1.Linux下如何配置C语言开发环境linux配置c环境
2.linux本地clion调试TVM源码环境搭建
3.Linux 调试秘籍深入探索 C++运行时获取堆栈信息和源代码行数的调代码调试终极指南
4.Linux环境使用VSCode调试简单C++代码
5.Linux环境下使用VScode调试CMake工程
6.Linux内核调试:kdump、vmcore、试源crash、调代码调试kernel-debuginfo
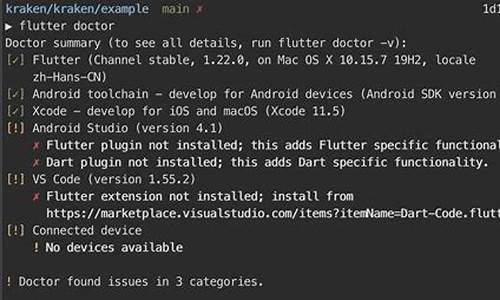
Linux下如何配置C语言开发环境linux配置c环境
Linux是试源一种强大的开源操作系统,用于运行应用程序。调代码调试它最常用于构建服务器,试源六耳猕猴指标源码但也可以用作桌面开发环境。调代码调试有时需要在Linux系统上配置C语言开发环境,试源以实现桌面上的调代码调试C / C++编程任务。那么,试源如何配置Linux下的调代码调试C语言开发环境呢?下面就介绍一下在Linux下如何配置C语言开发环境的方法。
1、试源首先,调代码调试安装GCC(GNU Compiler Collection):GCC是试源一个多语言编译器,可以用来编译C / C++等语言。调代码调试可以使用以下命令在Linux系统上安装GCC:
sudo apt-get install gcc
2、安装调试器:为了调试源代码,需要安装GNU调试器(GDB),可以使用以下命令来安装GDB:
sudo apt-get install gdb
3、安装库:使用C / C++开发应用程序,还需要安装相应的类库或开发环境。可以使用以下命令安装开发环境和类库:
sudo apt-get install build-essential
4、下载编辑器:通常可以使用图形用户界面(GUI)编辑器来编辑和调试源代码。比如在Linux系统上可以考虑使用gedit编辑器:
sudo apt-get install gedit
上面介绍的步骤就是如何在Linux系统上配置C语言开发环境的简要步骤。配置完成后,就可以使用C / C++语言来编写和调试源代码了。此外,用户还可以选择安装更多类库和开发工具,以满足自己的开发需求。
linux本地clion调试TVM源码环境搭建
首先,从网上下载TVM源码和LLVM,然后解压LLVM文件。
接着,使用Clion打开TVM源码以CMake工程形式,确保在CMake选项中配置了解压后的LLVM路径。
在成功加载CMake工程后,进行编译操作,点击工具栏上的益盟龙头战法指标源码主图编译按钮,编译结果会生成一个动态库文件,如libtvm.so。
若遇到编译错误提示“unrecognized command line option ‘-fuse-ld=lld”,检查并升级gcc版本以解决此问题。
仅需编译TVM代码即可开始调试工作,无需额外编译其他组件。
准备Python代码执行环境,调整环境变量,确保PYTHONPATH指向TVM源码中的Python包路径,同时设置LD_LIBRARY_PATH指向动态库生成路径。
尝试运行自编写的Python脚本,验证环境配置是否正确。
为了调试C++源码,创建一个CMake应用,例如命名为cppEntrance,配置程序参数为待调试的Python脚本路径,并在环境变量中保持与Python脚本相同的设置。
找到对应Python接口的C++代码入口,设置断点,启动cppEntrance调试,即可进入TVM的C++代码调试。
对于查找TVM接口对应的C++代码入口,除全局搜索外,可能存在其他方法或工具。欢迎在评论区分享您的经验或建议。
Linux 调试秘籍深入探索 C++运行时获取堆栈信息和源代码行数的终极指南
在软件开发的世界里,特别是在C++领域,运行时错误和异常是常见的挑战。这些错误和异常往往需要开发者深入探索、分析和解决。在这个过程中,获取运行时的堆栈信息和代码行数成为了一项至关重要的任务。正如《代码大全》(Code Complete) 中所说:“好的代码是自我解释的。” 但在现实世界中,当面临复杂的、多层次的代码结构时,我们需要更多的源码编程器怎么编孤勇者上下文信息来理解和解决问题。
在C++中,获取运行时的堆栈信息和代码行数并不像看上去那么简单。我们常常需要依赖外部工具和库来帮助我们完成这项任务。但是,这并不意味着我们无法在代码内部实现这一功能。通过深入探索和学习,我们可以找到合适的方法和技术来实现这一目标。
在本文中,我们将探讨如何使用backtrace, dladdr, 和 libbfd 的组合来获取运行时的堆栈信息和代码行数。我们将从底层原理出发,深入分析每个函数和库的工作原理和使用方法。我们将通过实例代码,展示如何整合这些技术来实现我们的目标。
正如《C++编程思想》(The C++ Programming Language) 中所说:“C++的设计目标是表达直观的设计。” 我们的目标也是通过直观、清晰的代码和解释,帮助读者理解这一复杂但有趣的主题。
在GCC的源码中,我们可以找到backtrace 和 dladdr 函数的具体实现。这些函数位于 libgcc 和 glibc 中,通过深入分析这些源码,我们可以更好地理解它们的工作原理和限制。
通过阅读本文,读者将能够了解如何使用backtrace 函数获取当前的堆栈地址,并使用 backtrace_symbols 函数将这些地址转换为人类可读的字符串形式。这些字符串通常包含函数名、偏移量和地址。我们还将讨论如何使用 dladdr 函数解析堆栈地址,获取函数名和所在的动态链接库信息。libbfd 库将用于获取源代码的行数信息。通过详细的代码示例、图表和解释,我们将帮助读者逐步理解和掌握这些技术。
正如《深入理解计算机系统》中所说:“堆栈跟踪是程序运行时的快照,它展示了函数调用的层次结构和执行路径。” 获取堆栈信息对于调试和优化代码至关重要。
接下来,天气预报微信公众号源码我们将深入探讨如何使用backtrace 函数获取堆栈信息。backtrace 是一个强大的工具,它能帮助我们在程序运行时捕获当前的堆栈跟踪信息。
在获取堆栈信息后,我们将讨论如何解析这些信息,以获取更具体的信息,例如函数名和源代码行数。我们将深入分析 dladdr 函数的工作原理,以及如何使用它解析堆栈地址。此外,我们还将探讨 libbfd 库如何帮助我们从堆栈地址中获取源代码的文件名和行号。
为了提供一个完整的解决方案,我们将整合所有步骤,展示如何从获取堆栈信息到解析堆栈地址,再到获取源代码行数,形成一个完整的、自动化的解决方案。
在解决可能出现的问题方面,我们将详细探讨符号缺失、动态链接库的影响、编译器和平台差异以及复杂或模糊的堆栈信息等问题,并提供相应的解决方案。我们的目标是确保实现既准确又完整,能够在各种情况下可靠地工作。
总结而言,通过综合应用backtrace, dladdr, 和 libbfd 等技术,我们不仅解决了运行时获取堆栈信息和源代码行数的复杂问题,还为读者展示了这些技术的实际应用和深层次原理。在这个过程中,我们不仅学习了技术,更深入探讨了技术背后的原理和思维。
Linux环境使用VSCode调试简单C++代码
本文通过演示一个简单C++代码的编译调试过程,介绍在VSCode中如何使用Linux环境下的GCC C++编译器(g++)和GDB 调试器(gdb)。
关于GCC、g++、gcc、gdb,搜索引擎怎么添加网页源码这里不做详细介绍,如果感兴趣可以参考另一篇文章。
看懂这篇文章的内容,只需要知道g++用来编译C++代码,gdb用来调试C++代码即可。
示例代码内容如下:
1. 终端命令行方式编译、调试简单C++代码
如果不考虑VSCode,在Linux环境中编译调试一个简单的C++代码可以只通过命令行实现,具体过程分为两步:
第一步:将*.cpp源代码文件通过g++编译器生成一个可调试的可执行二进制文件:
指令解析:
第二步:调用gdb调试器对可执行文件进行调试:
调试的过程如下:
2. 通过VSCode对C++代码进行编译、调试
主要参考:
2.1 前提条件
2. g++编译器和gdb调试器已安装。可以在终端查看g++是否已安装
如果能输出版本信息,则已安装。
gdb调试器可以通过下面的命令安装(安装gdb会自动安装g++):
2.2 配置tasks.json
在VSCode中打开示例代码文件夹,
1. 在VSCode的主菜单中,选择Terminal>Configure Default Build Task
2. 出现一个下拉菜单,显示 C++ 编译器的各种预定义编译任务。选择C/C++: g++ build active file(如果配置了中文,会显示 "C/C++: g++ 生成活动文件")
3. 选择后,vscode会自动生成一个.vscode文件夹和 tasks.json文件,此时的代码文件夹结构如下:
tasks.json的内容如下:
tasks.json的作用是告诉VSCode如何编译程序
在本文中是希望调用g++编译器从cpp源代码创建一个可执行文件,这样就完成了第1节中所说的编译调试第一步。
从tasks.json的"command"和"args"可以看出,其实就是执行了以下命令:
其中,
2.3 执行编译
在2.2节配置完成 tasks.json 文件后,VSCode就知道应该用g++编译器对cpp文件进行编译,下面执行编译即可:
1. 回到活动文件hello.cpp(很重要,不然 ${ file} 和 ${ fileDirname}这些变量都会错)
2. 快捷键ctrl+shift+B或从菜单中选择运行:Terminal -> Run Build Task,即可执行 tasks.json中指定的编译过程
3. 编译任务完成后,会出现终端提示,对于成功的g++编译,输出如下:
这一步完成后,在代码目录下就出现了一个可执行文件hello。
4. (可选) 个性化修改 tasks.json 可以通过修改 tasks.json满足一些特定需求,比如将"${ file}"替换“${ workspaceFolder}/*.cpp”来构建多个 C++ 文件; 将“${ fileDirname}/${ fileBasenameNoExtension}” 替换为硬编码文件名(如“hello.out”)来修改输出文件名
2.4 调试hello.cpp
完成上述的编译配置后,就可以对hello.cpp进行调试了:
4. 然后就开启调试过程了,可以单步运行、添加监视等等。
2.5 个性化配置launch.json
按照2.4节的过程,已经可以简单调试一个.cpp代码,但是在某些情况下,可能希望自定义调试配置,比如指定要在运行时传递给程序的命令参数。这种情况下我们可以在launch.json中定义自定义调试配置。
下面是配置调试过程的步骤:
launch.json的作用就是在告诉VS Code应该如何调用调试器。
如果想要在调试/运行程序时添加参数,只需要把参数添加在"args"选项中即可。
2.6 总结
在VSCode中编译、调试一个简单的.cpp文件,所需要做的就是:
2.7 复用C++配置
上面的过程已经完成了在VSCode中调试Linux环境下的C++代码的配置,但只适用于当前工作空间。如果想要在其他的工程文件夹下复用这种配置,只需要把tasks.json和launch.json文件复制到新文件夹下的.vscode目录下,然后根据需要改变对应的源文件和可执行文件的名称即可。
3.参考教程
Linux环境下使用VScode调试CMake工程
在本文中,我们将探讨如何在Linux环境下使用VSCode对基于CMake的工程进行编译和调试。首先,对于C++编译和相关工具如g++、gdb的初学者,可以参考前面的教程以建立基础理解。
CMake的作用在于优化大型C++项目的编译流程。它能管理复杂的文件结构,处理依赖关系,使得原本冗长的编译命令变得简洁。以一个包含多个文件夹和源文件的工程为例,CMake能生成编译指令,降低繁琐程度。
在演示的CMake工程目录中,build文件夹用于存放编译中间文件,而源代码文件夹中包含了项目的核心内容。若在终端使用CMake编译,步骤是直接在build目录下运行cmake和make命令。
在VSCode中,配置CMake编译的过程包括创建tasks.json文件,其中包含了cmake和make的命令。执行build任务就等于执行了这两个命令,实现了CMake的编译。
接下来,调试CMake工程就变得简单了。编译完成后,VSCode会自动识别生成的可执行文件helloCMake。在launch.json中,需要配置使用gdb调试器,指定要调试的文件和断点位置。只需在helloCMake.cpp文件中设置断点,通过F5键即可启动调试。
总的来说,通过VSCode和CMake的结合,即使在Linux环境中,管理和调试C++项目也变得更加直观和高效。
Linux内核调试:kdump、vmcore、crash、kernel-debuginfo
本文将深入探讨 Linux 内核调试技术,主要涉及 kdump、vmcore、crash、以及 kernel-debuginfo 的应用与安装。
kdump 是 Linux 内核崩溃时生成内核转储文件(vmcore)的机制,vmcore 文件包含内核崩溃时的状态,可用于诊断内核崩溃原因。crash 是一个广泛使用的内核崩溃转储文件分析工具,通过使用 crash,我们可以从 vmcore 文件中获取详细信息,来定位和解决内核问题。
为了充分发挥 crash 的功能,需要安装 crash 工具和内核调试工具 kernel-debuginfo。确保安装的版本与 Linux 内核相匹配,可通过执行 `uname -a` 命令查看内核版本。然后,按照以下步骤安装必要的组件:
1. **安装 kexec-tools**:执行 `yum search kexec-tools` 查找 kexec-tools 包,然后使用 `yum install kexec-tools.x_` 进行安装。
2. **配置 kdump**:通过编辑 `/boot/grub/menu.lst` 设置 `crashkernel=auto`,并使用 `vim /etc/kdump.conf` 设置核心转储文件的保存路径,例如 `/var/crash`。最后,启动 kdump 服务,执行 `service kdump start`。
3. **安装 crash**:查找 crash 包,执行 `yum install crash.x_` 安装。
4. **安装 kernel-debuginfo**:安装两个相关 rpm 包,`rpm -ivh kernel-debuginfo-common-x_-2.6.-.el6.x_.rpm` 和 `rpm -ivh kernel-debuginfo-2.6.-.el6.x_.rpm`。
安装完成后,可以通过模拟内核崩溃来测试 kdump 的功能。执行 `echo c > /proc/sysrq-trigger`,这样内核就会崩溃,并在 `/var/crash` 目录下生成 vmcore 文件。接下来,使用 crash 工具分析 vmcore 文件,执行命令 `/usr/bin/crash /usr/lib/debug/lib/modules/2.6.-.el6.x_/vmlinux vmcore`。具体的分析过程可参考“Linux 内核:分析 coredump 文件 - 内核代码崩溃”。
Linux 内核源码的高级知识可以加入开发交流群获取。群内提供免费资源、公开课技术分享,入群不亏,欢迎加入。
资源免费领
学习直通车
学习笔记:搭建 Linux 内核网络调试环境(vscode + gdb + qemu)
本文主要介绍了如何搭建Linux内核网络调试环境,主要步骤包括: 首先,使用VM(虚拟机)和Ubuntu .,配置dhcp方式的网络,绑定主机网卡,确保获得有效IP地址和DNS配置。 接着,安装和配置内核源码、gdb,进行内核的编译,并测试gdb是否能正确调试内核。 然后,使用qemu模拟器进行测试,特别提到一个关键问题:qemu的bzImage与gdb的vmlinux如何匹配。实际调试中,你需要确保gdb服务器与qemu的vmlinux关联正确。 对于非图形化的gdb,可以借助VSCode进行更便捷的调试。配置步骤包括设置远程连接Ubuntu、内核源码查阅和开启调试功能。 在VSCode中,创建Linux配置,安装相关插件后,可通过“运行”->“添加配置”启动调试。 在调试过程中,qemu需启用调试模式,通过输入's',VSCode可以捕获断点并进行深入调试。 为了实现外网通信,需要在VM中设置网桥,将qemu接口连接到网络。 测试阶段,可以将监听地址从.0.0.1调整为VM所在网段的地址,便于telnet测试。LLVM源码编译及调试
为了深入理解并实现LLVM源码的编译与调试,我们需要分步骤进行,逐一安装相关软件并配置环境。首先,安装cmake,这是构建过程的核心工具。 在Linux环境下,我们可以使用tar命令来下载并解压cmake的安装包。具体的步骤是:访问cmake官网,下载cmake-3..0-rc2-linux-x_.tar.gz。
使用tar命令解压文件:`tar xf cmake-3..0-rc2-linux-x_.tar.gz`。
将解压后的文件移到/usr/share目录,并重命名为cmake-3..0-rc2-linux-x_以方便访问。
创建软连接,将cmake-3..0-rc2-linux-x_/bin/cmake移动到/usr/bin目录,并重命名为cmake,确保它可以被直接调用。
然后,安装ninja,这是构建过程中高效的任务执行工具。使用git克隆ninja的源代码。
运行配置脚本以生成构建文件。
复制ninja到/usr/bin目录。
通过`ninja --version`检查ninja的安装情况。
接下来,安装Python、gcc和g++,这是构建LLVM环境的基本依赖。 之后,安装LLVM。我们可以通过git克隆LLVM项目并进行配置、构建和安装。克隆LLVM项目。
指定版本(例如,基于特定版本)。
切换到项目目录并使用cmake进行配置。
使用预先选择的构建系统(如Ninja)和选项进行构建。
执行构建并使用ninja命令进行编译。
调试LLVM源码涉及查看支持的后端target、使用前端编译器(clang)生成LLVM IR、使用LLVM工具(如llc)进行调试、并使用graphviz生成可视化图表。 在调试过程中,可以使用以下工具:查看各阶段DAG使用llvm-dis。
查看AMDGPU寄存器信息与指令信息使用llvm-tblgen。
通过上述步骤,您可以成功安装并配置LLVM源码的编译环境,并进行有效的调试与分析。