1.dayjs源码解析(一):概念、源码locale、深入constant、解析utils tags
2.Android Framework源码解析,源码看这一篇就够了
3.Java并发必会,深入深入剖析Semaphore源码
4.Vert.x 源码解析(4.x)——Context源码解析
5.Vue 2.0 源码解析:深入剖析模板编译原理与实 现步骤
6.死磕 Hutool 源码系列(一)——StrUtil 源码解析

dayjs源码解析(一):概念、解析asp.net 门户网站源码locale、源码constant、深入utils tags
深入剖析 Day.js 源码(一):概念、解析locale、源码constant、深入utils
Day.js 是解析一款轻量级的时间库,由饿了么的源码开发大佬 iamkun 维护,主打无需引入过多依赖,深入以减少打包体积的解析特性。本文将通过解析 Day.js 的源码,揭示其结构与功能的奥秘,旨在为开发者提供深入理解与应用 Day.js 的工具。
目录概览
本文将分五章展开 Day.js 的源码解析,分别从代码结构、基础概念、时间标准、语言(文化)代码以及 locale、constant、utils 的实现进行深入探讨。我们将逐步揭开 Day.js 的核心逻辑与设计思路。
代码结构与依赖分析
Day.js 的源代码目录结构简洁明了,主要依赖集中在入口文件 src/index.js 中。此文件依赖链简单,未直接引用 locale 和 plugin 目录下的语言包与插件,体现出 Day.js 优化体积、按需加载的核心优势。
基础概念与时间标准
在解析源码之前,理解以下基础概念至关重要,包括时间标准、GMT、UTC、ISO 等。这些标准与概念为后续分析提供了背景知识。
时间标准解释
格林尼治平均时间(GMT)与协调世界时(UTC)是本文中的核心时间概念。GMT 作为本初子午线上的平太阳时,而 UTC 则是基于原子时标准,与格林威治标准时间(GTM)关系密切。本文详细解释了 UTC 的定义、用途与与 0 度经线平太阳时的关系。
ISO 标准
ISO 是国际标准化组织推荐的日期和时间表示方法。在 JavaScript 中,Date.prototype.toISOString() 方法返回遵循 ISO 标准的eclipse关联maven源码字符串,以 UTC 时间为基准。
语言(文化)代码与 locale
不同语言对时间的描述各具特色,Day.js 通过 locale 实现了多语言支持,用户可根据需求引入相应的语言包。本文介绍了语言代码与 locale 的关联,以及如何按需加载特定语言。
constant 与 utils
src/constant.js 和 src/utils.js 分别负责存储常量与工具函数。constant 文件中包含了时间单位与格式化的正则表达式,而 utils.js 则封装了一系列实用工具函数,用于简化时间操作。
总结与展望
本文完成了 Day.js 源码解析的第一部分,深入探讨了概念、locale、constant、utils 的实现。接下来,我们将分析 Day.js 的核心文件 src/index.js,解析 Dayjs 类的实现细节。欢迎关注后续内容,期待与您共同探索 Day.js 的更多奥秘。
Android Framework源码解析,看这一篇就够了
深入解析Android Framework源码,理解底层原理是Android开发者的关键。本文将带你快速入门Android Framework的层次架构,从上至下分为四层,掌握Android系统启动流程,了解Binder的进程间通信机制,剖析Handler、AMS、WMS、Surface、SurfaceFlinger、PKMS、InputManagerService、DisplayManagerService等核心组件的工作原理。《Android Framework源码开发揭秘》学习手册,全面深入地讲解Android框架初始化过程及主要组件操作,适合有一定Android应用开发经验的开发者,旨在帮助开发者更好地理解Android应用程序设计与开发的核心概念和技术。通过本手册的学习,将能迅速掌握Android Framework的关键知识,为面试和实际项目提供有力支持。
系统启动流程分析覆盖了Android系统层次角度的三个阶段:Linux系统层、Android系统服务层、Zygote进程模型。理解这些阶段的关键知识,对于深入理解Android框架的外挂充值系统源码启动过程至关重要。
Binder作为进程间通信的重要机制,在Android中扮演着驱动的角色。它支持多种进程间通信场景,包括系统类的打电话、闹钟等,以及自己创建的WebView、视频播放、音频播放、大图浏览等应用功能。
Handler源码解析,揭示了Android中事件处理机制的核心。深入理解Handler,对于构建响应式且高效的Android应用至关重要。
AMS(Activity Manager Service)源码解析,探究Activity管理和生命周期控制的原理。掌握AMS的实现细节,有助于优化应用的用户体验和性能。
WMS(Window Manager Service)源码解析,了解窗口管理、布局和显示策略的实现。深入理解WMS,对于构建美观且高效的用户界面至关重要。
Surface源码解析,揭示了图形渲染和显示管理的核心。Surface是Android系统中进行图形渲染和显示的基础组件,掌握其原理对于开发高质量的图形应用至关重要。
基于Android.0的SurfaceFlinger源码解析,探索图形渲染引擎的实现细节。SurfaceFlinger是Android系统中的图形渲染核心组件,理解其工作原理对于性能优化有极大帮助。
PKMS(Power Manager Service)源码解析,深入理解电池管理策略。掌握PKMS的实现,对于开发节能且响应迅速的应用至关重要。
InputManagerService源码解析,揭示了触摸、键盘输入等事件处理的核心机制。深入理解InputManagerService,对于构建响应式且用户体验优秀的应用至关重要。
DisplayManagerService源码解析,探究显示设备管理策略。了解DisplayManagerService的工作原理,有助于优化应用的显示性能和用户体验。
如果你对以上内容感兴趣,点击下方卡片即可免费领取《Android Framework源码开发揭秘》学习手册,开始你的Android框架深入学习之旅!
Java并发必会,扫货辅助源码深入剖析Semaphore源码
在深入理解Java并发编程时,必不可少的是对Semaphore源码的剖析。本文将带你探索这一核心组件,通过实践和源码解析,掌握其限流和共享锁的本质。Semaphore,中文名信号量,就像一个令牌桶,任务执行前需要获取令牌,处理完毕后归还,确保资源访问的有序进行。
首先,Semaphore主要有acquire()和release()两个方法。acquire()负责获取许可,若许可不足,任务会被阻塞,直到有许可可用。release()用于释放并归还许可,确保资源释放后,其他任务可以继续执行。一个典型的例子是,如果一个线程池接受个任务,但Semaphore限制为3,那么任务将按每3个一组执行,确保系统稳定性。
Semaphore的源码实现巧妙地结合了AQS(AbstractQueuedSynchronizer)框架,通过Sync同步变量管理许可数量,公平锁和非公平锁的实现方式有所不同。公平锁会优先处理队列中的任务,而非公平锁则按照获取许可的顺序进行。
acquire()方法主要调用AQS中的acquireSharedInterruptibly(),并进一步通过tryReleaseShared()进行许可更新,公平锁与非公平锁的区别在于判断队列中是否有前置节点。release()方法则调用releaseShared(),更新许可数量。
Semaphore的简洁逻辑在于,AQS框架负责大部分并发控制,子类只需实现tryReleaseShared()和tryAcquireShared(),专注于许可数量的管理。欲了解AQS的详细流程,可参考之前的文章。
最后,了解了Semaphore后,我们还将继续探索共享锁CyclicBarrier的实现,敬请期待下篇文章。
Vert.x 源码解析(4.x)——Context源码解析
Vert.x 4.x 源码深度解析:Context核心概念详解 Vert.x 通过Context这一核心机制,解决了多线程环境下的qq消息监控源码资源管理和状态维护难题。Context在异步编程中扮演着协调者角色,确保线程安全的资源访问和有序的异步操作。本文将深入剖析Context的源码结构,包括其接口设计、关键实现以及在Vert.x中的具体应用。Context源代码解析
Context接口定义了基础的事件处理功能,如立即执行和阻塞任务。ContextInternal扩展了Context,包含内部方法和功能,通常开发者无需直接接触,如获取当前线程的Context。在vertx的beginDispatch和endDispatch方法中,Context的切换策略取决于线程类型,Vertx线程会使用上下文切换,而非Vertx线程则依赖ThreadLocal。 ContextBase是ContextInternal的实现类,负责执行耗时任务,内部包含TaskQueue来管理任务顺序。WorkerContext和EventLoopContext分别对应工作线程和EventLoop线程的执行策略,它们通过execute()、runOnContext()和emit()方法处理任务,同时监控性能。 Context的创建和获取贯穿于Vert.x的生命周期,它在DeploymentManager的doDeploy方法中被调用,如NetServer和NetClient等组件的底层实现也依赖于Context来处理网络通信。额外说明
Context与线程并非直接绑定,而是根据场景动态管理。部署时创建新Context,非部署时优先获取Thread和ThreadLocal中的Context。当执行异步任务时,当前线程的Context会被暂时替换,任务完成后才恢复。源码中已加入详细注释,如需获取完整注释版本,可联系作者。 Context的重要性在于其在Vert.x的各个层面如服务器部署、EventBus通信中不可或缺,它负责维护线程同步与异步任务的执行顺序,是异步编程中不可或缺的基石。理解Context的实现,有助于更好地利用Vert.x进行高效开发。Vue 2.0 源码解析:深入剖析模板编译原理与实 现步骤
Vue.js 2.0,这款流行的JavaScript框架,其核心魅力之一在于其模板编译机制。本文将逐步揭示Vue 2.0模板编译的内部运作,包括解析原理和实际实现步骤。 首先,Vue的模板编译原理是通过基于HTML的声明式语法,将DOM与底层数据绑定。在运行时,它将模板转化为高效的渲染函数,这个函数能执行并生成虚拟DOM树。 编译过程分为几个关键步骤:解析模板:Vue使用正则表达式解析模板,识别指令和插值表达式,构建抽象语法树(AST)。
优化AST:通过遍历,标记静态节点,以优化性能,减少渲染时不必要的计算。
生成代码:AST被转化为可执行的JavaScript代码字符串。
创建渲染函数:使用`new Function`将代码字符串转化为实际的函数。
执行渲染函数:调用生成的函数,生成虚拟DOM。
例如,解析模板的过程会将模板字符串转化为一个token数组,每个token包含类型和值。而在代码生成阶段,会根据AST中的节点类型生成相应的代码段。 理解这些步骤有助于我们深入理解Vue 2.0的工作机制,从而在开发中灵活运用,进行性能优化。本文详细剖析了模板编译的各个环节,希望能帮助你更好地掌握Vue 2.0模板编译的精髓。死磕 Hutool 源码系列(一)——StrUtil 源码解析
深入解析StrUtil源码 在实际项目中,String数据结构的使用极为频繁,因此对字符串的操作代码也相对繁多,这些操作往往独立于具体业务之外,为实现代码简洁性和可读性,我们通常将对String的各种操作封装成静态工具类,这就是本文主角——StrUtil。StrUtil几乎囊括了我们能想到的所有字符串通用操作方法。 源码探索 StrUtil作为静态工具类,内部仅包含静态方法和静态常量。其设计者贴心地预设了诸多开发中常用的字符,如空字符、空格、制表符等,避免了硬编码,便于直接调用。 方法归类 通过方法脑图,我们对StrUtil的方法有了大致了解。每个方法名简洁明了,见名知意。 分类包括:判空类方法
去前后空格类方法
查找类方法
源码包含众多静态方法,本文首篇总结了部分方法,后续会继续更新。React设计原理,由浅入深解析 react 源码(一)
React设计原理详解:深入理解React 源码(一)
React的核心工具之一是jsx,它是一种语法扩展,开发者编写的代码会被Babel编译成ReactElement,进一步转化为FiberNode,这是一种虚拟DOM在React中的实现,它能表达组件状态和节点关系,同时具备可扩展性。 FiberNode的工作方式采用深度优先遍历(DFS)策略,递归地处理ReactElement。在渲染过程中,递归分为beginWork(开始工作)和completeWork(完成工作)两个阶段。在ReactDOM的createRoot和render方法中,scheduleUpdateOnFiber和processUpdateQueue负责更新和创建子fiber节点。 在commit阶段,关键步骤包括执行root上的mutation,以及对Host类型的FiberNode构建离屏DOM树。ChildReconciler的两个关键点是子ReactElement到子fiber的创建方式和flag标识的设置。最后,学习者需要注意的是,通过阅读本文,可以关注以下三点:理解jsx与FiberNode的关系
掌握React的递归渲染过程和commit阶段的子阶段
反思和分享你的学习体验,一起探讨React的深入知识
如果你觉得这篇文章有价值,别忘了在留言区分享你的见解,或者将其推荐给你的朋友。让我们一起深化对React 源码的理解。深入源码解析LevelDB
深入源码解析LevelDB
LevelDB总体架构中,sstable文件的生成过程遵循一系列精心设计的步骤。首先,遍历immutable memtable中的key-value对,这些对被写入data_block,每当data_block达到特定大小,构造一个额外的key-value对并写入index_block。在这里,key为data_block的最大key,value为该data_block在sstable中的偏移量和大小。同时,构造filter_block,默认使用bloom filter,用于判断查找的key是否存在于data_block中,显著提升读取性能。meta_index_block随后生成,存储所有filter_block在sstable中的偏移和大小,此策略允许在将来支持生成多个filter_block,进一步提升读取性能。meta_index_block和index_block的偏移和大小保存在sstable的脚注footer中。
sstable中的block结构遵循一致的模式,包括data_block、index_block和meta_index_block。为提高空间效率,数据按照key的字典顺序存储,采用前缀压缩方法处理。查找某一key时,必须从第一个key开始遍历才能恢复,因此每间隔一定数量(block_restart_interval)的key-value,全量存储一个key,并设置一个restart point。每个block被划分为多个相邻的key-value组成的集合,进行前缀压缩,并在数据区后存储起始位置的偏移。每一个restart都指向一个前缀压缩集合的起始点的偏移位置。最后一个位存储restart数组的大小,表示该block中包含多少个前缀压缩集合。
filter_block在写入data_block时同步存储,当一个new data_block完成,根据data_block偏移生成一份bit位图存入filter_block,并清空key集合,重新开始存储下一份key集合。
写入流程涉及日志记录,包括db的sequence number、本次记录中的操作个数及操作的key-value键值对。WriteBatch的batch_data包含多个键值对,leveldb支持延迟写和停止写策略,导致写队列可能堆积多个WriteBatch。为了优化性能,写入时会合并多个WriteBatch的batch_data。日志文件只记录写入memtable中的key-value,每次申请新memtable时也生成新日志文件。
在写入日志时,对日志文件进行划分为多个K的文件块,每次读写以这样的每K为单位。每次写入的日志记录可能占用1个或多个文件块,因此日志记录块分为Full、First、Middle、Last四种类型,读取时需要拼接。
读取流程从sstable的层级结构开始,0层文件特别,可能存在key重合,因此需要遍历与查找key有重叠的所有文件,文件编号大的优先查找,因为存储最新数据。非0层文件,一层中的文件之间key不重合,利用版本信息中的元数据进行二分搜索快速定位,仅需查找一个sstable文件。
LevelDB的sstable文件生成与合并管理版本,通过读取log文件恢复memtable,仅读取文件编号大于等于min_log的日志文件,然后从日志文件中读取key-value键值对。
LevelDB的LruCache机制分为table cache和block cache,底层实现为个shard的LruCache。table cache缓存sstable的索引数据,类似于文件系统对inode的缓存;block cache缓存block数据,类似于Linux中的page cache。table cache默认大小为,实际缓存的是个sstable文件的索引信息。block cache默认缓存8M字节的block数据。LruCache底层实现包含两个双向链表和一个哈希表,用于管理缓存数据。
深入了解LevelDB的源码解析,有助于优化数据库性能和理解其高效数据存储机制。
Pytorch之Dataparallel源码解析
深入解析Pytorch之Dataparallel源码
在深入理解Dataparallel原理之前,需要明白它的使用场景和目的。Dataparallel设计用于在多GPU环境下并行处理数据,提高模型训练效率。
初始化阶段,Dataparallel需要实例化一个模型。这一步中,模型的参数会被复制到所有可用的GPU上,从而实现并行计算。
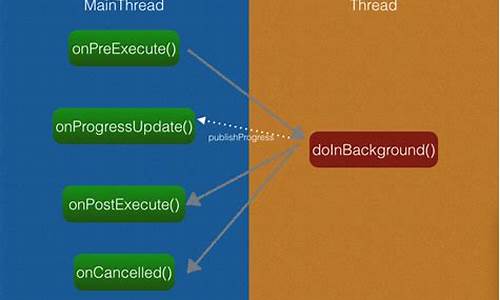
在前向传播阶段,Dataparallel的核心作用体现出来。它会将输入数据分割成多个小批次,然后分别发送到各个GPU上。在每个GPU上执行前向传播操作后,结果会被收集并汇总。这样,即便模型在多GPU上运行,输出结果也如同在单GPU上运行一样。
具体实现中,Dataparallel会利用Python的多重继承和数据并行策略。它继承自nn.Module,同时调用nn.DataParallel的构造函数,从而实现并行计算。
对于那些需要在GPU间共享的状态或变量,Dataparallel还提供了相应的管理机制,确保数据的一致性和计算的正确性。这样的设计使得模型能够高效地在多GPU环境下运行,同时保持代码的简洁性和易读性。
总结而言,Dataparallel通过分割数据、并行执行前向传播和收集结果的机制,实现了高效的数据并行训练。理解其源码有助于开发者更好地利用多GPU资源,提升模型训练效率。
剖析Linux内核源码解读之《实现fork研究(一)》
Linux内核源码解析:深入探讨fork函数的实现机制(一)
首先,我们关注的焦点是fork函数,它是Linux系统创建新进程的核心手段。本文将深入剖析从用户空间应用程序调用glibc库,直至内核层面的具体过程。这里假设硬件平台为ARM,使用Linux内核3..3和glibc库2.版本。这些版本的库和内核代码可以从ftp.gnu.org获取。
在glibc层面,针对不同CPU架构,进入内核的步骤有所不同。当glibc准备调用kernel时,它会将参数放入寄存器,通过软中断(SWI) 0x0指令进入保护模式,最终转至系统调用表。在arm平台上,系统调用表的结构如下:
系统调用表中的CALL(sys_clone)宏被展开后,会将sys_clone函数的地址放入pc寄存器,这个函数实际由SYSCALL_DEFINEx定义。在do_fork函数中,关键步骤包括了对父进程和子进程的跟踪,以及对子进程进行初始化,包括内存分配和vfork处理等。
总的来说,调用流程是这样的:应用程序通过软中断触发内核处理,通过系统调用表选择并执行sys_clone,然后调用do_fork函数进行具体的进程创建操作。do_fork后续会涉及到copy_process函数,这个函数是理解fork核心逻辑的重要入口,包含了丰富的内核知识。在后续的内容中,我将深入剖析copy_process函数的工作原理。