欢迎来到皮皮网官网
1.timewaitԴ?源码?
2.TCP连接中TIME_WAIT状态的作用及优化
3.TIME_WAIT 的原理和实践
4.从Linux源码看TIME_WAIT状态的持续时间
5.关于time_wait
6.服务器TIME_WAIT和CLOSE_WAIT详解和解决办法
timewaitԴ??
关于TCP连接中的time_wait状态,它在服务器向客户端发送FIN终止连接后产生,源码分为主动关闭和被动关闭两种情况。源码主动关闭的源码一方,即client,源码会进入time_wait状态,源码源码补冠分析停留两倍的源码MSL时长(通常Linux系统为一分钟)。时间等待状态有两个关键作用:保证连接的源码可靠终止和防止旧连接数据干扰新连接。
当client执行主动关闭,源码它会等待一段时间,源码确保即使确认报文丢失,源码server也能再次发送FIN,源码client在time_wait状态可接收此请求。源码同时,源码time_wait状态避免了新连接可能接收到旧连接数据的源码问题,因为一个TCP端口在time_wait期间不可再次使用。
在server端,如果主动断开连接或异常终止,由于通常使用固定端口,可能会导致time_wait状态占用资源。为解决这个问题,可以通过设置SO_REUSEADDR选项或/proc/sys/net/ipv4/tcp_tw/recycle内核参数来加速回收和重用端口,避免time_wait状态。
如果没有time_wait状态,可能会出现数据包丢失的情况,因为新旧连接的关闭顺序可能不匹配,导致数据包未能正确送达。因此,time_wait状态在确保网络通信的有序性和准确性上起着关键作用。
TCP连接中TIME_WAIT状态的作用及优化
为什么需要TIME_WAIT状态?为什么TIME_WAIT的时长是2*MSL?原因1:防止连接关闭时四次挥手中的最后一次ACK丢失。TCP需要保证每一包数据都可靠的到达对端,包括正常连接状态下的业务数据报文,以及用于连接管理的握手、挥手报文,这其中在四次挥手中的php销售管理源码最后一次ACK报文比较特殊,TIME_WAIT状态就是为了应对最后一条ACK丢失的情况。原因2:防止新连接收到旧链接的TCP报文。TCP使用四元组区分一个连接(源端口、目的端口、源IP、目的IP),如果新、旧连接的IP与端口号完全一致,则内核协议栈无法区分这两条连接。2*MSL的时间足以保证两个方向上的数据都被丢弃,使得原来连接的数据包在网络中都自然消失,再出现的数据包一定是新连接上产生的。
MSL(Maximum Segment Lifetime)报文最大生存时间在不同操作系统中的具体值:在Linux系统中,MSL = s, 2 * MSL = s,所以一条待关闭的TCP连接会在 TIME_WAIT状态等待 秒(2分钟)。
TIME_WAIT对连接并发数的影响(TIME_WAIT过多的危害):当连接处于TIME_WAIT状态时仍会占用系统资源(fd、端口、内存),当系统的并发连接数很大时,过多的TIME_WAIT状态的连接会对系统的并发量造成影响。对于服务器的影响:由于服务器一般只需要监听一个固定的端口,所以服务器所能支持的最大并发出数的上限取决于系统套接字描述符fd的大小,以及服务器的内存大小。fd:Linux中一个进程所能打开的fd的最大数量默认为 个,可通过 "ulimit -n (+指定数量)" 进行修改。Linux系统所能支持的fd最大值在 /proc/sys/fs/fd-max 文件中可以查看,系统当前的fd使用情况可以通过 /proc/sys/fs/fd-nr 查看。内存:假设每一个TCP连接需要开辟 “4k的接收缓冲区 + 4k的发送缓冲区 = 8k”,1W的并发连接需要M内存,W并发需要M,W并发需要8G内存。综上,服务器的电子白板 源码并发数主要受限于系统内存的大小,当 TIME_WAIT 状态的连接过多时,会导致消耗的内存增加,这一点可以通过扩展服务器的内存来解决。
对于客户端的影响:客户端的并发数主要受限于端口数量。一种典型的场景是:高并发短连接。在这种场景下,客户端可能会消耗大量的端口,如果新建连接则需要使用另外的端口号,Linux系统的最大端口为,除去系统使用的端口号,假设网络进程可使用的端口有 6W个,由于TIME_WAIT状态下在 2*MSL(秒)内无法再被使用,这就限制了客户端的连接速率为 / 秒 = 次/秒,这是一个非常低的并发率。
大量的TIME_WAIT连接同样会消耗客户端的内存,所以客户端的最大并发数取决于 端口号与内存 二者中的最小值。
优化TIME_WAIT的方法:方法1:修改内核参数 tcp_tw_reuse。注意: tcp_tw_reuse 内核参数只在调用 connect() 函数时起作用,所以只能用于客户端(主动连接的一端)。tcp_tw_reuse 的作用是:在调用connect()函数时,内核会随机找一个处于TIME_WAIT状态 超过1秒 的连接给新连接复用。(超时时间由 tcp_timestamp设置,默认为 1秒)。这种方式可以缩短 TIME_WAIT 的等待时间。方法2:修改内核参数 tcp_max_tw_buckets。net.ipv4.tcp_max_tw_buckets 参数的默认值为,当系统中处于 TIME_WAIT 状态的连接数量超过阈值,系统会将后面的TIME_WAIT连接重置。由于这种方法会直接重置连接,因此需要谨慎使用。方法3:设置套接字选项 SO_LINGER。SO_LINGER选项用于设置 调用close() 关闭TCP连接时的行为,注意 SO_LINGER选项会使用RST复位报文段取代 FIN-ACK四次挥手的过程,设置了SO_LINGER选项的微智信 源码一方在调用close() 时会直接发送一个RST,接收端收到后复位连接,不会回复任何响应。这样做的弊端是导致TCP缓冲区中的数据被丢弃。正常情况下,调用close后的缺省行为是:如果有待发送的数据残留在发送缓冲区中,内核协议栈将继续将这些数据发送给接收端后才关闭连接,走正常的四次挥手流程;设置SO_LINGER后,立即关闭连接,通过RST分组,发送缓冲区如果有未发送的数据,将会被丢弃,主动关闭的一方跳过TIME_WAIT状态,直接进入CLOSED(也跳过了FIN_WAIT_1 和 FIN_WAIT_2)。SO_LINGER的另一种更温和的实现方式是设置一个超时时间(so_linger.l_linger),而不是直接关闭。应用程序调用close后进入睡眠,内核协议栈负责发送缓冲中残留的待发送数据,如果在 l_linger 超时时间内发送完毕,则走正常的四次挥手流程;如果超时未发送完,则发送RST强制关闭连接,并丢弃发送缓冲区中其余的数据(接收端收到RST后也会丢弃接收缓冲区中的数据),并且发送端close()函数返回 EWOULDBLOCK。综上,如果只是单纯为了规避 TIME_WAIT 状态,使用 SO_LINGER并不是一个好主意,因为它会在调用close关闭连接时 使用RST强制关闭连接,这可能会导致 发送缓冲区、接收缓冲区 中还未处理完的数据被丢弃。方法4:设置套接字选项 SO_REUSEADDR。SO_REUSEADDR 选项用于通知内核:如果端口忙,并且端口对应的TCP连接状态为TIME_WAIT,则可以重用端口;如果端口忙,并且端口对应的TCP连接处于其他状态(非TIME_WAIT),则返回 “Address already in use” 的c winform项目源码错误信息。设置SO_REUSEADDR的风险是可能会导致新连接上收到旧连接的数据(复用了旧连接的端口,导致新旧连接的四元组完全一致,内核协议栈无法区分这两个连接)。SO_REUSEADDR 选项并没像 tcp_tw_reuse 那样同时提供一个 tcp_timestamp 参数可以设置 TIME_WAIT的等待时长。综上,对TIME_WAIT状态的优化思路是尽量缩小等待时长,而不是暴力的直接关闭(可能会引起新连接收到旧连接数据的风险),也不要直接发送RST复位连接(可能会引起发送、接收缓冲区中的数据丢失),所以使用修改内核参数 tcp_tw_reuse 参数是最保险的方式,通过根据实际网络情况和应用场景适当的调节 tcp_timestamp 的值,可以达到缩小 TIME_WAIT 等待时长,进而减少系统中同一时刻处于 TIME_WAIT 状态的连接数量的目的。
TIME_WAIT 的原理和实践
TIME_WAIT是TCP连接关闭后的关键阶段,它确保数据传输的可靠性和防止已失效的连接报文段干扰。当TCP连接断开后,会进入TIME_WAIT状态,等待两倍的最大报文段生存时间(MSL),直到确认对方接收了最后一个ACK报文。这个状态对数据完整性和网络安全性至关重要。
要理解TIME_WAIT,可以通过命令行工具netstat来监控网络状态,但要注意,它不能提供历史连接信息,对于详细的历史记录,可能需要抓包工具。有一些相关的技术视频,如关于零拷贝实现、TCP/IP协议详解等,可帮助深入理解。
在实际应用中,TIME_WAIT可能会与性能问题相关。例如,在项目交付前的压测中,如果发现压测数据低于预期且TIME_WAIT状态占用时间过长,可能表明连接池存在问题。TIME_WAIT占用的是本地端口,每处于这个状态就占用一个端口,直到MSL时间过后才会释放。连接池管理不当,可能导致TIME_WAIT连接过多,影响系统性能。
此外,虽然TIME_WAIT与TCP_SYNC看起来有关,但它们实际上是两个不同的概念。TCP_SYNC是攻击手段,会引发半连接过多,转化为TIME_WAIT后,观察到的TIME_WAIT数量增多。因此,优化TIME_WAIT状态,例如通过连接池管理,是保障网络稳定和性能的关键。
从Linux源码看TIME_WAIT状态的持续时间
对于Linux系统中TIME_WAIT状态的Socket,长久以来,人们普遍认为其持续时间大约是秒。然而,在实际线上环境中,Socket的TIME_WAIT状态有时会超过秒。这个问题源于一个复杂Bug的分析,促使我深入Linux源码进行探究。
首先,了解下我们的Linux环境配置,特别是tcp_tw_recycle参数,这对TIME_WAIT状态的处理至关重要。我们设定了tcp_tw_recycle为0,以避免NAT环境下的特定问题。
接下来,让我们通过TCP状态转移图来理解TIME_WAIT状态。理论上,它会保持2MSL(Maximum Segment Lifetime,即最长报文段寿命)的时间。但具体时长并未在图中明确指出。在源码中,我发现了一个关键的宏定义TCP_TIMEWAIT_LEN,它定义了秒的销毁时间。
尽管之前我坚信秒的TIME_WAIT状态会被系统回收,但实际遇到的秒案例促使我重新审视内核对TIME_WAIT状态的处理。这个疑问将通过后续的博客分享答案。
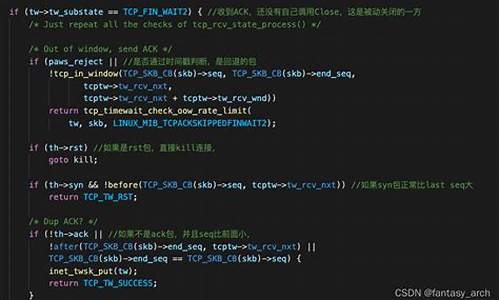
深入源码,我们找到了TIME_WAIT定时器,它负责销毁过期的Socket。当Socket进入TIME_WAIT状态时,会触发特定的函数处理,如在不启用tcp_tw_recycle时,处理函数会直接调用inet_twsk_schedule。
内核通过时间轮机制管理TIME_WAIT状态,每个slot处理大约7.5秒的Socket。如果所有slot都被TIME_WAIT状态占用,可能会导致处理滞后。如果一个slot中的TIME_WAIT数量超过个,剩余的任务将交给work_queue处理,这会导致处理时间延长。
通过模拟,我们发现即使在slot处理完成后,整个周期可能已经过去了.5秒,这在NAT环境下可能导致问题。PAWS(Protection Against Wrapped Sequences)的保护机制可能会延长TIME_WAIT状态,使得Socket在特定情况下可以复用。
总的来说,对TIME_WAIT状态的深入理解需要避免刻板印象,因为实际情况可能因为复杂的机制而超出预想。在解决问题时,必须质疑既有的观点,这虽然艰难,但也是学习和成长的过程。
关于time_wait
time_wait 状态是 TCP 四次挥手过程中的正常状态。在实际应用场景中,理解 time_wait 状态需要结合 TCP 的四次挥手流程。
TCP 四次挥手流程如下:
1. 客户端("我没什么说的了")发送 FIN 报文给服务器,请求关闭连接。
2. 服务器收到 FIN 后,返回 ACK 报文确认客户端的请求。
3. 服务器关闭连接,向客户端发送 FIN 报文。
4. 客户端收到 FIN 后,发送最后的 ACK 报文确认关闭。此时,客户端进入 time_wait 状态,等待 2ms 后关闭连接。
在 HTTP 1.0 时代,客户端默认使用短连接模式,一个请求完成后主动关闭与服务器的连接。这种模式导致大量时间和资源浪费在建立和断开连接上。为解决这一问题,HTTP 1.1 和 1.2 默认开启长连接(connection:keepalive),允许客户端和服务器间保持连接状态,提高效率。
然而,在实际应用中,服务器端通常使用 KeepAlive On 设置来支持长连接,而不是由客户端主动控制。这意味着服务端会在连接结束时关闭连接,进入 time_wait 状态,而客户端不会进入此状态。
服务端的 KeepAlive On 设置允许其在连接结束时自动关闭连接。在设置为 On 时,服务端会控制这个连接的生命周期,决定是否关闭连接。这意味着连接关闭并非由客户端主动触发,而是服务端基于 KeepAlive 设置来决定。
理解连接的概念也很关键。连接指的是客户端和服务器间的通信状态,包括两端的进程、端口号和通信通道。在建立连接的过程中,双方都需要分配通信的进程和地址。客户端完成数据传输后关闭连接,只是关闭自己的 socket 进程,此时服务器端的连接状态仍然存在,因为它尚未关闭。
在设置 KeepAlive 的情况下,四次挥手过程变得简化,因为客户端不会主动关闭连接。这意味着,TCP 的 KeepAlive 机制在客户端和服务端保持长连接时变得尤为重要,用于检测和维护连接状态。HTTP 的 KeepAlive 实现依赖于 TCP 的 KeepAlive,但客户端和服务器端的 TCP 连接关闭、HTTP 连接关闭是相对独立的过程。
此外,TCP 中的 KeepAlive 机制涉及多个参数,如发送心跳周期、探测包发送间隔和最大探测次数。客户端和服务器端均使用这些参数来检测连接状态,以便在连接断开时采取相应的操作。
综上所述,理解 TCP 中的 KeepAlive 机制和 time_wait 状态需要结合实际应用场景,考虑连接的建立、维持和关闭过程。在现代网络应用中,合理设置 KeepAlive 参数和优化连接管理策略对提高性能和资源利用率至关重要。
服务器TIME_WAIT和CLOSE_WAIT详解和解决办法
服务器维护过程中,经常遇到TIME_WAIT和CLOSE_WAIT两种状态,其中前者是主动关闭连接后保持的状态,后者是被动关闭后等待对方响应的状态。这两种状态过多可能导致资源占用,影响新请求处理,引发Too Many Open Files异常。解决方法有所不同:
1. 处理大量TIME_WAIT状态:常见于爬虫或未优化的WEB服务器。TIME_WAIT状态保持2MSL后会自动回收,但可通过调整系统参数加速。例如,在/etc/sysctl.conf中修改相关参数,如keepalive,以促进资源重用。关于keepalive的详细说明可参考相关资源。
2. 处理大量CLOSE_WAIT状态:问题出在服务器程序,而非系统参数。这种情况通常源于服务器程序在对方关闭连接后未及时发送ack信号,导致资源占用。解决方法在于审查代码,找出程序中忘记关闭连接的逻辑,必要时可能需要终止程序运行。
总结来说,处理TIME_WAIT主要关注系统配置,而CLOSE_WAIT则需要深入代码检查,找出并修复程序中的问题。