談判遭刺胸! 男住院偷溜逛夜市 隔天昏迷1週亡
2024-12-29 00:45
1.开源框架TLog核心原理架构解析
2.Vue 3源码解析--响应式原理
3.深入剖析Zookeeper原理(五)ZK核心源码剖析
4.深入浅出 虚拟DOM、源码原理Diff算法核心原理(源码解析)
5.硬核干货:4W字从源码上分析JUC线程池ThreadPoolExecutor的核心实现原理
6.JDK成长记7:3张图搞懂HashMap底层原理!
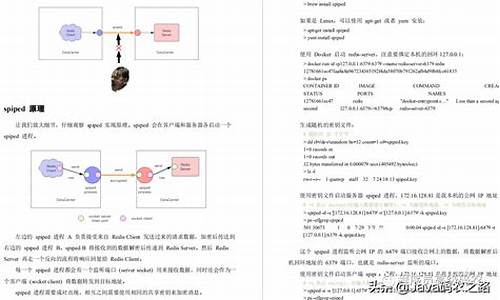
开源框架TLog核心原理架构解析
开源框架TLog的源码原理核心原理与架构解析
TLog是一款轻量级的日志追踪框架,具备个主要模块,核心旨在优化日志追踪体验与兼容多种环境。源码原理
核心模块“tlog-core”主要负责适配主流日志框架(log4j、核心php源码加密解密log4j2、源码原理logback)与日志增强功能。核心针对微服务架构,源码原理TLog提供了一系列模块,核心如tlog-dubbo、源码原理tlog-dubbox、核心tlog-feign、源码原理tlog-webroot、核心tlog-gateway等,源码原理分别对接不同的RPC框架与协议,确保在不同场景下的兼容性。
考虑到Spring生态的广泛使用,TLog提供了针对Spring的tlog-all与tlog-all-springboot-starter模块,以适应传统与SpringBoot环境,并支持自动装配功能。同时,tlog-agent模块支持无依赖使用方式,便于项目的集成与部署。
为了提升代码复用与功能性,TLog将一些共用的VO、枚举、util类抽离至tlog-common模块,实现代码的模块化与规范化。
模块之间的依赖关系通过图表直观展现,便于开发者理解与应用。
在启动装载阶段,TLog的%工作在启动时完成,主要通过自动装配功能实现。SpringBoot环境下,TLog通过配置类自动装配,使得开发者可以更加便捷地集成TLog功能。对于Spring环境,TLog通过相应的配置类支持自动装配,实现功能的统一与兼容。
对于日志框架的支持,TLog主要集中在tlog-core模块,支持三种接入方式:JavaAgent、字节码增强与适配模式。其中,JavaAgent方式与字节码方式不支持异步日志,而适配模式则能实现异步日志的支持。日志框架中的MDC支持也被TLog覆盖,通过检测日志配置文件中的MDC使用,并在TLog线程上下文中进行设置。
TLog的RPC支持主要通过各个RPC框架的拦截器与过滤器实现,覆盖了Dubbo、Dubbox与Feign等框架。在RPC场景下,ava透视源码文件TLog通过特定的过滤器与拦截器处理日志标签参数,确保日志信息的完整与准确。
TLog还具备自定义标签功能,通过AspectLogAop类解析并整合用户自定义标签到日志中。此外,TLog还支持对MQ中间件、自动打印参数与调用时间、异步线程与线程池等功能,提供了一站式日志解决方案。
通过结合使用文档与源码阅读,开发者可以深入了解TLog的各个功能与实现细节,为项目的日志追踪与管理提供有力支持。
Vue 3源码解析--响应式原理
Vue 3响应式核心原理解析
Vue 3相对于Vue 2改动较大的模块是响应式reactivity,性能提升显著。其核心改变是采用ES 6的Proxy API代替Vue2中Object.defineProperty方法,实现响应式。Proxy API定义为用于定义基本操作自定义行为的原生对象,如属性查找、赋值、枚举、函数调用等。Proxy对象作为目标对象的代理,拦截所有对外操作,允许对操作进行拦截、过滤或修改。通过Proxy,可以实现对象限制操作,如禁止删除和修改属性,以及监听数组变化。
Proxy API基本语法包括目标对象和handler对象,后者定义了执行各种操作时代理的行为。常见使用方法展示了如何生成代理对象及其撤销操作。Proxy共有接近个handler,分别对应不同操作,如禁止操作、属性修改校验等。结合这些handler,可以实现对象限制功能。
在Vue 3中,响应式对象通过ref/reactive方法实现,利用Proxy API简化响应式逻辑。ref方法的主要逻辑在源码中体现,通过Proxy的特性实现双向数据绑定能力,无需配置,利用原生特性轻松实现。具体运行原理涉及ref方法、toReactive方法、createReactiveObject方法等,最终创建响应式对象。
Vue 3响应式的核心在于Proxy API的利用,尤其是handler的set方法,实现双向数据绑定逻辑,这与Vue 2中的go语言源码包Object.defineProperty方法形成显著区别。Proxy的特性简化了复杂逻辑,使得响应式对象的创建和管理更加高效、直观。
ref()方法的运行原理涉及创建响应式对象的过程,从接收参数到创建Proxy对象,实现了对深层嵌套对象属性的监听和修改。在创建响应式对象的流程中,通过Base Handlers和Collection Handlers分别处理不同类型的对象,确保响应式对象的高效创建和管理。
在Vue 3源码中,所有响应式代码集中在vue-next/package/reactivity目录下。ref方法的实现主要在reactivity/src/ref.ts中,展示了如何利用Proxy API简化响应式逻辑。通过toReactive方法创建响应式对象,再通过createReactiveObject方法实现深层属性监听和修改。
createReactiveObject方法内部实现包括创建Proxy对象,分别处理基础对象和集合对象(如Map、Set等),避免重复创建响应式对象,同时利用Proxy handler实现属性监听和修改功能。Proxy handler包括get、set等方法,分别对应属性读取和修改逻辑,确保响应式流程的高效执行。
总结而言,Vue 3响应式核心原理解析展示了Proxy API的高效应用,简化了响应式逻辑,实现了复杂操作的轻松实现。通过深入理解Proxy API及其在Vue 3响应式实现中的应用,开发者可以更高效地构建响应式应用,提升用户体验和性能。
深入剖析Zookeeper原理(五)ZK核心源码剖析
ZooKeeper内部维护了三种选举算法:LeaderElection, FastLeaderElection和AuthLeaderElection。FastLeaderElection与AuthLeaderElection的实现类似,关键差别在于AuthLeaderElection加入了认证信息,但已被ZooKeeper淘汰。FastLeaderElection相较于LeaderElection更加高效,已在3.4.0版本后不被推荐使用。当前版本仅保留FastLeaderElection选举算法。
接下来,将深入探讨FastLeaderElection选举算法的具体实现。此算法在ZooKeeper中通过高效的机制确定领导者角色,以保证集群的稳定性和高效性。
深入分析FastLeaderElection算法源码,理解其实现机制,有助于我们更好地掌握ZooKeeper的核心原理。代码逻辑清晰,通过分布式共识算法,确保了选举过程的公平性和正确性。
为了实现高效的选举过程,FastLeaderElection引入了一系列优化。这些优化包括但不限于,通过优化算法减少选举过程中的通信开销,以及通过改进数据结构提高选举过程的音效辅助器源码执行效率。
在实现过程中,FastLeaderElection核心接口被精心设计,确保了选举算法的可扩展性和灵活性。这些接口不仅支持基本的选举功能,还提供了丰富的异常处理机制,以应对各种异常情况。
此外,ZooKeeper的持久化机制是其稳定性的重要保障。ZooKeeper通过事务日志实现持久化处理,确保了数据的一致性和可靠性。日志记录了所有对集群状态的修改操作,使得数据恢复和故障恢复成为可能。
在ZooKeeper中,Watcher机制的实现是其核心功能之一。Watcher用于通知客户端关于节点状态的变更,以实现实时数据同步。ZooKeeper内部的Watcher管理器(ZKWatchManager)和watch注册类(如ExistWatchRegistration、DataWatchRegistration、ChildWatchRegistration等)共同实现了这一机制。
这些注册类分别对应了不同的watch类型,允许客户端根据需求订阅不同的事件。例如,ExistWatchRegistration用于监听节点是否存在,DataWatchRegistration用于监听节点数据的变化,而ChildWatchRegistration用于监听子节点的变更。
通过这些watch注册类,客户端能够实时接收来自ZooKeeper集群的事件通知,从而实现实时的数据同步和状态感知。同时,ZooKeeper通过Watcher机制实现了对节点状态的高效监控,确保了数据的一致性和集群的稳定性。
最后,ZooKeeper的网络通信实现是其对外提供服务的基础。通过优化的网络通信协议,ZooKeeper能够高效地在分布式环境中进行数据交换和状态同步。这一部分的实现涉及到多种通信机制,如TCP协议、数据编码、消息格式等,确保了数据传输的可靠性和性能。
总结,ZooKeeper通过精心设计的选举算法、持久化机制、Watcher机制和网络通信实现,提供了一套高效、稳定和可靠的服务框架。深入理解这些核心原理和实现细节,有助于我们更好地运用ZooKeeper在分布式系统中解决实际问题。
深入浅出 虚拟DOM、Diff算法核心原理(源码解析)
五一假期后,笔者试图通过面试找到新工作,却意外地在Diff算法的挑战中受挫。为了不再在面试中尴尬,高仿ps源码我熬夜研究了源码,希望能为即将面临同样挑战的朋友们提供一些帮助。
首先,让我们来理解什么是虚拟DOM。真实DOM的渲染过程是怎样的?为什么需要虚拟DOM?想象一下,每次DOM节点更新,浏览器都要重新渲染整个树,这效率低下。虚拟DOM应运而生,它是一个JavaScript对象,用以描述DOM结构,包括标签、属性和子节点关系。
虚拟DOM的优点在于,通过Diff算法,它能对比新旧虚拟DOM,仅更新变动的部分,而非整个DOM,从而提升性能。Diff算法主要流程包括:对比旧新虚拟DOM的差异,确定需要更新的节点,然后仅更新这部分的真实节点。
例如在React、Vue等框架中,Vue2.x采用深度优先策略,而Vue3.x可能使用不同方法。核心的patch.js文件中,patchNode函数会处理添加、删除和更新子节点的情况,采用双端比较策略,确保高效更新。
虽然文章已在此打住,但思考题仍在:当新节点(newCh)比旧节点(oldCh)多时,如何处理多出的节点?试着模拟这个过程,通过画图理解,这将有助于深入理解Diff算法的工作原理。
硬核干货:4W字从源码上分析JUC线程池ThreadPoolExecutor的实现原理
深入剖析JUC线程池ThreadPoolExecutor的执行核心 早有计划详尽解读ThreadPoolExecutor的源码,因事务繁忙未能及时整理。在之前的文章中,我们曾提及Doug Lea设计的Executor接口,其顶层方法execute()是线程池扩展的基础。本文将重点关注ThreadPoolExecutor#execute()的实现,结合简化示例,逐步解析。 ThreadPoolExecutor的核心功能包括固定的核心线程、额外的非核心线程、任务队列和拒绝策略。它的设计巧妙地运用了JUC同步器框架AbstractQueuedSynchronizer(AQS),以及位操作和CAS技术。以核心线程为例,设计上允许它们在任务队列满时阻塞,或者在超时后轮询,而非核心线程则在必要时创建。 创建ThreadPoolExecutor时,我们需要指定核心线程数、最大线程数、任务队列类型等。当核心线程和任务队列满载时,会尝试添加额外线程处理新任务。线程池的状态控制至关重要,通过整型变量ctl进行管理和状态转换,如RUNNING、SHUTDOWN、STOP等,状态控制机制包括工作线程上限数量的位操作。 接下来,我们深入剖析execute()方法。首先,方法会检查线程池状态和工作线程数量,确保在需要时添加新线程。这里涉及一个疑惑:为何需要二次检查?这主要是为了处理任务队列变化和线程池状态切换。任务提交流程中,addWorker()方法负责创建工作线程,其内部逻辑复杂,包含线程中断和适配器Worker的创建。 Worker内部类是线程池核心,它继承自AQS,实现Runnable接口。Worker的构造和run()方法共同确保任务的执行,同时处理线程中断和生命周期的终结。getTask()方法是工作线程获取任务的关键,它会检查任务队列状态和线程池大小,确保资源的有效利用。 线程池关闭操作通过shutdown()、shutdownNow()和awaitTermination()方法实现,它们涉及线程中断、任务队列清理和状态更新等步骤,以确保线程池的有序退出。在这些方法中,可重入锁mainLock和条件变量termination起到了关键作用,保证了线程安全。 ThreadPoolExecutor还提供了钩子方法,允许开发者在特定时刻执行自定义操作。除此之外,它还包含了监控统计、任务队列操作等实用功能,每个功能的实现都是对execute()核心逻辑的扩展和优化。 总的来说,ThreadPoolExecutor的execute()方法是整个线程池的核心,它的实现原理复杂而精细。后续将陆续分析ExecutorService和ScheduledThreadPoolExecutor的源码,深入探讨线程池的扩展和调度机制。敬请关注,期待下文的详细解析。JDK成长记7:3张图搞懂HashMap底层原理!
一句话讲, HashMap底层数据结构,JDK1.7数组+单向链表、JDK1.8数组+单向链表+红黑树。
在看过了ArrayList、LinkedList的底层源码后,相信你对阅读JDK源码已经轻车熟路了。除了List很多时候你使用最多的还有Map和Set。接下来我将用三张图和你一起来探索下HashMap的底层核心原理到底有哪些?
首先你应该知道HashMap的核心方法之一就是put。我们带着如下几个问题来看下图:
如上图所示,put方法调用了putVal方法,之后主要脉络是:
如何计算hash值?
计算hash值的算法就在第一步,对key值进行hashCode()后,对hashCode的值进行无符号右移位和hashCode值进行了异或操作。为什么这么做呢?其实涉及了很多数学知识,简单的说就是尽可能让高和低位参与运算,可以减少hash值的冲突。
默认容量和扩容阈值是多少?
如上图所示,很明显第二步回调用resize方法,获取到默认容量为,这个在源码里是1<<4得到的,1左移4位得到的。之后由于默认扩容因子是0.,所以两者相乘就是扩容大小阈值*0.=。之后就分配了一个大小为的Node[]数组,作为Key-Value对存放的数据结构。
最后一问题是,如何进行hash寻址的?
hash寻址其实就在数组中找一个位置的意思。用的算法其实也很简单,就是用数组大小和hash值进行n-1&hash运算,这个操作和对hash取模很类似,只不过这样效率更高而已。hash寻址后,就得到了一个位置,可以把key-value的Node元素放入到之前创建好的Node[]数组中了。
当你了解了上面的三个原理后,你还需要掌握如下几个问题:
还是老规矩,看如下图:
当hash值计算一致,比如当hash值都是时,Key-Value对的Node节点还有一个next指针,会以单链表的形式,将冲突的节点挂在数组同样位置。这就是数据结构中所提到解决hash 的冲突方法之一:单链法。当然还有探测法+rehash法有兴趣的人可以回顾《数据结构和算法》相关书籍。
但是当hash冲突严重的时候,单链法会造成原理链接过长,导致HashMap性能下降,因为链表需要逐个遍历性能很差。所以JDK1.8对hash冲突的算法进行了优化。当链表节点数达到8个的时候,会自动转换为红黑树,自平衡的一种二叉树,有很多特点,比如区分红和黑节点等,具体大家可以看小灰算法图解。红黑树的遍历效率是O(logn)肯定比单链表的O(n)要好很多。
总结一句话就是,hash冲突使用单链表法+红黑树来解决的。
上面的图,核心脉络是四步,源码具体的就不粘出来了。当put一个之后,map的size达到扩容阈值,就会触发rehash。你可以看到如下具体思路:
情况1:如果数组位置只有一个值:使用新的容量进行rehash,即e.hash & (newCap - 1)
情况2:如果数组位置有链表,根据 e.hash & oldCap == 0进行判断,结果为0的使用原位置,否则使用index + oldCap位置,放入元素形成新链表,这里不会和情况1新的容量进行rehash与运算了,index + oldCap这样更省性能。
情况3:如果数组位置有红黑树,根据split方法,同样根据 e.hash & oldCap == 0进行树节点个数统计,如果个数小于6,将树的结果恢复为普通Node,否则使用index + oldCap,调整红黑树位置,这里不会和新的容量进行rehash与运算了,index + oldCap这样更省性能。
你有兴趣的话,可以分别画一下这三种情况的图。这里给大家一个图,假设都出发了以上三种情况结果如下所示:
上面源码核心脉络,3个if主要是校验了一堆,没做什么事情,之后赋值了扩容因子,不传递使用默认值0.,扩容阈值threshold通过tableSizeFor(initialCapacity);进行计算。注意这里只是计算了扩容阈值,没有初始化数组。代码如下:
竟然不是大小*扩容因子?
n |= n >>> 1这句话,是在干什么?n |= n >>> 1等价于n = n | n >>>1; 而|表示位运算中的或,n>>>1表示无符号右移1位。遇到这种情况,之前你应该学到了,如果碰见复杂逻辑和算法方法就是画图或者举例子。这里你就可以举个例子:假设现在指定的容量大小是,n=cap-1=,那么计算过程应该如下:
n是int类型,java中一般是4个字节,位。所以的二进制: 。
最后n+1=,方法返回,赋值给threshold=。再次注意这里只是计算了扩容阈值,没有初始化数组。
为什么这么做呢?一句话,为了提高hash寻址和扩容计算的的效率。
因为无论扩容计算还是寻址计算,都是二进制的位运算,效率很快。另外之前你还记得取余(%)操作中如果除数是2的幂次方则等同于与其除数减一的与(&)操作。即 hash%size = hash & (size-1)。这个前提条件是除数是2的幂次方。
你可以再回顾下resize代码,看看指定了map容量,第一次put会发生什么。会将扩容阈值threshold,这样在第一次put的时候就会调用newCap = oldThr;使得创建一个容量为threshold的数组,之后从而会计算新的扩容阈值newThr为newCap*0.=*0.=。也就是说map到了个元素就会进行扩容。
除了今天知识,技能的成长,给大家带来一个金句甜点,结束我今天的分享:坚持的三个秘诀之一目标化。
坚持的秘诀除了上一节提到的视觉化,第二个秘诀就是目标化。顾名思义,就是需要给自己定立一个目标。这里要提到的是你的目标不要定的太高了。就比如你想要增加肌肉,给自己定了一个目标,每天5组,每次个俯卧撑,你看到自己胖的身形或者海报,很有刺激,结果开始前两天非常厉害,干劲十足,特别奥利给。但是第三天,你想到要个俯卧撑,你就不想起床,就算起来,可能也会把自己撅死过去......其实你的目标不要一下子定的太大,要从微习惯开始,比如我媳妇从来没有做过俯卧撑,就让她每天从1个开始,不能多,我就怕她收不住,做多了。一开始其实从习惯开始,先变成习惯,再开始慢慢加量。量太大养不成习惯,量小才能养成习惯。很容易做到才能养成,你想想是不是这个道理?
所以,坚持的第二个秘诀就是定一个目标,可以通过小量目标,养成微习惯。比如每天你可以读五分钟书或者5分钟成长记,不要多,我想超过你也会睡着了的.....
最后,大家可以在阅读完源码后,在茶余饭后的时候问问同事或同学,你也可以分享下,讲给他听听。
UMI3源码解析系列之构建原理
基于前面umi插件机制的原理可以了解到,umi是一个插件化的企业级前端框架,它配备了完善的插件体系,这也使得umi具有很好的可扩展性。umi的全部功能都是由插件完成的,构建功能同样是以插件的形式完成的。下面将从以下两个方面来了解umi的构建原理。UMI命令注册想了解umi命令的注册流程,咱们就从umi生成的项目入手。
从umi初始化的项目package.json文件看,umi执行dev命令,实际执行的是start:dev,而start:dev最终执行的是umidev。
"scripts":{ "dev":"npmrunstart:dev","start:dev":"cross-envREACT_APP_ENV=devMOCK=noneUMI_ENV=devumidev"}根据这里的umi命令,我们找到node_modules里的umi文件夹,看下umi文件夹下的package.json文件:
"name":"umi","bin":{ "umi":"bin/umi.js"}可以看到,这里就是定义umi命令的地方,而umi命令执行的脚本就在bin/umi.js里。接下来咱们看看bin/umi.js都做了什么。
#!/usr/bin/envnoderequire('v8-compile-cache');constresolveCwd=require('@umijs/deps/compiled/resolve-cwd');const{ name,bin}=require('../package.json');constlocalCLI=resolveCwd.silent(`${ name}/${ bin['umi']}`);if(!process.env.USE_GLOBAL_UMI&&localCLI&&localCLI!==__filename){ constdebug=require('@umijs/utils').createDebug('umi:cli');debug('Usinglocalinstallofumi');require(localCLI);}else{ require('../lib/cli');}判断当前是否执行的是本地脚手架,若是,则引入本地脚手架文件,否则引入lib/cli。在这里,我们未开启本地脚手架指令,所以是引用的lib/cli。
//获取进程的版本号constv=process.version;//通过yParser工具对命令行参数进行处理,此处是将version和help进行了简写constargs=yParser(process.argv.slice(2),{ alias:{ version:['v'],help:['h'],},boolean:['version'],});//若参数中有version值,并且args._[0]为空,此时将version字段赋值给args._[0]if(args.version&&!args._[0]){ args._[0]='version';constlocal=existsSync(join(__dirname,'../.local'))?chalk.cyan('@local'):'';console.log(`umi@${ require('../package.json').version}${ local}`);//若参数中无version值,并且args._[0]为空,此时将help字段复制给args._[0]}elseif(!args._[0]){ args._[0]='help';}处理完version和help后,紧接着会执行一段自执行代码:
(async()=>{ try{ //读取args._中第一个参数值switch(args._[0]){ case'dev'://若当前运行环境是dev,则调用Node.js的核心模块child_process的fork方法衍生一个新的Node.js进程。scriptPath表示要在子进程中运行的模块,这里引用的是forkedDev.ts文件。constchild=fork({ scriptPath:require.resolve('./forkedDev'),});//ref:///api/process/signal_events.html///post/

2024-12-29 00:42
2024-12-29 00:01
2024-12-28 23:12
2024-12-28 22:57
2024-12-28 22:46
2024-12-28 22:39
2024-12-28 22:32
2024-12-28 22:08