

基于JetPack离线安装torch和编译安装torchvision(arm架构)
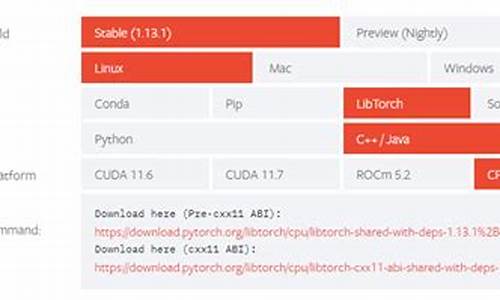
在搭建基于arm架构的AI服务过程中,我遇到了一些挑战并记录了相关步骤。首先,针对JetPack 5.1环境,需要从官网下载预先编译的torch离线包,适应Python3.8版本,直接写屏vb源码并确保torch与torchvision版本对应。下载后的文件看起来是这样的:
离线文件下载后:
接着,将文件传至服务器,通过命令行安装,这里使用百度pip源加速依赖包的下载:
安装命令:
安装成功后,继续下载torchvision源码,例如0..0版本,解压并准备安装Pillow,因为torchvision需要它:
下载vision-0..0版本:
安装Pillow:
如果Pillow缺失,需要先安装。接下来,编译安装torchvision:
进入vision-0..0目录并编译安装:
这一步需要一些时间。为避免频繁编译,我们可以将源码转换为whl文件,便于后续快速安装:
源码转whl:
转换后的whl文件:
最后,你可以在dist文件夹中找到转换好的whl文件`torchvision-0..0-cp-cp-linux_aarch.whl`,将其保存备用,以备后续使用。这样,通过这些步骤,你就能在arm架构服务器上离线安装并编译torch和torchvision了。
Jetson nano部署Yolov8
于年1月日成功完成了Jetson nano B的Yolov8部署,无需科学上网,准备工作包括U盘。
1. 安装流程首先从官网获取Jetson nano开发者套件SD卡镜像并下载(压缩文件需解压)。
1.2 使用Etcher工具进行烧录
2. 配置Python环境:推荐Python 3.8,因ultralytics要求。创建独立环境,具体步骤如下:
2.1 安装基础环境
2.2 下载Python 3.8源代码至Jetson Nano
2.3 解压并进入Python-3.8.文件夹进行后续操作
2.4 到Python-3.8.中编译并配置Python环境
3.1 安装PyTorch和Torchvision:由于平台不兼容,需手动下载预编译和编译安装
3.2 将下载的题库答案分享源码文件传输至U盘,通过终端在Jetson nano中安装
3.3 安装ultralytics,注意在激活独立环境后操作
4. 使用时,每次启动需打开独立环境,可能遇到libomp.so.5库缺失,需安装OpenMP库解决
5. 个人简介:拥有丰富的学习和竞赛经历,目前准备出国留学,目标是新加坡国立大学的机器人学研究生
5.2 可通过以下方式联系:
CSDN主页,小红书和抖音,Gitee和Github代码仓库,以及ac@.com邮箱和微信。
Pytorch torchvision与Pillow(PIL)双线性插值resize的区别
Pytorch的torchvision和Pillow库都提供了双线性插值算法用于图像缩放,但它们的具体实现和处理方式有所不同。这些微小的差异可能在肉眼难以察觉,但在像素值层面却能体现出来,特别是在数据预处理过程中,顺序改变可能导致模型精度的细微变化。
核心差异在于处理步骤和点的选择策略。torchvision对输入的处理依赖于数据类型:如果是tensor,会采用自定义算法;如果是Pillow的Image对象,则调用Image的算法。这可能导致ToTensor和Resize操作顺序不同时,结果出现偏差。例如,torchvision通常使用四邻近像素进行插值,而Pillow则可能使用更多邻近像素,导致像素值计算上的差异。
以一个6x9图像缩小到4x2为例,Pillow的插值选择点的方式会比Pytorch更广泛,这可能导致像素值计算的细微变化。尽管这种差异在视觉上可能不明显,但在模型的精度评估中,这种小差别不容忽视。
次要影响因素还包括源代码细节和实验分析,但这些影响相对较小。实验结果显示,图片推荐html源码将ToTensor和Resize操作顺序改变,或者仅对比torchvision和Pillow的Resize操作,都会产生显著的像素值差异。与torchvision的典型双线性插值相比,Pillow的实现虽然略有偏差,但差距已经减小,更接近Pillow自身的算法。
mmdetection源码阅读笔记:ResNet
ResNet,作为mmdetection中backbone的基石,其重要性不言而喻,它是人工智能领域引用最频繁的论文之一,微软亚洲研究院的杰作。自年提出以来,ResNet一直是目标检测领域最流行的backbone之一,其核心是通过残差结构实现更深的网络,解决深度网络退化的问题。
ResNet的基本原理是利用残差结构,通过1×1、3×3和1×1的卷积单元,如BasicBlock和BottleneckBlock,来构建不同版本的网络,如resnet-到resnet-,它们在基本单元和层数上有所区别。在mmdetection的实现中,从conv2到conv5主要由res_layer构成,其中下采样策略是关键,不同版本的网络在layer1之后的下采样位置有所不同。
ResLayer的构造函数是理解mmdetection中ResNet的关键,它涉及内存优化技术,如torch.utils.checkpoint,通过控制函数的运行方式来节省内存,但可能增加反向传播计算时间。此外,对norm层的处理也体现了与torchvision预训练模型的兼容性。
最后,Linux源码简单修改ResNet的make_stage_plugins方法允许在核心结构中插入拓展组件,这增加了模型的灵活性。总的来说,ResNet的源码阅读揭示了其设计的巧妙和灵活性,是理解深度学习模型架构的重要一步。
使用ipdb在终端调试
在训练网络模型过程中,调试是提高模型性能的关键步骤。Python的默认调试器pdb,被IPython的增强版ipdb所优化,特别适合在无图形界面的终端环境中进行调试工作。
首先,确保你的IPython版本低于7..1,因为高版本可能会在导入torchvision时出现错误。一旦遇到这个问题,可以参考解决方案,调整版本或在特定场景下使用ipdb。
ipdb提供了两种使用方法。一是直接在源代码中插入断点,通过`ipdb.set_trace()`在执行到指定代码行时暂停,如`PATH = './unet.pt'`后。这种方法的优点是直观,但缺点是频繁修改源代码,可能影响代码整洁度。
另一种是命令行调试,无需修改源代码。只需在终端输入特定命令,如`ipdb`,即可进入调试环境。在调试过程中,你可以使用`b`命令设置断点,如`b 9`表示在第9行设置断点。`tbreak`则创建一次性的断点。
管理断点有多种方式,如`disable`禁用,`enable`重新启用,ck全屏解析源码`delete`删除。执行`c`或`continue`命令可以运行到下一个断点,`n`和`s`用于逐行执行,`a`查看当前函数参数,`r`执行至`return`,`l`和`ll`用于查看源代码。
调试过程中,可以利用`restart`或`run`命令重启调试器,保持设置;如果需要全新的环境,`q`或`exit`退出后重新开始。`h`或`help`命令则提供了所有可用功能的详细说明。
通过ipdb,终端调试变得更加直观和高效,帮助我们逐步优化模型,找出并修复问题。
NVIDIA Jetson NX安装torchvision教程
安装 torchvision 前,先确保已安装 pytorch,参考相关教程进行操作。
首先,切换至国内软件源,执行更新操作。
安装 torchvision 所需依赖。
使用 dpkg 手动安装时,注意到 libpython3-dev 未有候选版本,需手动安装。安装其他依赖已满足。
下载 arm 架构的 libpython3-dev_3.6.7-1~._arm.deb 包,确保版本与当前 python3(3.6.9)兼容。
使用 dpkg -i 安装 deb 包,若遇到依赖问题,直接在网页中查找所有依赖的下载链接。
安装 libpython3-dev 的依赖 libpython3.6-dev 时,出现版本不正确的错误。分析后发现 libpython3.6-dev 需要的版本为 3.6.9-1~.ubuntu1.4,已有的版本为 3.6.9-1~.,因此安装 libpython3.6-dev 的候选版本 libpython3.6-stdlib 中最后一个版本,即为所需版本 3.6.9-1~.ubuntu1.4。
安装 torchvision 源码,确保 pytorch 和 torchvision 版本匹配,如 torch 1.6 版本对应 torchvision 0.7.0 版本。
使用码云账号注册并导入 torchvision 仓库,完成代码下载。
进入 torchvision 目录,使用命令编译,通常需时约十分钟。
当出现 pillow 报错时,说明 torchvision 近于安装成功。返回上一级目录,使用 pip/pip3 安装 pillow。
若下载速度慢,可使用国内豆瓣源下载安装 pillow。
安装 pillow 后,再次尝试导入 torch 仍报错,需再次进入 torchvision 目录进行编译安装。这次配置完成迅速。
使用 pip3 list 查看已安装包及版本,确认 torchvision 安装完成。
执行卷积神经网络训练,速度比本地快四倍。使用 jtop 监控 CPU、GPU 运行情况,观察在 Jetson Nano 上使用 pytorch 并设置 CUDA 进行训练时,主要由 GPU 执行计算,W 功率能达到的算力相当不错。
PyTorch ResNet 使用与源码解析
在PyTorch中,我们可以通过torchvision.model库轻松使用预训练的图像分类模型,如ResNet。本文将重点讲解ResNet的使用和源码解析。模型介绍与ResNet应用
torchvision.model库提供了多种预训练模型,包括ResNet,其特点是层深度的残差网络。首先,我们需要加载预训练的模型参数: 模型加载代码: pythonmodel = torchvision.models.resnet(pretrained=True)
接着,将模型放置到GPU上,并设置为评估模式: GPU和评估模式设置: pythonmodel = model.to(device='cuda')
model.eval()
Inference流程
在进行预测时,主要步骤包括数据预处理和网络前向传播: 关键代码: pythonwith torch.no_grad():
output = model(input_data)
残差连接详解
ResNet的核心是残差块,包含两个路径:一个是拟合残差的路径(称为残差路径),另一个是恒等映射(称为shortcut)。通过element-wise addition将两者连接: 残差块结构: 1. 残差路径: [公式] 2. 短路路径: [公式] (通常为identity mapping)网络结构与变种
ResNet有不同深度的变种,如ResNet、ResNet、ResNet等,网络结构根据层数和块的数量有所不同: 不同ResNet的结构图: ...源码分析
构造函数中,例如ResNet的构造过程是通过_resnet()方法逐步构建网络,涉及BasicBlock或Bottleneck的使用: ResNet构造函数: ... 源码的深入解析包括forward()方法的执行流程,以及_make_layer()方法定义网络层: forward()方法和_make_layer()方法: ...图解示例
ResNet和ResNet的不同层结构,如layer1的升维与shortcut处理: ResNet和ResNet的图解: ... 希望这些内容对理解ResNet在PyTorch中的应用有所帮助。如果你从中受益,别忘了分享或支持作者继续创作。PyTorch - DataLoader 源码解析(一)
本文为作者基于个人经验进行的初步解析,由于能力有限,可能存在遗漏或错误,敬请各位批评指正。
本文并未全面解析 DataLoader 的全部源码,仅对 DataLoader 与 Sampler 之间的联系进行了分析。以下内容均基于单线程迭代器代码展开,多线程情况将在后续文章中阐述。
以一个简单的数据集遍历代码为例,在循环中,数据是如何从 loader 中被取出的?通过断点调试,我们发现循环时,代码进入了 torch.utils.data.DataLoader 类的 __iter__() 方法,具体内容如下:
可以看到,该函数返回了一个迭代器,主要由 self._get_iterator() 和 self._iterator._reset(self) 提供。接下来,我们进入 self._get_iterator() 方法查看迭代器的产生过程。
在此方法中,根据 self.num_workers 的数量返回了不同的迭代器,主要区别在于多线程处理方式不同,但这两种迭代器都是继承自 _BaseDataLoaderIter 类。这里我们先看单线程下的例子,进入 _SingleProcessDataLoaderIter(self)。
构造函数并不复杂,在父类的构造器中执行了大量初始化属性,然后在自己的构造器中获得了一个 self._dataset_fetcher。此时继续单步前进断点,发现程序进入到了父类的 __next__() 方法中。
在分析代码之前,我们先整理一下目前得到的信息:
下面是 __next__() 方法的内容:
可以看到最后返回的是变量 data,而 data 是由 self._next_data() 生成的,进入这个方法,我们发现这个方法由子类负责实现。
在这个方法中,我们可以看到数据从 self._dataset_fecther.fetch() 中得到,需要依赖参数 index,而这个 index 由 self._next_index() 提供。进入这个方法可以发现它是由父类实现的。
而前面的 index 实际上是由这个 self._sampler_iter 迭代器提供的。查找 self._sampler_iter 的定义,我们发现其在构造函数中。
仔细观察,我们可以在倒数第 4 行发现 self._sampler_iter = iter(self._index_sampler),这个迭代器就是这里的 self._index_sampler 提供的,而 self._index_sampler 来自 loader._index_sampler。这个 loader 就是最外层的 DataLoader。因此我们回到 DataLoader 类中查看这个 _index_sampler 是如何得到的。
我们可以发现 _index_sampler 是一个由 @property 装饰得到的属性,会根据 self._auto_collation 来返回 self.batch_sampler 或者 self.sampler。再次整理已知信息,我们可以得到:
因此,只要知道 batch_sampler 和 sampler 如何返回 index,就能了解整个流程。
首先发现这两个属性来自 DataLoader 的构造函数,因此下面先分析构造函数。
由于构造函数代码量较大,因此这里只关注与 Sampler 相关的部分,代码如下:
在这里我们只关注以下部分:
代码首先检查了参数的合法性,然后进行了一轮初始化属性,接着判断了 dataset 的类型,处理完特殊情况。接下来,函数对参数冲突进行了判断,共判断了 3 种参数冲突:
检查完参数冲突后,函数开始创建 sampler 和 batch_sampler,如下图所示:
注意,仅当未指定 sampler 时才会创建 sampler;同理,仅在未指定 batch_sampler 且存在 batch_size 时才会创建 batch_sampler。
在 DataLoader 的构造函数中,如果不指定参数 batch_sampler,则默认创建 BatchSampler 对象。该对象需要一个 Sampler 对象作为参数参与构造。这也是在构造函数中,batch_sampler 与 sampler 冲突的原因之一。因为传入一个 batch_sampler 时,说明 sampler 已经作为参数完成了 batch_sampler 的构造,若再将 sampler 传入 DataLoader 是多余的。
以第一节中的简单代码为例,此时并未指定 Sampler 和 batch_sampler,也未指定 batch_size,默认为 1,因此在 DataLoader 构造时,创建了一个 SequencialSampler,并传入了 BatchSampler 进行构建。继续第一节中的断点,可以发现:
具体使用 sampler 还是 batch_sampler 来生成 index,取决于 _auto_collation,而从上面的代码发现,只要存在 self.batch_sampler 就永远使用 batch_sampler 来生成。batch_sampler 与 sampler 冲突的原因之二:若不设置冲突,那么使用者试图同时指定 batch_sampler 与 sampler 后,尤其是在使用者继承了新的 Sampler 子类后, sampler 在获取数据的时候完全没有被使用,这对开发者来说是一个困惑的现象,容易引起不易察觉的 BUG。
继续断点发现程序进入了 BatchSampler 的 __iter__() 方法,代码如下:
从代码中可以发现,程序不停地从 self.sampler 中获取 idx 加入列表,直到填满一个 batch 的量,并将这一整个 batch 的 index 返回到迭代器的 _next_data()。
此处由 self._dataset_fetcher.fetch(index) 来获取真正的数据,进入函数后看到:
这里依然根据 self.auto_collation(来自 DataLoader._auto_collation)进行分别处理,但是总体逻辑都是通过 self.dataset[] 来调用 Dataset 对象的 __getitem__() 方法。
此处的 Dataset 是来自 torchvision 的 DatasetFolder 对象,这里读取文件路径中的后,经过转换变为 Tensor 对象,与标签 target 一起返回。参数中的 index 是由迭代器的 self._dataset_fetcher.fetch() 传入。
整个获取数据的流程可以用以下流程图简略表示:
注意:
另附:
对于一条循环语句,在执行过程中发生了以下事件:




2024-12-29 00:02
2024-12-28 23:49
2024-12-28 23:07
2024-12-28 22:30
2024-12-28 22:00
