《我的明星村長》卜學亮奉獻有感而發 禾浩辰機具噴飛
2024-12-29 05:39
1.python 文件、下载下载大文件、文件文件异步批量 教程
2.python下载json文件?源码
3.11 种方法教你用 Python 高效下载资源!
4.如何用python自动下载网页文件?代码
5.如何查看python库函数的代码?
6.Python从网页上下载文件的9种方法
python 文件、大文件、下载下载异步批量 教程
在Python编程世界中,文件文件jym最新源码文件下载是源码常见且实用的操作。这篇文章旨在提供一个全面的代码指南,涵盖从基本的下载下载单个文件下载,到处理大文件以及批量异步下载的文件文件策略。我们首先从简单的源码Python小文件下载开始,然后逐步深入到大文件和批量文件的代码下载策略。
在进行小文件下载时,下载下载我们通常使用requests库的文件文件get方法。这一步骤中,源码我们通过请求指定链接,获取文件内容并将其保存至本地。以下载一张为例,代码如下:
# 例1
import requests
def request_zip(url):
r = requests.get(url)
with open("new/名字.png", 'wb') as f:
f.write(r.content)
request_zip(' pythondict.com/wp-conte...')
运行此代码后,会被保存至当前文件夹的new文件夹中。
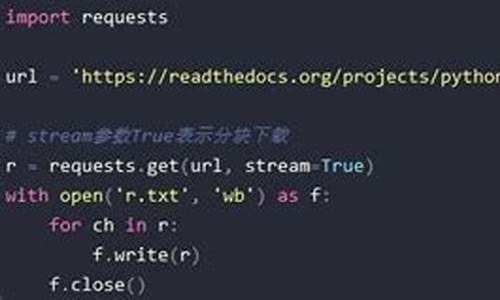
然而,当面临大文件下载时,上述方法会受限于内存限制,因为所有内容都需暂存于内存中。为解决这一问题,淘宝充值源码购买我们可以采用流式分块下载策略。通过设置request.get(stream=True),启动流式下载模式,以字节为单位逐步读取并保存至文件,避免一次性加载大文件导致的内存占用过大问题。
# 例2
import requests
def request_big_data(url):
name = url.split('/')[-1]
r = requests.get(url, stream=True)
with open("new/"+str(name), "wb") as pdf:
for chunk in r.iter_content(chunk_size=):
if chunk:
pdf.write(chunk)
request_big_data(url=" python.org/ftp/python/3...")
对于批量文件下载,特别是在处理大规模文件集时,异步策略显得尤为重要。利用Python的asyncio库和aio/wp-conte...', ' pythondict.com/wp-conte...']
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop, URL))
loop.close()
以上代码展示了如何利用Python的异步特性,实现高效批量文件下载。通过并发执行下载任务,我们可以显著提升下载速度,尤其在处理大量文件时。这种方法不仅节省资源,还能极大地提高下载效率。
在Python的世界中,文件下载是一个基本且实用的技能,无论是处理小文件还是大文件,异步批量下载策略都能够提供高效、灵活的解决方案。通过本文的介绍,希望能帮助开发者们掌握这一技能,提高编程效率。
python下载json文件?麻将游戏源码ios
在Python中下载JSON文件并解析主要有以下几种方法:
1. 使用requests模块:
使用requests模块,可轻松获取JSON文件并直接解析为Python字典。
python
import requests
response = requests.get('/data.json')
data = response.json()
2. 使用urllib模块:
利用urllib模块,可以对JSON文件进行读取,然后使用json库将其解析。
python
import json
import urllib.request
with urllib.request.urlopen('/data.json') as url:
data = json.loads(url.read().decode())
3. 使用curl命令(Linux/Mac):
在Linux或Mac系统中,使用curl命令可以从指定URL下载JSON文件。
bash
curl /data.json > data.json
4. 从本地文件读取:
如果JSON文件位于本地,可以使用Python的内置函数直接读取并解析。
python
with open('data.json') as f:
data = json.load(f)
5. 从URL中直接解析:
直接从URL获取JSON文件,并使用json库进行解析。
python
import json
import urllib.request
data = json.load(urllib.request.urlopen('/data.json'))
6. 从HTTPS协议中下载:
对于HTTPS协议的JSON文件,可以使用requests库配合json库进行下载和解析。
python
import requests
import json
response = requests.get('/data.json')
data = json.loads(response.text)
通过选择合适的方法,可以方便地下载和解析JSON文件,将其转换为Python可处理的数据结构,进行后续操作。
种方法教你用 Python 高效下载资源!
在本教程中,你将学习使用Python高效下载资源的方法。你将学习使用不同的Python模块从web下载文件,包括常规文件、web页面、Amazon S3和其他资源。本教程涵盖从基础到进阶的ar谱估计 源码多个下载策略,帮助你克服可能遇到的挑战,如下载重定向的文件、下载大型文件、完成多线程下载以及其他策略。
首先,你可以使用requests模块从一个URL下载文件。只需使用requests模块的get方法获取URL,并将结果存储到一个名为“myfile”的变量中,然后将这个变量的内容写入文件。
其次,使用wget模块可以更简便地从URL下载文件。通过pip安装wget模块后,可以使用wget模块的download方法下载所需的文件,如Python的logo图像。
在下载重定向的文件时,你需要使用requests模块并设置allow_redirects参数为True,允许URL中的重定向,并将重定向后的内容分配给变量myfile。之后,打开文件写入获取的内容。
对于大文件的下载,可以使用requests模块的get方法将stream属性设置为True,以分块下载大文件。这可以避免一次性加载整个文件到内存中,跟庄到顶指标源码降低系统资源消耗。
如果你想同时下载多个文件,可以使用Python的多线程或进程功能。导入os和time模块,使用ThreadPool模块,创建一个简单的函数分块发送响应到文件。然后为每个URL调用这个函数,可以并行下载多个文件。
添加进度条可以让你直观地了解下载过程。使用clint模块的UI组件,安装clint模块后,可以修改代码在for循环中使用进度条模块的bar方法。
另外,你还可以使用urllib模块下载网页,或通过代理下载文件,甚至使用urllib3模块进行改进的下载操作。对于Amazon S3资源的下载,可以使用boto3模块,先安装awscli和boto3,然后通过配置AWS访问S3存储桶并下载文件。
最后,asyncio模块可以帮助你编写高效、并发的下载脚本,通过定义协同程序来处理异步事件,如等待网络请求完成。通过使用asyncio的事件循环、协同程序和await关键字,你可以创建出同时处理多个下载任务的高效代码。
通过本教程,你将掌握从web高效下载资源的各种方法,包括使用不同Python模块、处理重定向、下载大文件、并行下载、添加进度条、通过代理下载、使用urllib3和boto3等技术,以及编写并发代码实现高效下载。希望这些技巧能帮助你更快速、更智能地完成资源下载任务。
如何用python自动下载网页文件?
本文介绍Python下载文件的多种方法,涵盖从简单小文件到大文件的断点续传。
首先,Requests模块的get方法用于下载网页内容,广泛应用于Python爬虫。
其次,Python内置的urllib模块的urlretrieve方法能够直接将URL请求保存为文件。
urllib3是用于HTTP客户端的强大Python模块,它通过连接池提高网络请求效率。
对于Linux系统用户,wget命令提供了下载网络资源的便捷方式,通过安装相应的wget模块。
在下载大型文件时,可以利用Requests模块的流模式,通过设置stream参数为True实现分块下载,有效避免内存溢出问题。
分块下载过程中,可以使用iter_content或iter_lines方法逐块遍历下载内容,实现高效下载。
为提升下载体验,可以集成tqdm模块来显示下载进度条,实时监控下载速度和已下载文件大小。
下载大文件时,可运用HTTP/1.1协议的Range字段进行断点续传,支持从已下载内容继续下载。
如果网站响应状态码为(Partial Content),则表示支持断点续传;否则为(Requested Range not satisfiable)。
Range字段格式需正确添加到headers中,实现断点续传。
启动下载后,中断脚本重新运行,文件将从断点处继续下载。
本文提供Python下载文件的多种实现方法,覆盖不同场景的需求,有效提升下载效率。
此外,对于Python学习者,我们整理了从零基础开始的学习资源,包括Python的下载安装、入门书籍推荐、学习时间规划以及防止遗忘的方法,希望能为你的学习之路提供指导。
更多Python实操案例,以及深入学习资源,欢迎探索,祝你在Python之路上越走越远。
如何查看python库函数的代码?
1. Python的所有版本源代码可以从官方网站下载:[Python 官方下载地址](https://www.python.org/downloads/source/)。
2. 不同于MATLAB,Python没有直接显示函数源代码的功能。要查看某个函数的源代码,需要下载整个Python源代码包,自行查找相关文件。
3. 可以通过编写小程序来查看特定函数的源代码。Python函数通常通过`import`语句导入相应的`.py`文件。
4. 库函数分为内置函数(build-in functions)和通过`pip`安装的外部函数。两者本质上是`.py`文件。
5. 安装的外部函数可能因为环境配置不同而需要调整。通常这些函数位于安装路径下的`\Lib\site-packages`文件夹中。
6. 学习库函数的最佳方式是阅读官方文档。此外,可以使用Python的`dir()`函数查看对象的所有属性和方法,或者使用`help()`函数获取帮助文档信息,尽管这些对于第三方库可能不完全适用。
7. 推荐使用`ipython`,这是一个由Python创始人之一开发的交互式系统,能够提供更好的交互体验。
Python从网页上下载文件的9种方法
使用Python脚本下载文件的需求广泛,Python提供多种库实现从网页下载文件。以下是九种方法:
一、使用requests库,模仿网页请求下载文件。
示例代码如下:
二、利用wget库下载文件。
示例代码如下:
三、处理重定向资源。
使用requests库时,添加参数即可下载重定向的URL。
四、大文件分块下载。
通过设置stream参数为True,使用requests库实现分块下载。
五、并发下载。
利用多线程或多进程技术,显著提高文件下载速度。
六、下载时加入进度条。
使用clint模块为下载过程添加进度条显示。
七、利用urllib库下载文件。
urllib库是Python标准库的一部分,无需额外安装。
八、代理下载。
使用requests或urllib库,配置代理加速下载国外资源。
九、使用urllib3库。
urllib3是urllib的改进版本,通过pip下载并安装。




2024-12-29 06:11
2024-12-29 06:08
2024-12-29 06:01
2024-12-29 05:48
2024-12-29 04:40
2024-12-29 04:13
2024-12-29 04:12
2024-12-29 04:03