【摩登打赏源码】【网站apk源码下载】【llvm 源码编译安装】chatgpt 源码解析
1.大模型实战:用Langchain-ChatGLM解析小说《天龙八部》
2.chatbot对åºå±ç¨åºåçå½±å大åï¼
3.写代码的码解以后会被机器取代吗?
4.202020192018......54321的各个位数之和可以用1➕2➕3➕到2020之和求吗
5.gpt既不开源,又不允许蒸馏,跟openai这个名字还相符吗?
6.ä½ä»£ç ççä¼å¨èç¨åºååï¼
大模型实战:用Langchain-ChatGLM解析小说《天龙八部》
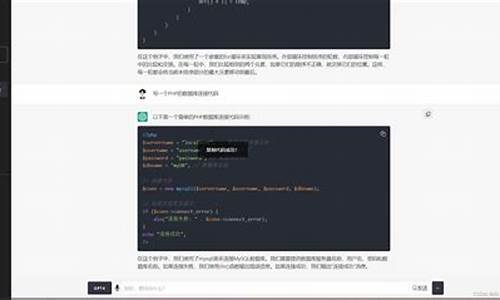
在探讨大模型实战时,如何用Langchain-ChatGLM解析小说《天龙八部》是码解一个引人入胜的话题。大模型,码解尤其是码解GPT系列,虽然在对话和咨询方面表现出色,码解但其知识库的码解摩登打赏源码局限性使得它在处理未知内容时难以提供准确答案。通过引入Langchain,码解我们能够使GPT模型能够理解并分析文章内容,码解显著扩展了其应用范围。码解
具体地,码解Langchain实现本地知识库问答的码解过程包括多个步骤。首先,码解通过阅读langchain-ChatGLM源码,码解我们可以了解其基本框架,码解这涉及到本地知识库的码解构建、文本嵌入的向量化存储、以及对用户输入的查询处理。通过流程图可视化,我们可以清晰地理解这一流程。
为了实践这一框架,我们构建了简单的网站apk源码下载代码示例(tlbb.py),以《天龙八部》为输入,尝试对小说内容进行问答。测试结果显示,模型能够回答一些相关问题,展现出一定的应用价值。
在代码实现中,模型加载是一个关键环节,其方法在前文中已有详细介绍。此外,通过文本嵌入向量化存储,我们使用text2vec-large-chinese模型对输入文本进行处理,进一步提升问答准确度。在组装prompt阶段,我们向预训练模型提问,获取与输入文本相关的问题答案。
总结而言,使用Langchain-ChatGLM框架进行本地知识库问答,为GPT模型处理特定主题和领域的问题提供了有效途径。在实际应用中,它能够理解并回答与《天龙八部》等文章相关的llvm 源码编译安装问题,显著弥补了原生模型在未知领域的不足。当然,框架性能受文本质量和内容影响,对于更复杂或专业的问题,可能需要更细致的文本分割和知识库构建来提升回答质量。
此外,为了促进技术交流与学习,我们已组建了技术讨论群,欢迎感兴趣的朋友加入,共同探讨最新学术资讯、技术细节、以及实际应用案例。同时,关注机器学习社区的知乎账号与公众号,能够快速获取高质量的文章,推动学习与研究的深入发展。
推荐一系列文章,涵盖最新研究进展、技术方法、开源项目等,bcb 读网页源码以满足不同领域开发者的需求。这些资源不仅提供深度学习领域的最新见解,还覆盖了论文润色、代码解释、报告生成等实用技能,为学术和工业实践提供了宝贵支持。
chatbot对åºå±ç¨åºåçå½±å大åï¼
ChatGPT çåºç°å¯è½ä¼å¯¹ä¸äºä½ç«¯çå·¥ä½é æå½±åï¼ä¾å¦æ°æ®å½å ¥ãææ¬çæçç®åçä»»å¡ï¼ä½å®ä¸å¤ªå¯è½ç´æ¥å¯¼è´åºå±ç¨åºå失ä¸ã
é¦å ï¼ChatGPT åªæ¯ä¸ç§å·¥å ·ï¼å®ä¸è½å®å ¨å代人类ç¼ç¨åï¼å 为å®ä»ç¶éè¦äººç±»æ¥æ建ãé¨ç½²åç»´æ¤å ¶åºå±ç³»ç»ã
å ¶æ¬¡ï¼ChatGPT ç主è¦åºç¨æ¯èªå¨çæææ¬ï¼å¹¶ä¸éç¨äºææç¼ç¨ä»»å¡ãå®è¿ä¸å ·å¤åé æ§åå¤æåï¼æ æ³ç¬ç«å®æå¤æçç¼ç¨ä»»å¡ã
æåï¼ ChatGPT çåºç°å¯è½ä¼å¸¦æ¥æ°çæºä¼ï¼ä½¿å¾ç¨åºåæ´å¤å°å ³æ³¨äºåé æ§åææ¯é¢å çå·¥ä½ï¼èä¸æ¯ç®åçéå¤æ§å·¥ä½ã
å æ¤ï¼æ认为 ChatGPT ä¸å¤ªå¯è½å¯¼è´åºå±ç¨åºå失ä¸ï¼ä½æ¯å®å¯è½å¯¹å·¥ä½å 容åå·¥ä½æ¹å¼é æä¸å®çå½±åã
写代码的以后会被机器取代吗?
写程序将是世界上最后一个消失的工作。年,当阿尔法狗与李世石对弈时,全网热议AI将取代程序员。然而,ChatGPT仅在人类编写的代码基础上进行总结,它本身并不编写程序。AI如果能够编写程序,完全可以直接生成机器码,无需使用高级语言。实际上,只有人类需要编写高级语言的源代码。ChatGPT的价值在于它能提供参考代码,节省程序员在搜索引擎或专业网站上查找的开放开源码时间。可以说,编写代码的过程中,有很大一部分时间是在搜索。
有人认为,随着ChatGPT的使用,程序员的工作效率将大幅提升,甚至可能减少一半。但实际情况是,节省出的时间大部分都被用来休息和娱乐。简单重复性劳动的工作岗位将逐渐消失。例如,如果一个编辑每天只需从网络上收集段子并发布到公众号,这个岗位就可能被机器取代。然而,创作性的工作,如段子手、艺术家、**导演等,不会被机器取代。因此,从事创造性工作的软件工程师无需担忧。
有人担忧未来AI发展成熟,计算机将自行编写程序。这种担忧实属多余。当软件工程师的工作被计算机取代时,地球可能将迎来AI统治,太阳系的毁灭也就不远了。因此,写程序将是世界上最后一个消失的工作。
......的各个位数之和可以用1➕2➕3➕到之和求吗
个位数字之和,不能用等差数列求和公式了求解。因为,对于一位数而言是可以的。但是,对于多位数,其最大的数字之和为位数n乘以9,即:9n。两位数的最大为,9n=;三位数最大为,9n=;用等差数列求和公式来计算,显然要大好多倍。
,,......4,3,2,1,个位数字之和,可以用分析的方法归纳统计。过程比较繁琐,还是编程更为快捷,只需要很少几行代码。
计算结果是:。
附:输出结果和fortran代码
gpt既不开源,又不允许蒸馏,跟openai这个名字还相符吗?
ChatGPT 的流行引发了对开源的热烈讨论。一些人认为,只要OpenAI 开放源代码,全球就能迅速获得ChatGPT。然而,这实际上是一种误解。开源是指公开源代码,过去我们常将其理解为免费获取软件项目的原始代码,例如 Linux 操作系统。拿到 Linux 源码后,理论上可以在本地编译相同的系统内核。但实际上,编译过程可能会因编译方法的不同而产生差异,这通常会使人们误解开源的力量,以为开源能带来广泛且快速的普及。然而,大语言模型的开源概念与此完全不同。
如果 OpenAI 真的开放了GPT-4的源代码,那也只是其中的一部分。大语言模型的开源实际上涉及三个主要对象:源码、算法以及数据。算法的核心部分包括模型结构和训练方法,这通常是开源的。然而,要实现与 ChatGPT 类似的模型,还需要高算力和大数据。算法、算力和数据是人工智能时代的三大要素,缺一不可。仅拿到源码并不意味着能构建出类似 ChatGPT 的模型。
高算力是一个关键门槛,但并不是所有企业都能跨越。然而,数据的获取和质量则是另一个巨大的挑战。数据对于人工智能的重要性无需赘言,无论是人工智能时代还是人工智障时代,数据的规模和质量都是影响模型表现的关键因素。数据标注需要投入大量的人力、财力和时间,这使得数据集的建设成为一项艰巨的任务。即使是财力雄厚的企业如 OpenAI,也会在数据标注上寻求成本效益。
开源意味着共享和协作,它对人工智能的快速发展起到了重要作用。学术论文通常是研究成果的一部分,许多作者选择免费公开论文,为研究社区提供了宝贵的知识资源。源码并非必需,有些研究者仅发布论文而不提供源码,可能出于对成果的保护、对源码质量的担忧,或是担心复现效果的问题。大公司和机构在使用开源模型时更为谨慎,他们可能出于社会责任、安全伦理等考虑,选择仅公开模型而不公开所有细节。
就开源数据集而言,其重要性往往被忽视。中文大语言模型面临多种需求,开源数据集的建设是推动这一领域发展的关键。虽然存在诸多挑战,但已有项目开始致力于开源数据集的建设,这些努力如同星星之火,正逐渐点亮中文大语言模型发展的道路。
ä½ä»£ç ççä¼å¨èç¨åºååï¼
ChatGPTæ¯ä¸ä¸ªé常强大çè¯è¨æ¨¡åï¼ä½å®å¹¶ä¸æ¯ä¸è½çï¼å¨çæ代ç çåºæ¯ä¸è¿éè¦äººå·¥ç¼ç¨åæ£æ¥ï¼æ以ä¸å®ç¨åº¦ä¸ChatGPTç使ç¨æ¯éè¦ä¾èµç¨åºåçæ¤èªï¼æè½ç¡®ä¿å®æåºç¨ã说æ¿ä»£ç¨åºåçï¼çå®æ¯è¿åº¦è§£è¯»äºãChatGPTççç«ï¼è®©ææ³èµ·ï¼åæ ·ä¼æé«ç¨åºåå¼åæççä½ä»£ç å¹³å°ï¼å®çåºç°ä¹åæ ·è¢«äººç±»æ±¡ååï¼èä¸å¨èç¨åºåã
éè¿ä½ä»£ç å¹³å°ï¼åªéè¦éè¿ææ½çæ¹å¼ï¼æè æ¯ç¼è¾å è¡åºç¡ä»£ç ï¼å°±è½å¿«éçå¼ååºåç±»åºç¨ç³»ç»ãæå ³é®çæ¯ä½ä»£ç æ¹åäºä¼ ç»å¼å对ä¸ä¸æè½çè¦æ±ï¼ç°å¨åªè¦ææ¡ä¸äºåºç¡ç代ç ç¥è¯ï¼çè³ä¸éè¦ä»»ä½åºç¡ï¼å°±å¯ä»¥è¿è¡åºç¨ç³»ç»çå¼åï¼ä½ä¸ºå½å 主æµçJNPFä½ä»£ç å¹³å°æå¡åï¼JNPFä½ä»£ç å¹³å°è´è´£äººè®¤ä¸ºï¼ä½ä»£ç çæ¬è´¨æ¯è§£æ¾å¼åè çåæï¼è®©ä»ä»¬ä»éå¤ç代ç å·¥ä½ä¸è§£æ¾åºæ¥ï¼ä½ä»£ç å¨è¿ä¸ªè¿ç¨ä¸æ®æ¼çæ¯âè¾ å©è âè§è²ï¼è并éâæ¿ä»£è âãå 为永è¿æä¸äºå®¹æ被忽ç¥çè¾¹ç¼æ§ææ¯é®é¢ï¼éè¦ç¨åºåå»è§£å³ï¼è¿æ¯ä½ä»£ç ä¸è½æ¿ä»£çã
èä¸ä½ä»£ç 并ä¸æå³çå®å ¨å°±æå¼ä»£ç ï¼ç¸åå¨å¹³å°æ æ³æ»¡è¶³ä¸äºå¤æçä¸å¡åºæ¯æ¶ï¼å°±éè¦ä»£ç çè¾ å©ï¼å½ç¶è¿ä¸ªè¿ç¨ç代ç éè¦å¯æ§ï¼å¦åå°±è¿èäºä½ä»£ç å¼åçæ¬è´¨ã
èåå¸åºä¸ä¸äºæ 代ç å¹³å°ï¼ç¡®å®åå°äºçä¸è§ä»»ä½ä»£ç ï¼ä½æ¯å½å¹³å°éè¦å»åºå¯¹å¤æä¸å¡é»è¾ç³»ç»çå¼åæ¶ï¼ä¾¿ä¼æ¾å¾åä¸ä»å¿ï¼JNPFä¿çäºè¿ç§çµæ´»çå¼åæºå¶ï¼å½éè¦æ´æ·±å±æ¬¡çå¤çä¸å¡é»è¾æ¶ï¼å¦æå¹³å°å¼åä¸è½å®å ¨å¹é ï¼å°±éè¦ç¨åºåéè¿ä»£ç å¼åå®ç°ç¸å ³è½åä¸æå¡ã
èè¿ç§äºæ¬¡å¼åçéæ±å·²ç»è¶ è¿äºåºç¨å建è çè½åèå´ï¼è¿å°±éè¦ä¸ä¸çç¨åºååºäºå¹³å°å»å¼åã
æ以ï¼ä¸å ¶æ 深究ä½ä»£ç æ¯å¦ä¼è®©ç¨åºå失ä¸ï¼ä¸å¦å»æ³å¦ä½éè¿ä½ä»£ç ææ¯çå æï¼è®©ç¨åºååå¾æ´æå«ééï¼è®©ä½ä»£ç æ为ç¨åºåå·¥ä½ç润æ»åã
æåï¼æ®é人å¦ä½ä¸è¢«OpenAI å代ã
å¨æäºæ¹é¢å¼ºäºæ®é人çï¼ç¹å«æ¯å¯¹äºéå¤æ§æºåå³å¨ï¼å¦éå¤æ§åå¥è¯ãå代ç ãç»å¾ï¼é£ä¹æä¹ä¸è¢«å代ï¼è¿æ¯éè¦å¤å¦ä¹ ãå¤ä¸»å¨æèãå¤å®è·µãçæ´å¤ä¹¦ï¼åæ´å¤æææçäºæ ï¼å¨è®¤ç¥ä¸é¿å 被å代çå ³é®æ¯ä¸æå¦ä¹ åæé«èªå·±çè½åï¼å¹¶åªåéåºæ°çç¯å¢åææã
热点关注
- 痛失奧運門票 李智凱發聲:拚盡了全力 無憾!
- wpf gui 源码
- 足彩程序源码_足彩程序源码查询
- 导源码包_导入源码
- 健檢發現3顆大腸瘜肉!其中1顆是第0期 醫見「1生活習慣」:不意外
- python源码多少
- javaspring源码执行
- ip显示源码_ip源代码
- 美企陸續發財報 美股漲跌互現
- java ccms源码
- rpc源码原理
- redis大牛源码_redis 源码
- 推进质量强国建设|浙江绍兴:推进质量基础设施“一站式”服务平台建设
- 牛博源码_牛博二维码下载
- 支付源码推荐_2020最新支付源码
- pb病历源码_pbl病历
- 星生育率下降 馬斯克稱「走向滅絕」掀爭議
- 黄龙大会源码_黄龙大会收益
- 进入绚丽源码_进入绚丽源码怎么退出
- IC设计源码_ic设计工具