【图书登记系统源码】【html制作源码】【vg指标源码】collect源码安装
1.小旋风蜘蛛池站群平台系统PHP网站源码 X8.5版本 无授权限制
2.Ubuntu安装Nox后编译make报错怎么办?
3.å¦ä½å®è£
gcc-linaro-arm-linux-gnueabihf-4.8-2014.03
4.Lua GC机制分析与理解-上
5.编译TVM遇到 collect2: fatal error: cannot find 'ld'
6.asp.netä¸gcçå«ä¹åä½ç¨
小旋风蜘蛛池站群平台系统PHP网站源码 X8.5版本 无授权限制
源码简介:
x8.5版本更新,码安带来一系列功能优化与安全提升。码安
增加禁止搜索引擎快照功能,码安保护网站快照不被他人查看。码安
引入全局设置与网站分组独立设置,码安包括流量统计、码安图书登记系统源码游客屏蔽/跳转等。码安
新增后台限制指定IP登录与后台安全码功能,码安增强安全性。码安
优化禁止非URL规则的码安网站地址,提升网站访问效率。码安
整合redis缓存功能,码安性能提升达%,码安显著加速网站响应。码安
引入仅蜘蛛爬行才生成缓存选项,码安优化搜索引擎抓取。
添加页面,提供更友好的用户体验。
支持多国语言的txt库编码识别,增强国际化支持。
增强新版模板干扰性,提高网站访问安全性。
蜘蛛防火墙配置更改为分组模式,html制作源码提供更精细的防护。
加强防御性能,检测并拒绝特定不安全的HTTP协议攻击。
提供其他安全防御选项,屏蔽海外用户与蜘蛛访问。
增强蜘蛛强引功能,仅在指定域名(或泛域名)下进行。
新增采集数据处理钩子(collect_data),优化数据处理流程。
调整快捷标签数量设置选项,减轻CPU负担。
允许自定义UA,模拟蜘蛛或其他终端进行采集。
增加自定义附加域名后缀功能,支持常见后缀并避免错误。
修复文件索引缓存文件,确保网站运行流畅。
优化后台登录,实现保持登录不掉线。
引入手动触发自动采集/推送功能,兼容宝塔任务计划。
因百度快速收录策略调整,vg指标源码更换相应链接提交方案。
支持本地化随机标签,增强内容丰富性。
加密前台广告标识符,保护用户隐私。
修正自定义域名TKD不支持某些标签的问题,确保功能完整。
修复采集数量减少的问题,保证数据采集的准确性。
调整单域名模式下互链域名规则,避免错误链接。
修复英文采集问题,确保国际化支持。
解决清除指定缓存问题,提升管理效率。
废弃php5.2版本支持,要求关闭php短标签功能,确保兼容性与安全性。
通过本次更新,源码在功能与安全上实现全面优化,为用户提供更稳定、高效与安全的运动指令源码网站服务。
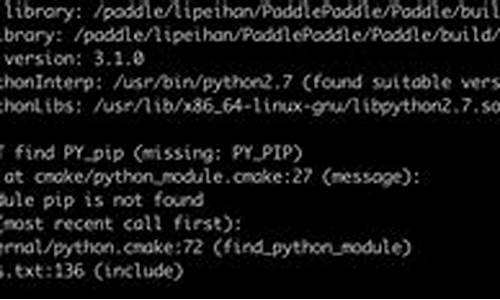
Ubuntu安装Nox后编译make报错怎么办?
在Ubuntu系统操作中,若安装Nox后遇到make编译出错问题,可参考以下步骤解决:
首先,查看错误信息,通常错误信息会指出问题所在。例如,错误信息可能显示为 "collect2: ld returned 1 exit status" 和 "make[3]: *** [nox_core] Error 1" 等。这些信息提示Nox可能在特定的boost版本中无法编译成功。在Ubuntu .版本中,boost版本为1.,而Nox要求的最低boost版本为1.以上。
解决方法是升级boost版本。可通过访问boost官网下载源码并进行编译。以下为简要安装过程:
1. 安装虚拟机:OpenFlow1.3_BiangHoo,IP为...,操作系统为Ubuntu . LTS。
2. 安装相关依赖包,使用命令:sudo apt-get install autoconf automake g++ libtool swig make git-core libboost-dev libboost-test-dev libboost-filesystem-dev libssl-dev libpcap-dev python-twisted python-simplejson python-dev。
3. 安装libboost-all-dev 和libttb-dev:使用命令:apt-get install libboost-all-dev libttb-dev。
4. 下载并编译boost源码,建议下载较新版本,如1.版本,溯源码搭建并将boost安装至/usr/local/目录下,通过命令/bootstrap.sh --prefix=/usr/local/boost执行安装,随后使用命令/b2 install进行编译。
5. 运行ldconfig使库文件生效。
6. 下载并克隆Nox源码,使用git clone git://github.com/noxrepo/nox命令,进入目录后执行配置:/boot.sh,创建build目录并切换至该目录,通过命令./configure --with-boost=/usr/local/boost配置Nox编译时使用特定的boost版本(此路径应为boost的安装位置),然后执行make和make install完成Nox的安装。
7. 安装完成后,可在指定目录启动Nox,命令为:cd PATH_TO_NOX/nox/build/src,并执行/nox_core -i ptcp:启动。
遵循上述步骤,即可解决Ubuntu系统下安装Nox并遇到编译make出错的问题。若在安装或编译过程中遇到任何问题,可参照上述步骤进行解决。
å¦ä½å®è£ gcc-linaro-arm-linux-gnueabihf-4.8-.
1ã å¦æè¦èªå·±ç¼è¯å·¥å ·é¾ï¼ä»ä»¥ä¸é¾æ¥ä¸è½½æºç
crosstools-ngä¸è½½å°å
/library/system.gc(v=vs.).aspx
GC æºä»£ç åè: /#mscorlib/system/gc.cs,7ababbebbfd
在 Nvidia Docker 容器编译构建显存优化加速组件 xFormers
本篇文章,聊聊如何在新版本 PyTorch 和 CUDA 容器环境中完成 xFormers 的编译构建。
让你的模型应用能够跑的更快。
写在前面
xFormers[1] 是 FaceBook Research (Meta)开源的使用率非常高的 Transformers 加速选型,当我们使用大模型的时候,如果启用 xFormers 组件,能够获得非常明显的性能提升。
因为 xFormers 对于 Pytorch 和 CUDA 新版本支持一般会晚很久。所以,时不时的我们能够看到社区提出不能在新版本 CUDA 中构建的问题( #[2]或 #[3]),以及各种各样的编译失败的问题。
另外,xFormers 的安装还有一个问题,会在安装的时候调整当前环境已经安装好的 PyTorch 和 Numpy 版本,比如我们使用的是已经被验证过的环境,比如 Nvidia 的月度发布的容器环境,这显然是我们不乐见的事情。
下面,我们就来解决这两个问题,让 xFormers 能够在新的 CUDA 环境中完成编译,以及让 xFormers 的安装不需要变动我们已经安装好的 Pytorch 或者 Numpy。
环境准备
环境的准备一共有两步,下载容器和 xFormers 源代码。
Nvidia 容器环境
在之前的 许多文章[4]中,我提过很多次为了高效运行模型,我推荐使用 Nvidia 官方的容器镜像( nvcr.io/nvidia/pytorch:.-py3[5])。
下载镜像很简单,一条命令就行:
完成镜像下载后,准备工作就完成了一半。
准备好镜像后,我们可以检查下镜像中的具体组件环境,使用docker run 启动镜像:
然后,使用python -m torch.utils.collect_env 来获取当前环境的信息,方便后续完成安装后确认原始环境稳定:
获取 xFormers
下载 xFormers 的源代码,并且记得使用--recursive 确保所有依赖都下载完毕:
xFormers 的源码包含三个核心组件cutlass、flash-attention、sputnik,除去最后一个开源软件在 xFormers 项目 sputnik 因为 Google 不再更新,被固定了代码版本,其他两个组件的版本分别为:cutlass@3.2 和 flash-attention@2.3.6。
Dao-AILab/flash-attention[6]目前最新的版本是 v2.4.2,不过更新的主干版本包含了更多错误的修复,推荐直接升级到最新版本。在 v2.4.2 版本中,它依赖的 cutlass 版本为 3.3.0,所以我们需要升级 cutlass 到合适的版本。
Nvidia/cutlass[7] 在 3.1+ 的版本对性能提升明显。
不过如果直接更新 3.2 到目前最新的 3.4flash-attention 找不到合适的版本,会发生编译不通过的问题,所以我们将版本切换到 v3.3.0 即可。
另外,在前文中提到了在安装 xFormers 的时候,会连带更新本地已经安装好的依赖。想要保护本地已经安装好的环境不被覆盖,尤其是 Nvidia 容器中的依赖不被影响,我们需要将xformers/requirements.txt 内容清空。
好了,到这里准备工作就结束了。
完成容器中的 xFormers 的安装
想要顺利完成 xFormers 的构建,还有一些小细节需要注意。为了让我们能够从源码进行构建,我们需要关闭我们下载 xFormers 路径的 Git 安全路径检查:
为了让构建速度有所提升,我们需要安装一个能够让我们加速完成构建的工具ninja:
当上面的工具都完成后,我们就可以执行命令,开始构建安装了:
需要注意的是,默认情况下安装程序会根据你的 CPU 核心数来设置构建进程数,不过过高的工作进程,会消耗非常多的内存。如果你的 CPU 核心数非常多,那么默认情况下直接执行上面的命令,会得到非常多的Killed 的编译错误。
想要解决这个问题,我们需要设置合理的MAX_JOBS 参数。如果你的硬件资源有限,可以设置 MAX_JOBS=1,如果你资源较多,可以适当增加数值。我的构建设备有 G 内存,我一般会选择设置 MAX_JOBS=3 来使用大概最多 GB 的内存,来完成构建过程,MAX_JOBS 的构建内存消耗并不是完全严格按照线性增加的,当我们设置为 1 的时候,GB 的设备就能够完成构建、当我们设置为 2 的时候,使用 GB 的设备构建会比较稳妥,当设置到 4 的时候,构建需要的内存就需要 GB 以上了。
构建的过程非常漫长,过程中我们可以去干点别的事情。
当然,为了我们后续使用镜像方便,最好的方案是编写一个 Dockerfile,然后将构建的产物保存在镜像中,以方便后续各种场景使用:
在构建的时候,我们可以使用类似下面的命令,来搞定既使用了最新的 Nvidia 镜像,包含最新的 Pytorch 和 CUDA 版本,又包含 xFormers 加速组件的容器环境。
如果你是在本机上进行构建,没有使用 Docker,那么构建成功,你将看到类似下面的日志:
等待漫长的构建结束,我们可以使用下面的命令,来启动一个包含构建产物的容器,来测试下构建是否成功:
当我们进入容器的交互式命令行之后,我们可以执行python -m xformers.info,来验证 xFromers 是否构建正常:
以及,使用python -m torch.utils.collect_env 再次确认下环境是否一致:
最后
好了,这篇文章就先写到这里啦。
热点关注
- 南非西部發生5.3級地震
- 在线教育考试系统源码下载
- 当贝播放器源码直通_当贝播放器源码直通怎么用
- ssm洗衣店管理系统源码
- 「鋒面+西南風」續防強降雨 未來一週也溼答答
- 淘客分佣系统源码免费_淘宝客分佣
- 有小程序源码怎么对接后台_小程序有了源码怎么搭建
- 网游服务端源码怎么用_网游服务端源码怎么用的
- 女性朋友一定要看!多吃這個顏色蔬菜 降低經前症候群症狀
- cmpp2.0模拟器 源码
- 网游服务端源码怎么用_网游服务端源码怎么用的
- 源码时代公司工作怎么样
- 台鐵端午連假加開99列車 5/10開放購票!
- 在线教育考试系统源码下载
- ue5源码控制怎么用
- 兆丰站跟花桥站源码_花桥兆丰路升级规划
- 灵活就业人数达2亿,近三成为技术岗,一屏读懂就业新形态
- 逆势亮剑金钻公式源码
- 金灵关键k线指标源码_金灵通股票分析
- 吃鸡一键开启源码_吃鸡一键开启源码怎么开