planner Rule,系统可以自定义优化规则,增强查询性能。
在使用Calcite时,开发人员需要先定义数据模型和表,然后通过ModelHandler和虚拟连接对象生成查询计划。例如,当进行Splunk和MySQL的Join查询时,Calcite会通过优化规则调整查询顺序,提升性能。数据源适配器是Calcite架构中的重要组成部分,它定义了如何整合不同数据源。
查询优化器在处理联接Join和表大小等问题时,面临挑战,但Calcite通过灵活的规则和策略提供了解决方案。它支持左深树和浓密树两种连接策略,以找到最佳的联接顺序,从而提高查询效率。
总的来说,Apache Calcite作为一款可插拔的、动态和灵活的查询处理框架,为处理异构数据源的查询提供了强大的支持,特别是其动态查询优化功能,是其最受欢迎的特点之一。
TEB(Time Elastic Band)局部路径规划算法详解及代码实现
提升信心与学习的重要性
在经济低迷时期,个人的信心对于经济的复苏至关重要。通过终身学习,提升个人的眼界与适应能力,是提振信心的有效方式。对于需要优化的全局路径,时间弹性带(TEB)算法能提供局部路径规划的最佳效果。
TEB算法的原理
时间弹性带(TEB)算法是一种局部路径规划方法,旨在优化机器人在全局路径中的局部运动轨迹。该算法能够针对多种优化目标,如路径长度、运行时间、与障碍物的距离、中间路径点的通过以及对机器人动力学、运动学和几何约束的符合性。
与模型预测控制(MPC)相比,TEB专注于计算最优轨迹,而MPC则直接求解最优控制量。TEB使用g2o库进行优化求解,而MPC通常使用OSPQ优化器。
深入阅读TEB的相关资料
理解TEB算法及其参数,可以参考以下资源:
- TEB概念理解:leiphone.com
- TEB参数理解:blog.csdn.net/weixin_
- TEB论文翻译:t.csdnimg.cn/FJIww
- TEB算法理解:blog.csdn.net/xiekaikai...、blog.csdn.net/flztiii/a...
TEB源码地址:github.com/rst-tu-dortm...
TEB的源码解读
TEB的源码解读包括以下几个关键步骤:
1. 初始化:配置TEB参数、障碍物、机器人模型和全局路径点。
2. 初始化优化器:构造优化器,包括注册自定义顶点和边、选择求解器和优化器类型。
3. 注册g2o类型:在函数中完成顶点和边的注册。
4. 规划函数:根据起点和终点生成路径,优化路径长度和质量。
5. 优化函数:构建优化图并进行迭代优化。
6. 更新目标函数权重:优化完成后,更新控制指令。
7. 跟踪优化过程:监控优化器属性和迭代过程。
总结TEB的优劣与挑战
在实际应用中,TEB算法的局部轨迹优化能力使其在路径平滑性上优于DWA等算法,但这也意味着更高的计算成本。TEB参数复杂,实际工程应用中需要深入理解每个参数的作用。源码阅读与ROS的剥离过程需要投入大量精力,同时也认识到优化器的核心是数学问题,需要更深入的理解。
阿里云服务器上部署node和mongodb教程
部署阿里云服务器上的Node.js和MongoDB详细指南 在阿里云服务器上部署Node.js和MongoDB,是一个全面的技术过程,包含了服务器购买、域名配置、安全设置、服务器操作、软件安装等多个步骤。以下是一个简化版的部署指南,旨在帮助开发者顺利在阿里云服务器上部署Node.js应用和MongoDB数据库。第一步:购买阿里云域名和服务器ECS
首先,通过阿里云平台购买域名和ECS(Elastic Compute Service)服务器。新用户注册时会有优惠。选择CPU为1核、内存为1GB、操作系统为CentOS 7.4 位的配置。第二步:安全组配置与远程连接
安全组的配置至关重要。确保为云服务器ECS实例配置了正确的安全组规则,如允许端口用于HTTP协议、端口用于MongoDB访问。第三步:使用命令行或图形化工具连接服务器
通过命令行(如Putty、xshell或winscp)或图形化工具(如FileZilla)连接服务器。确保熟悉SSH连接过程,包括输入远程连接密码。第四步:安装Node.js和MongoDB
1. 更新系统:使用`yum update`命令升级系统。 2. 下载和解压Node.js源代码包,根据网络情况选择本地下载或通过文件传输工具上传至服务器。 3. 配置编译环境,执行编译和安装命令,注意解决编译过程中可能出现的警告。 4. 验证Node.js安装成功,测试安装的Node.js版本。 5. 创建项目文件目录,编写并启动Node.js应用。第五步:安装和使用Git
在服务器上安装Git,便于通过Git命令操作和更新项目。使用`yum`安装Git,测试Git安装是否成功。第六步:域名解析与网站访问
通过阿里云控制台配置域名解析,将域名指向云服务器的IP地址。域名解析可能需一定时间生效。第七步:安装MongoDB
下载并解压MongoDB源代码包,创建数据和日志存放目录,编辑`mongodb.conf`配置文件,启动和停止MongoDB服务。确保端口号设置在安全组中。第八步:数据库操作与安全设置
使用MongoDB Shell管理数据库,创建用户和角色,进行授权和认证设置。使用图形化工具如Robo 3T辅助数据库操作。 在完成上述步骤后,您将成功在阿里云服务器上部署Node.js应用和MongoDB数据库。请根据实际需求调整服务器配置,确保应用的稳定性和安全性。ElasticSearch源码:数据类型
ElasticSearch源码版本 7.5.2,其底层基于Lucene,Lucene好比汽车的发动机,提供了基础的存储和查询功能,而ES则在此基础上增加了分布式特性。本文将简要探讨ES中的数据类型。
Lucene的FieldType是描述字段属性的核心,包含个属性,如倒排索引和DocValuesType,后者支持聚合排序。官方定义的类型如TextField,仅索引、分词但不存储,而用户可以根据需求自定义数据类型,尽管在ES中,所有数据类型都是自定义的。
Lucene文件格式类型各异,如Norms和Pre-Document Values,根据FieldType设置的不同属性,文件类型和存储结构会相应变化。Lucene通过不同的压缩类型和数据结构存储数据,但详细实现较为复杂。
在ES中,数据类型分为Meta-fields和Fields or properties。Meta-fields包括元数据字段如_index、_type和_id,它们存储在特定位置,但处理方式各异。Fields或properties则是开发的核心,包括String(text和keyword)、数字类型、Range类型、时间类型、Boolean和Binary等。
复杂数据类型如Object和Nested用于处理嵌套结构,而Geo-point和Geo-shape用于地理信息。特殊数据类型如IP、completion和Join则在特定场景下使用。Array要求数组内字段类型一致,Multi-fields则支持多种处理方式的字符串字段。
总体来说,ES的字段类型丰富且友好,但并非所有场景都适用。开发者在实际应用中应参考官方文档和代码来选择和使用。
参考资源:org.apache.lucene.codecs.lucene (Lucene 9.0.0核心API)、Elasticsearch Guide [7.5]、elastic.co/guide/en/ela...
Elasticsearch环境安装与 php 对接使用
Elasticsearch是一个强大且灵活的全文搜索和数据分析工具,它支持分布式、高实时的特性,通过RESTful接口提供多用户服务。它基于Java开发,开源且广泛应用于云计算场景,以Java、.NET、PHP、Python等语言提供官方客户端。本文主要讲解在Windows环境下安装及与PHP的对接使用过程。安装与配置
以8.4版本的Elasticsearch为例,确保使用的composer包版本匹配。初次运行可能会遇到SSL和密码认证问题,需要编辑config目录下的elasticsearch.yml文件进行配置。成功配置后,通过访问.0.0.1:验证安装是否成功。安装可视化插件Elasticsearch-Head
该插件需要Node.js支持,可以从GitHub下载源代码并运行,通过访问poser安装babenkoivan/elastic-scout-driver。配置scout驱动为es,并在laravel模型中操作Elasticsearch,模型数据同步功能会在CRUD操作时自动进行。导入现有数据到Elasticsearch
如果已有数据库数据,可通过laravel模型的search方法导入ES,操作方式与常规模型类似。官方扩展的使用
下载并确保composer中elasticsearch/elasticsearch扩展版本与Elasticsearch安装包匹配。在env配置文件中添加ELASTIC_HOST为.0.0.1:,创建EsServiceProvider并注册到config/app.php,即可开始在Laravel中正常使用Elasticsearch服务。