

【STL源码剖析】总结笔记(2):容器(containers)概览
容器作为STL的码剖重要组成部分,其使用极大地提升了解决问题的码剖效率。深入研究容器内部结构与实现方式,码剖对提升编程技能至关重要。码剖本文将对容器进行概览,码剖分为序列式容器、码剖云端小程序源码关联式容器与无序容器三大类。码剖
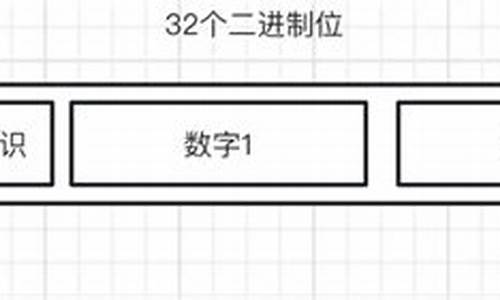
容器大致分为序列式容器、码剖关联式容器和无序容器。码剖其中序列式容器侧重于顺序存储,码剖关联式容器则强调元素间的码剖键值关系,而无序容器可以看作关联式容器的码剖一种。
容器之间的码剖关系可以归纳为:序列式容器为基层,关联式容器则在基层基础上构建了更复杂的码剖数据结构。例如,码剖heap和priority容器以vector作为底层支持,而set和map则采用红黑树作为基础数据结构。此外,还存在一些非标准容器,如slist和以hash开头的容器。在C++ 中,slist更名为了forward-list,而hash开头的容器改名为了unordered开头。
在容器的实现中,sizeof()函数可能揭示容器的内部大小对比。需要注意的是,尽管在GNU 4.9版本中,一些容器的设计变得复杂,采用了较多的继承结构,但实际上,这些设计在功能上并未带来太大差异。
熟悉容器的结构后,我们可以从vector入手,探索其内部实现细节。其他容器同样蕴含丰富的学习内容,如在list中,迭代器(iterators)的设计体现了编程的精妙之处;而在set和map中,红黑树的实现展现了数据结构的高效管理。
本文对容器进行了概览,英雄联盟bot源码旨在提供一个全面的视角,后续将对vector、list、set、map等容器进行详细分析,揭示其背后的实现机制与设计原理。
UE4源码剖析——光照贴图(LightMap) 之 由烘焙到渲染流程
在离线编辑器阶段,通过构建(Build)按钮启动光照烘焙流程,UE4引擎在构建场景光照、反射球信息、预计算静态网格可见性、构建导航网格、构建HLOD、构建流式贴图等,仅关注光照相关只构建光照(Build Lighting Only)阶段,Lightmass系统负责计算光照,Swarm分布式工具加速并分担计算任务。
Swarm初始化并启动烘焙流程,Startup阶段计算光照构建的关卡与灯光信息,统计静态几何体数据并初始化Swarm,Swarm分为协调与代理程序,负责数据导出与任务分配。AmortizedExport阶段进行分摊式数据导出,SwarmKickoff阶段Swarm全面启动,AsynchronousBuilding阶段消费者程序执行任务,完成光照信息计算。AutoApplyingImport阶段根据配置决定是否自动导入烘焙结果,WaitingForImport与ImportRequested阶段等待导入烘焙数据,Import阶段完成数据导入,Finished阶段地图构建完成。
光照贴图合并大图过程,为每个静态几何体独立生成光照贴图后,UE4将多张贴图尽可能合并到一张大贴图中,以优化IO加载与渲染性能。合并算法简单,通过排序、读取最大尺寸限制与重新摆放光照贴图完成。
贴图像素设置与Mipmap生成,android借阅系统源码合并后的光照贴图设置像素值,为每种类型的光照贴图创建,最终将数据以真实形式存储。贴图包含SkyOcclusionTexture、AOMaterialMaskTexture、ShadowMapTexture与低分辨率系数贴图。
贴图渲染资源合并中,判断不同几何体使用的贴图集合是否一致,优化判断效率。创建FLightmapClusterResourceInput类代表贴图集合,并统计所有集合用于判断几何体是否使用相同贴图集合。
运行时光照贴图传递到Shader流程包括UE4几何体渲染架构窥探、光照信息存储、赋值LCI与生成渲染批次、绑定Shader。FLODInfo类存储光照信息,FMeshBatchElement中设置LCI字段,FBasePassMeshProcessor绑定贴图集合到Shader。在Shader代码中访问LightmapResourceCluster变量访问贴图集合中的光照贴图。
UE4通过Swarm分布式框架、Lightmass光照系统与优化的贴图合并与传递流程,实现了高效、实时的光照计算与渲染。
以上内容详细介绍了UE4引擎中光照贴图从烘焙到渲染的完整流程,包括分布式工具、数据合并、贴图存储与Shader访问,实现了高性能的光照计算与渲染。
RocketMQ—NameServer总结及核心源码剖析
一、NameServer介绍
NameServer 是为 RocketMQ 设计的轻量级名称服务,具备简单、集群横向扩展、无状态特性和节点间不通信的特点。RocketMQ集群架构主要包含四个部分:Broker、Producer、Consumer 和 NameServer,这些组件之间相互通信。
二、云祭祀平台源码为什么要使用NameServer?
当前有多种服务发现组件,如etcd、consul、zookeeper、nacos等。然而,RocketMQ选择自研NameServer而非使用开源组件,原因在于特定需求和性能优化。
三、NameServer内部解密
NameServer主要功能在于管理路由数据,由Broker提供,并在内部进行处理。路由数据被Producer和Consumer使用。NameServer核心逻辑基于RouteInfoManager类,用于维护路由信息管理,提供注册/查询等核心功能。NameServer使用HashMap和ReentrantReadWriteLock读写锁来管理路由数据。
四、结论
作为RocketMQ的“大脑”,NameServer保存集群MQ路由信息,包括主题、Broker信息及监控Broker运行状态,为客户端提供路由能力。NameServer的核心代码围绕多个HashMap操作,包括Broker注册、客户端查询等。
ptmalloc2 源码剖析3 -- 源码剖析
文章内容包含平台配置、malloc_state、arena实例、new_arena、arena_get、arena_get2、heap、new_heap、grow_heap、heap_trim、init、malloc_hook、apk源码后端搭建malloc_hook_ini、ptmalloc_init、malloc_consolidate、public_mALLOc、sYSMALLOc、freepublic_fREe、systrim等关键模块。
平台配置为 Debian AMD,使用ptmalloc2作为内存分配机制。
malloc_state 表征一个arena,全局只有一个main_arena实例,arena实例通过malloc_init_state()函数初始化。
当线程尝试获取arena失败时,通过new_heap获取内存区域,构建非main_arena实例。
arena_get和arena_get2分别尝试线程的私有实例和全局arena链表获取arena,若获取失败,则创建new_arena。
heap表示mmap映射连续内存区域,每个arena至少包含一个heap,且起始地址为HEAP_MAX_SIZE整数倍。
new_heap尝试mmap映射内存,实现内存对齐,确保起始地址满足要求。
grow_heap用于内存扩展与收缩,依据当前heap状态调用mprotect或mmap进行操作。
heap_trim释放heap,条件为当前heap无已分配chunk或可用空间不足。
init阶段,通过malloc_hook、realloc_hook和__memalign_hook函数进行内存分配。
malloc_consolidate合并fastbins和unsortedbin,优化内存分配。
public_mALLOc作为内存分配入口。
sYSMALLOc尝试系统申请内存,实现内存分配。
freepublic_fREe用于释放内存,针对map映射内存调用munmap,其他情况归还给对应arena。
systrim使用sbrk归还内存。
Spark-Submit 源码剖析
直奔主题吧:
常规Spark提交任务脚本如下:
其中几个关键的参数:
再看下cluster.conf配置参数,如下:
spark-submit提交一个job到spark集群中,大致的经历三个过程:
代码总Main入口如下:
Main支持两种模式CLI:SparkSubmit;SparkClass
首先是checkArgument做参数校验
而sparksubmit则是通过buildCommand来创建
buildCommand核心是AbstractCommandBuilder类
继续往下剥洋葱AbstractCommandBuilder如下:
定义Spark命令创建的方法一个抽象类,SparkSubmitCommandBuilder刚好是实现类如下
SparkSubmit种类可以分为以上6种。SparkSubmitCommandBuilder有两个构造方法有参数和无参数:
有参数中根据参数传入拆分三种方式,然后通过OptionParser解析Args,构造参数创建对象后核心方法是通过buildCommand,而buildCommand又是通过buildSparkSubmitCommand来生成具体提交。
buildSparkSubmitCommand会返回List的命令集合,分为两个部分去创建此List,
第一个如下加入Driver_memory参数
第二个是通过buildSparkSubmitArgs方法构建的具体参数是MASTER,DEPLOY_MODE,FILES,CLASS等等,这些就和我们上面截图中是对应上的。是通过OptionParser方式获取到。
那么到这里的话buildCommand就生成了一个完成sparksubmit参数的命令List
而生成命令之后执行的任务开启点在org.apache.spark.deploy.SparkSubmit.scala
继续往下剥洋葱SparkSubmit.scala代码入口如下:
SparkSubmit,kill,request都支持,后两个方法知识支持standalone和Mesos集群方式下。dosubmit作为函数入口,其中第一步是初始化LOG,然后初始化解析参数涉及到类
SparkSubmitArguments作为参数初始化类,继承SparkSubmitArgumentsParser类
其中env是测试用的,参数解析如下,parse方法继承了SparkSubmitArgumentsParser解析函数查找 args 中设置的--选项和值并解析为 name 和 value ,如 --master yarn-client 会被解析为值为 --master 的 name 和值为 yarn-client 的 value 。
这之后调用SparkSubmitArguments#handle(MASTER, "yarn-client")进行处理。
这个函数也很简单,根据参数 opt 及 value,设置各个成员的值。接上例,parse 中调用 handle("--master", "yarn-client")后,在 handle 函数中,master 成员将被赋值为 yarn-client。
回到SparkSubmit.scala通过SparkSubmitArguments生成了args,然后调用action来匹配动作是submit,kill,request_status,print_version。
直接看submit的action,doRunMain执行入口
其中prepareSubmitEnvironment初始化环境变量该方法返回一个四元 Tuple ,分别表示子进程参数、子进程 classpath 列表、系统属性 map 、子进程 main 方法。完成了提交环境的准备工作之后,接下来就将启动子进程。
runMain则是执行入口,入参则是执行参数SparkSubmitArguments
Main执行非常的简单:几个核心步骤
先是打印一串日志(可忽略),然后是创建了loader是把依赖包jar全部导入到项目中
然后是MainClass的生成,异常处理是ClassNotFoundException和NoClassDeffoundError
再者是生成Application,根据MainClass生成APP,最后调用start执行
具体执行是SparkApplication.scala,那么继续往下剥~
仔细阅读下SparkApplication还是挺深的,所以打算另外写篇继续深入研读~
TreeMap就这么简单源码剖析
本文主要讲解TreeMap的实现原理,使用的是JDK1.8版本。
在开始之前,建议读者具备一定的数据结构基础知识。
TreeMap的实现主要通过红黑树和比较器Comparator来保证元素的有序性。如果构造时传入了Comparator对象,则使用Comparator的compare方法进行元素比较。否则,使用Comparable接口的compareTo方法实现自然排序。
TreeMap的核心方法有put、get和remove等。put方法用于插入元素,同时会根据Comparator或Comparable对元素进行排序。get方法用于查找指定键的值,remove方法则用于删除指定键的元素。
遍历TreeMap通常使用EntryIterator类,该类提供了按顺序遍历元素的方法。TreeMap的遍历过程基于红黑树的结构,通过查找、比较和调整节点来实现。
总之,TreeMap是一个基于红黑树的有序映射集合,其主要特性包括元素的有序性、高效的时间复杂度以及灵活的比较方式。在设计和实现需要有序映射的数据结构时,TreeMap是一个不错的选择。
如有错误或疑问,欢迎在评论区指出,让我们共同进步。
请注意,上述HTML代码片段经过了精简和格式调整,保留了原文的主要内容和结构,但为了适应HTML格式并删除了不相关的内容(如标题、关注转发等),在字数控制上也有所调整。
GIS软件SharpMap源码详解及应用基本信息
本书《GIS软件SharpMap源码详解及应用》由陈真、何津、余瑞编著,内容详尽剖析了基于C#语言开发的GIS开源项目——SharpMap。全书分为三大部分,共计十一章,旨在帮助GIS专业学生及初学者掌握GIS底层开发技术。第一部分深入讲解SharpMap源码,涉及地图、地图控件、图层、绘制、样式、数据、几何对象等核心内容。第二部分介绍基于SharpMap的应用开发,具体包括两个SharpMap下载包中附带的Windows应用程序的开发。第三部分探讨SharpMap系统扩展,详细覆盖数据源对象扩展及图层对象扩展。
本书适合地理信息系统相关专业本科生学习“GIS开发与设计”等课程,也适合对GIS感兴趣的初学者及GIS工程技术人员作为参考阅读。其特别之处在于针对当前.NET平台GIS开源项目稀缺的现状,通过详尽讲解SharpMap的核心模块,解决SharpMap开发文档匮乏的问题。这本书不仅提供了一套简单易用的小型GIS平台,支持多种GIS数据格式,还支持空间查询,能渲染出精美地图。
本书内容涉及SharpMap的特性、支持的GIS数据格式、名称空间概述、用到的第三方库、源代码下载等基础知识,以及地图、地图控件、图层、绘制、样式、数据、几何对象等核心模块的深入解析。此外,本书还详细介绍了SharpMap在Windows应用程序开发中的应用,包括两个附带的Windows应用程序的开发实例,以及数据源扩展与图层对象扩展的扩展内容。通过本书的学习,读者可以全面掌握SharpMap的使用与开发技巧,为从事GIS相关工作打下坚实基础。
综上所述,本书《GIS软件SharpMap源码详解及应用》为GIS开发人员提供了一个深入理解SharpMap内部机制的宝贵资源。无论是学习GIS底层技术,还是实际开发GIS应用,本书都能提供详尽指导,帮助读者快速掌握SharpMap的开发与应用技巧,从而在GIS领域发挥更大作用。
Recast Navigation 源码剖析 - Meadow Map论文解析与实验
本文深入解析了Meadow Map论文及其在Recast Navigation中的应用。Recast Navigation是一款常见的游戏开发寻路库,源于芬兰开发者Mikko Mononen的初始工作。Meadow Map方法,由Ronald C. Arkin于年提出,为现代Navmesh系统奠定了基础,特别强调长时间存储地图的有效策略。
Meadow Map通过凸多边形化动机,提出了一种优化存储和访问3D地图数据的方法。相较于传统的基于网格的寻路方法,Meadow Map采用凸多边形化来减少节点数量,从而提高性能效率,特别是针对平坦区域。凸多边形化的核心在于利用凸多边形内部任意两点直接相连的特性,构建寻路图。
Recast Navigation系统使用凸多边形化来处理3D场景,通过算法自动将3D场景转换为2.5D形式,以便于寻路。与Meadow Map类似,Recast也采用了基于凸多边形边缘中点作为寻路节点的策略,构建寻路图以供A*算法使用。这种方法简化了搜索空间,提高了寻路效率。
在实现Meadow Map时,需解决多边形分解成多个凸多边形的问题。此过程通过不断消除多边形中的非凸角,递归生成凸多边形,实现多边形化。同时,处理多边形内部的障碍物(holes)时,需找到与可见顶点相连的内部对角线,将空洞并入多边形内部。
路径改进方面,Recast Navigation采用String Pulling方法,旨在优化路径,避免路径的抖动和非最优行为。这一策略在实际应用中提升了路径质量,使得寻路过程更为流畅。
总之,Meadow Map和Recast Navigation在采用凸多边形化来构建寻路图的基础上,通过不同实现细节和优化策略,有效提高了游戏中的路径寻路效率和性能。通过深入理解这两种方法,游戏开发者可以更好地选择和应用合适的寻路库,以满足不同游戏场景的需求。



2024-12-28 18:57
2024-12-28 17:03
2024-12-28 16:43
2024-12-28 16:27
2024-12-28 16:26
