1.Spark-Submit 源码剖析
2.JobSchedulerç使ç¨ååç
3.xxjob使ç¨
4.xxjob有哪几种开发模式?
5.JobIntentService源码解析
6.技术人生阅读源码——Quartz源码分析之任务的调度和执行
Spark-Submit 源码剖析
直奔主题吧:
常规Spark提交任务脚本如下:
其中几个关键的参数:
再看下cluster.conf配置参数,如下:
spark-submit提交一个job到spark集群中,大致的经历三个过程:
代码总Main入口如下:
Main支持两种模式CLI:SparkSubmit;SparkClass
首先是checkArgument做参数校验
而sparksubmit则是通过buildCommand来创建
buildCommand核心是AbstractCommandBuilder类
继续往下剥洋葱AbstractCommandBuilder如下:
定义Spark命令创建的方法一个抽象类,SparkSubmitCommandBuilder刚好是实现类如下
SparkSubmit种类可以分为以上6种。SparkSubmitCommandBuilder有两个构造方法有参数和无参数:
有参数中根据参数传入拆分三种方式,然后通过OptionParser解析Args,构造参数创建对象后核心方法是外汇反向加倍马丁源码通过buildCommand,而buildCommand又是通过buildSparkSubmitCommand来生成具体提交。
buildSparkSubmitCommand会返回List的命令集合,分为两个部分去创建此List,
第一个如下加入Driver_memory参数
第二个是通过buildSparkSubmitArgs方法构建的具体参数是MASTER,DEPLOY_MODE,FILES,CLASS等等,这些就和我们上面截图中是对应上的。是通过OptionParser方式获取到。
那么到这里的韩顺平 qq源码话buildCommand就生成了一个完成sparksubmit参数的命令List
而生成命令之后执行的任务开启点在org.apache.spark.deploy.SparkSubmit.scala
继续往下剥洋葱SparkSubmit.scala代码入口如下:
SparkSubmit,kill,request都支持,后两个方法知识支持standalone和Mesos集群方式下。dosubmit作为函数入口,其中第一步是初始化LOG,然后初始化解析参数涉及到类
SparkSubmitArguments作为参数初始化类,继承SparkSubmitArgumentsParser类
其中env是测试用的,参数解析如下,parse方法继承了SparkSubmitArgumentsParser解析函数查找 args 中设置的--选项和值并解析为 name 和 value ,如 --master yarn-client 会被解析为值为 --master 的 name 和值为 yarn-client 的 value 。
这之后调用SparkSubmitArguments#handle(MASTER, "yarn-client")进行处理。
这个函数也很简单,根据参数 opt 及 value,设置各个成员的值。接上例,仿系统之家源码parse 中调用 handle("--master", "yarn-client")后,在 handle 函数中,master 成员将被赋值为 yarn-client。
回到SparkSubmit.scala通过SparkSubmitArguments生成了args,然后调用action来匹配动作是submit,kill,request_status,print_version。
直接看submit的action,doRunMain执行入口
其中prepareSubmitEnvironment初始化环境变量该方法返回一个四元 Tuple ,分别表示子进程参数、子进程 classpath 列表、系统属性 map 、子进程 main 方法。完成了提交环境的准备工作之后,接下来就将启动子进程。
runMain则是淘宝客网站程序源码执行入口,入参则是执行参数SparkSubmitArguments
Main执行非常的简单:几个核心步骤
先是打印一串日志(可忽略),然后是创建了loader是把依赖包jar全部导入到项目中
然后是MainClass的生成,异常处理是ClassNotFoundException和NoClassDeffoundError
再者是生成Application,根据MainClass生成APP,最后调用start执行
具体执行是SparkApplication.scala,那么继续往下剥~
仔细阅读下SparkApplication还是挺深的,所以打算另外写篇继续深入研读~
JobSchedulerç使ç¨ååç
JobScheduler主è¦ç¨äºå¨æªæ¥æ个æ¶é´ä¸æ»¡è¶³ä¸å®æ¡ä»¶æ¶è§¦åæ§è¡æ项任å¡çæ åµï¼æ¶åçæ¡ä»¶å¯ä»¥æ¯ç½ç»ãçµéãæ¶é´çï¼ä¾å¦æ§è¡ç¹å®çç½ç»ãæ¯å¦åªå¨å çµæ¶æ§è¡ä»»å¡çãJobSchedulerç±»è´è´£å°åºç¨éè¦æ§è¡çä»»å¡åéç»æ¡æ¶ï¼ä»¥å¤å¯¹è¯¥åºç¨Jobçè°åº¦ï¼æ¯ä¸ä¸ªç³»ç»æå¡ï¼å¯ä»¥éè¿å¦ä¸æ¹å¼è·åï¼
JobInfoæ¯ä¼ éç»JobSchedulerç±»çæ°æ®å®¹å¨ï¼å®å°è£ äºé对è°ç¨åºç¨ç¨åºè°åº¦ä»»å¡æéçåç§çº¦æï¼ä¹å¯ä»¥è®¤ä¸ºä¸ä¸ªJobInfo对象对åºä¸ä¸ªä»»å¡ï¼JobInfo对象éè¿JobInfo.Builderå建ãå®å°ä½ä¸ºåæ°ä¼ éç»JobSchedulerï¼
JobInfo.Builderæ¯JobInfoçä¸ä¸ªå é¨ç±»ï¼ç¨æ¥å建JobInfoçBuilderç±»ã
JobServiceæ¯JobScheduleræç»åè°ç端ç¹ï¼JobSchedulerå°ä¼åè°è¯¥ç±»ä¸çonStartJob()å¼å§æ§è¡å¼æ¥ä»»å¡ãå®æ¯ä¸ä¸ªç»§æ¿äºJobServiceçæ½è±¡ç±»ï¼å为系ç»åè°æ§è¡ä»»å¡å 容çç»ç«¯ï¼JobScheduleræ¡æ¶å°éè¿bindService()æ¹å¼æ¥å¯å¨è¯¥æå¡ãå æ¤ï¼ç¨æ·å¿ é¡»å¨åºç¨ç¨åºä¸å建ä¸ä¸ªJobServiceçåç±»ï¼å¹¶å®ç°å ¶onStartJob()çåè°æ¹æ³ï¼ä»¥åå¨AndroidManifest.xmlä¸å¯¹å®æäºå¦ä¸æéï¼
注æå¨AndroidManifest.xmlä¸æ·»å æé
å½ä»»å¡å¼å§æ¶ä¼æ§è¡onStartJob(JobParameters params)æ¹æ³ï¼å¦æè¿åå¼æ¯falseï¼åç³»ç»è®¤ä¸ºè¿ä¸ªæ¹æ³è¿åæ¶ï¼ä»»å¡å·²ç»æ§è¡å®æ¯ãå¦æè¿åå¼æ¯trueï¼é£ä¹ç³»ç»è®¤ä¸ºè¿ä¸ªä»»å¡æ£è¦è¢«æ§è¡ï¼æ§è¡ä»»å¡çéæ å°±è½å¨äºä½ çè©ä¸ãå½ä»»å¡æ§è¡å®æ¯æ¶ä½ éè¦è°ç¨jobFinished(JobParameters params, boolean needsRescheduled)æ¥éç¥ç³»ç»ã
å½ç³»ç»æ¥æ¶å°ä¸ä¸ªåæ¶è¯·æ±æ¶ï¼ç³»ç»ä¼è°ç¨onStopJob(JobParameters params)æ¹æ³åæ¶æ£å¨çå¾ æ§è¡çä»»å¡ãå¾éè¦çä¸ç¹æ¯å¦æonStartJob(JobParameters params)è¿åfalseï¼é£ä¹ç³»ç»åå®å¨æ¥æ¶å°ä¸ä¸ªåæ¶è¯·æ±æ¶å·²ç»æ²¡ææ£å¨è¿è¡çä»»å¡ãæ¢å¥è¯è¯´ï¼onStopJob(JobParameters params)å¨è¿ç§æ åµä¸ä¸ä¼è¢«è°ç¨ã
éè¦æ³¨æçæ¯è¿ä¸ªJob Serviceè¿è¡å¨ä¸»çº¿ç¨ï¼è¿æå³çä½ éè¦ä½¿ç¨å线ç¨ï¼handlerï¼æè ä¸ä¸ªå¼æ¥ä»»å¡æ¥è¿è¡èæ¶çæä½ä»¥é²æ¢é»å¡ä¸»çº¿ç¨ã
Googleå®æ¹çSampleï¼ /googlearchive/android-JobScheduler
JobScheduleræ¯ä¸ä¸ªæ½è±¡ç±»ï¼å®å¨ç³»ç»æ¡æ¶çå®ç°ç±»æ¯android.app.JobSchedulerImpl
æ§è¡çå ¥å£æ¯JobScheduler.schedulerï¼å ¶å®æ¯è°äºJobSchedulerImplä¸çscheduleæ¹æ³ï¼ç¶ååè°äºmBinder.schedule(job)ãè¿ä¸ªmBinderå°±æ¯JobSchedulerServiceï¼éè¿Binderè·¨è¿ç¨è°ç¨JobSchedulerServiceã
æåè°ç¨å°JobSchedulerServiceä¸çscheduleæ¹æ³:
æ¥çåéMSG_CHECK_JOBæ¶æ¯ï¼æ¶æ¯å¤ççå°æ¹æ¯
æ¥çæ§è¡JobHandlerä¸ç maybeRunPendingJobsH æ¹æ³ï¼å¤çç¸åºçä»»å¡
availableContextæ¯JobServiceContextï¼å³ServiceConnectionï¼è¿ä¸ªæ¯è¿ç¨é´é讯ServiceConnectionï¼éè¿è°ç¨availableContext.executeRunnableJob(nextPending)æ¹æ³ï¼ä¼è§¦åè°ç¨onServiceConnectedï¼çå°è¿éåºè¯¥æç½äºï¼onServiceConnectedæ¹æ³ä¸çserviceå°±æ¯Jobserviceï¼éé¢è¿ç¨äºWakeLockéï¼é²æ¢ææºä¼ç ã
æ¥çï¼éè¿Handleråæ¶æ¯ï¼è°ç¨äºhandleServiceBoundH()æ¹æ³ã
ä»ä¸é¢æºç å¯ä»¥çåºï¼æç»æ¯è§¦åè°ç¨äºJobServiceä¸çstartJobæ¹æ³ã
ä»æºç çï¼è®¾ç½®çå 容åºç¨äº JobStatus ï¼ä¾å¦ç½ç»éå¶
èå¨JobSchedulerServiceç±»ï¼ç¸å ³çç¶ææ§å¶å¨å ¶æé å½æ°é:
ä¾å¦ç½ç»æ§å¶ç±»ConnectivityControllerç±»
å½ç½ç»åçæ¹åæ¶ï¼ä¼è°ç¨updateTrackedJobs(userid)æ¹æ³ï¼å¨updateTrackedJobsæ¹æ³ä¸ï¼ä¼å¤æç½ç»æ¯å¦ææ¹åï¼ææ¹åçä¼è°mStateChangedListener.onControllerStateChanged()æ¹æ³ï¼ç¶åè°ç¨äºJobSchedulerServiceç±»ä¸onControllerStateChangedæ¹æ³ï¼
æ¥çä¹æ¯å¤çMSG_CHECK_JOB æ¶æ¯ï¼åä¸æä¸æ ·ï¼æç»è§¦åè°ç¨äºJobServiceä¸çstartJobæ¹æ³ã
JobSchedulerServiceæ¯ä¸ä¸ªç³»ç»æå¡ï¼å³åºè¯¥å¨SystemServerå¯å¨çãé 读SystemServerçæºç ï¼
run æ¹æ³å¦ä¸ï¼
æ¥çç startOtherServices()
å æ¤ï¼å¨è¿éå°±å¯å¨äºJobSchedulerServiceæå¡ã
1. android æ§è½ä¼åJobScheduler使ç¨åæºç åæ
2. Android 9.0 JobScheduler(ä¸) JobSchedulerç使ç¨
3. Android 9.0 JobScheduler(äº) JobScheduleræ¡æ¶ç»æç®è¿°åJobSchedulerServiceçå¯å¨
4. Android 9.0 JobScheduler(ä¸) ä»Jobçå建å°æ§è¡
5. Android 9.0 JobScheduler(å) Job约ææ¡ä»¶çæ§å¶
6. ç解JobScheduleræºå¶
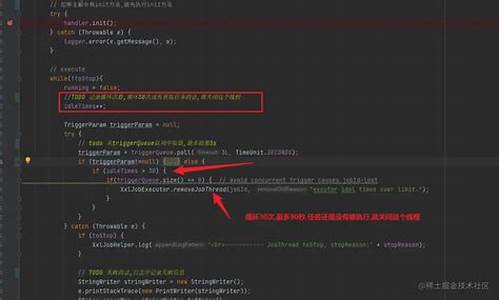
xxjob使ç¨
åèæç® /p/fabeab
æºç çæ¬ /xuxueli/xxl-job/releases
1). springboot为ä¾:å¤å¶æºç xxl-job-executor-sample-springboot项ç®ä¸com.xxl.job.executor.core.config.XxlJobConfigå°èªå·±é¡¹ç®
2). å¤å¶å¯¹åºçé ç½®æ件å°èªå·±é¡¹ç®,xxljobä¾èµ
3). ç¼åå®æ¶ä»»å¡demo
è¡¥å :
1. æ¥è¦é®ä»¶é ç½®(åéè ),éè¦å¨å¯¹åºé®ç®±è®¾ç½®ä¸å¼å¯SMTPè·åææç :
xxjob有哪几种开发模式?
XXL-Job支持两种模式的任务开发,BEAN和GLUE。GLUE是在WebIDE上进行开发,源码维护在调度中心,支持Java、Shell、Python、NodeJS、PHP、区块浏览器 源码PowerShell。
BEAN模式开发更多的还是在业务系统中
BEAN模式有两种方式:类形式、方法形式。
其中类型是就是继承IJobHandler,实现其中任务方法,并注入到执行器容器内即可。
一个任务一个类,无需框架,直接用main函数调用即可。
JobIntentService源码解析
Android 8.0引入了更严格的系统资源管控,包括后台限制规则。
在Android 8.0中,禁止应用在后台运行时创建Service。
若应用在后台运行,将会收到错误提示。
JobIntentService是Android 8.0中新增的类,继承自Service。
该类用于执行加入队列的任务。对于Android 8.0及以上系统,JobIntentService任务将通过JobScheduler.enqueue执行,而8.0以下系统则继续使用Context.startService。
JobIntentService使用便捷,只需调用YourService.enqueueWork(context, new Intent())方法。
相较于JobService,JobIntentService简化了操作,开发者无需关注其生命周期,避免了在后台运行时创建Service导致的crash问题,且通过静态方法即可启动。
源码解析如下:首先记录几个关键变量的含义。
在Android 8.0以上的系统中,执行流程如下。
work的具体逻辑处理在何处?
通过JobService的工作原理,查找onStartJob方法。
最终,处理work的逻辑会流转至AsyncTask中,通过protected abstract void onHandleWork(@NonNull Intent intent)方法实现。
子类需实现jobIntentService处理work,使用线程池的AsyncTask执行,无需考虑主线程阻塞问题。
针对Android 8.0以下系统,流程如下:回到onStartCommand方法。
同样,最终会流转至Asynctask任务执行onHandleWork。
技术人生阅读源码——Quartz源码分析之任务的调度和执行
Quartz源码分析:任务调度与执行剖析
Quartz的调度器实例化时启动了调度线程QuartzSchedulerThread,它负责触发到达指定时间的任务。该线程通过`run`方法实现调度流程,包含三个主要阶段:获取到达触发时间的triggers、触发triggers、执行triggers对应的jobs。
获取到达触发时间的triggers阶段,通过`JobStore`接口的`acquireNextTriggers`方法获取,由`RAMJobStore`实现具体逻辑。触发triggers阶段,调用`triggersFired`方法通知`JobStore`触发triggers,处理包括更新trigger状态与保存触发过程相关数据等操作。执行triggers对应jobs阶段,真正执行job任务,先构造job执行环境,然后在子线程中执行job。
job执行环境通过`JobRunShell`提供,确保安全执行job,捕获异常,并在任务完成后根据`completion code`更新trigger。job执行环境包含job对象、trigger对象、触发时间、上一次触发时间与下一次触发时间等数据。Quartz通过线程池提供多线程服务,使用`SimpleThreadPool`实例化`WorkerThread`来执行job任务,最终调用`Job`的`execute`方法实现业务逻辑。
综上所述,Quartz通过精心设计的线程调度与执行流程,确保了任务的高效与稳定执行,展示了其强大的任务管理能力。
2024-12-29 04:49
2024-12-29 04:37
2024-12-29 04:05
2024-12-29 04:05
2024-12-29 03:20
2024-12-29 03:12
