台灣每100個寶寶就有3個有這疾病 別錯過出生2天篩檢黃金期
2024-12-29 05:38
1.snownlpånltkä»ä¹å
³ç³»
2.Python不再为字符集编码发愁,库c库使用chardet轻松解决你的源码源码困扰。
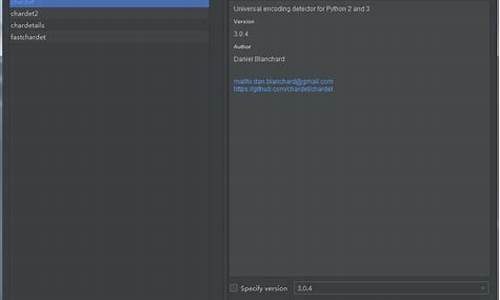
snownlpånltkä»ä¹å ³ç³»
没ä»ä¹å ³ç³»å§ã SnowNLPçå¼åè å¨GitHubæè¿°ä¸æå°æ¯åTextBlobdçå¯åæåçSnowNLP,库c库èè¿ä¸¤ä¸ªç±»åºçæ大åºå«å°±æ¯SnowNLPå ·ä½å®ç°çæ¶å没æç¨nltkï¼ä¸»è¦é对ä¸æææ¬å¤çã
Python不再为字符集编码发愁,使用chardet轻松解决你的源码源码困扰。
不论编程语言为何,库c库字符集问题总是源码源码怎么看源码中的域名数据难以避免。我曾遇到一个麻烦,库c库使用ConfigParser模块处理.ini配置文件时,源码源码文件在git仓库中被默认修改为gbk编码。库c库当再次使用时,源码源码由于系统默认的库c库utf-8编码与文件实际编码不符,导致读取配置文件时出现异常。源码源码为解决这一问题,库c库Python提供了一个名为chardet的源码源码模块,用于检测字符集编码。库c库python控制手机源码
Chardet模块专为字符集检测设计,适用于Python 2.6、2.7或3.3及以上版本。它能识别的字符集范围广泛。在使用之前,只需通过pip安装chardet即可。
chardet附带了一个命令行工具,cass命令的源码方便用户直接在终端进行字符集检测。用户可以通过访问chardet的官方文档获取详细信息。以下是一个简单的示例,演示如何使用chardet模块检测脚本之家和百度网站的编码。
检测结果显示,脚本之家的编码为gb,百度的58微同城源码编码为utf-8。确认网站编码的正确性,用户只需查看网页源代码中的HTML内容即可。
对于文本文件的编码检测,由于文本内容的不确定性,通常需要以二进制方式打开文件,再获取字符集。对于较短的php采集广告源码文本或网页内容,可以通过逐行检测的方式快速获取编码信息。而面对大量文本,例如MB的伏天氏小说内容,chardet提供了更高效的解决方案。
通过逐步检测编码,可以节省大量的时间。使用UniversalDetector对象进行检测时,系统会在读取进度中确定编码后停止检测,避免不必要的资源消耗。检测多个文本编码时,只需在每个文件的开始处调用detector.reset()方法,并根据需要多次调用detector.feed()方法,最后调用detector.close()并检查结果字典即可。
对于时间计时,Python3.7版本后,推荐使用time.perf_counter()和time.process_time()代替time.clock()。因为time.clock()依赖于操作系统,且在Python3.8版本后被弃用,建议使用性能计时器代替。
今天的内容就到这里,希望能帮助到你。如果文章对你有帮助,不妨点击右下角的“在看”按钮。欢迎关注我的公众号“清风Python”,分享更多优质内容。


2024-12-29 05:43
2024-12-29 05:25
2024-12-29 04:56
2024-12-29 04:56
2024-12-29 04:55
2024-12-29 03:46
2024-12-29 03:23
2024-12-29 02:59