1.javaå¹è®ä¸»è¦å¦ä»ä¹ï¼
2.Elasticsearch7.8.0集成IK分词器改源码实现MySql5.7.2实现动态词库实时更新
3.如何读取elasticsearch的分词分词分词索引信息
4.java.lang.Error问题怎样解决?
5.goè¯è¨unresolved type string
javaå¹è®ä¸»è¦å¦ä»ä¹ï¼
åè¿æ ·çé®é¢ï¼æå·²ç»åçäºå¾å¤æ¬¡ï¼ç°å¨å¾å¤æ°æï¼ç¹å«æ¯ååå ¥è¡æ³å¦javaçåå¦ï¼ä¸ç¥é该ä»åªéå ¥æï¼ææ¯å¨æé½è¯¾å·¥åºå¦javaå ¥çè¡ï¼ç°å¨å·²åæèå¸æºï¼ææ´çäºä¸äºjavaçç¥è¯ç¹ï¼ä¸å ±å为å 个é¶æ®µï¼ä¸ªæè½ç¹ï¼ç¬¬ä¸é¶æ®µã第äºé¶æ®µã第ä¸é¶æ®µã第åé¶æ®µæ¯å¿ é¡»è¦ææ¡çï¼å¾å¤æºæ忽æ 人ï¼å°±åªå¦å°ç¬¬åé¶æ®µï¼ç¬¬äºé¶æ®µå第å é¶æ®µå°±æ¯é«èªãé«èçä¿éï¼å°±è¯´è¯´æ³é«èªå¿ é¡»å¾æåé¢ä¸¤ä¸ªé¶æ®µçç»ææ¡äºï¼èéï¼è§å¾åéé纳ä¸åã第ä¸é¶æ®µï¼javaåºæ¬åä¿®ç¼
1. 认è¯è®¡ç®æºç¡¬ä»¶
2. 计ç®æºç»æåç
3. 计ç®æºè½¯ä»¶ç¥è¯
4. 计ç®æºç½ç»ç¥è¯
5. 常ç¨ç½ç»åºç¨æä½
6. 认è¯è®¡ç®æºç æ¯
7. é»è¾è®ç»
8. åè¯Java
9. åéåæ°æ®ç±»å
. éæ©ç»æ
. 循ç¯ç»æfor
. 循ç¯ç»ædo-while
. 循ç¯ç»æwhile
. å¤é循ç¯åç¨åºè°è¯
. 循ç¯è¿é¶
. ä¸ç»´æ°ç»åç»å ¸åºç¨
. äºç»´æ°ç»
. 认è¯ç±»ä¸å¯¹è±¡
. æ¹æ³åæ¹æ³éè½½
. å°è£ ä¸ç»§æ¿
. æ¹æ³éåä¸å¤æ
. 项ç®å®æ-汽车ç§èµç³»ç»
. æ½è±¡ç±»åæ¥å£
. å¼å¸¸
. 项ç®å®æ-QuickHit
. Java ä¸çéåç±»å
. List éå
. Set éå
. HashMap éå
. Iterator
. Collections ç®æ³ç±»å常ç¨æ¹æ³
. enum
. å è£ ç±»åè£ ç®±æç®±
. StringãStringBuffer 类常ç¨æ¹æ³æä½å符串
. DateãCalendar
. Math 类常ç¨æ¹æ³
. IO/NIO
. åèè¾å ¥æµ(InputStreamãFileInputStreamãBufferedInputStream)
. åèè¾åºæµ(OutputStreamãFileOutputStreamãBufferedOutputStream)
. å符è¾å ¥æµ(ReaderãInputStreamReaderãFileReader BufferedReader)
. åèè¾åºæµ(WriterãOutputStreamWriterãFileWriterãBufferedWriter)
. æ件å¤å¶
. SerializeãDeserialize
. èåºæååï¼å象éæ¶é´ç®¡çä¸ç²¾å管ç
. å¤çº¿ç¨(ThreadãRunnable)
. Thread LifeCycle
. 线ç¨çè°åº¦
. 线ç¨çåæ¥åæ»é
. Thread Pool
. èåºæååï¼å¢éåä½
. Socket(TCPãUDP)
. XML æ¦å¿µãä¼å¿ãè§è
. XML ä¸ç¹æ®å符çå¤ç
. 使ç¨DOM 读åãæ·»å ãå é¤ã解æ XML æ°æ®
第äºé¶æ®µï¼javawebå¼å
. æ建åé ç½®MySQL æ°æ®åº
. æ°æ®åºå¢ãå ãæ¥ãæ¹è¯å¥
. äºå¡
. è§å¾
. æ°æ®åºå¤ä»½ä¸æ¢å¤
. æ°æ®åºç¨æ·ç®¡ç
. æ°æ®åºè®¾è®¡
. 项ç®å®æ-é¶è¡ATM åå款æºç³»ç»
. èµ°è¿ HTML åCSS
. åè¡¨è¡¨æ ¼å表åç¾å
. CSS é«çº§æä½
. Bootstrap
. CSS ç»ä»¶
. JavaScript é¢å对象
. JavaScript å¤æã循ç¯
. JavaScript éå
. JavaScript è¯æ³
. Bootstrap 综åæ¡ä¾
. HTML5ãCSS3
. jQuery åºç¡
. jQuery åºæ¬æä½
. jQuery äºä»¶ä¸ç¹æ
. jQuery Ajax
. jQuery æ件
. æ建Web ç¯å¢åè¯JSP
. JSP ä¹å¤§å 置对象
. JSP å®ç°æ°æ®ä¼ éåä¿å
. JDBC
. åä¾æ¨¡å¼ãå·¥å模å¼
. MVCãä¸å±æ¨¡å¼
. Commons-fileuploadãCKEditor
. å页æ¥è¯¢
. EL ä¸ JSTL
. Servlet ä¸Filter
. Listener ä¸MVC
. Ajax ä¸ jQuery
. jQuery çAjax 交äºæ©å±
. 项ç®å®æâ使ç¨Ajax ææ¯æ¹è¿æ°é»åå¸ç³»ç»
. åå°
. Linux ç³»ç»çå®è£
. å¨Linux ä¸ç®¡çç®å½åæ件
. å¨Linux ä¸ç®¡çç¨æ·åæé
. å¨Linux æå¡å¨ç¯å¢ä¸å®è£ 软件åé¨ç½²é¡¹ç®
. èåºæååï¼èåºæ²é
第ä¸é¶æ®µï¼ ä¼ä¸çº§æ¡æ¶å¼å
. MyBatis ç¯å¢æ建
. SQL æ å°æ件
. å¨æSQL
. MyBatis æ¡æ¶åç
. Spring IOC
. æé æ³¨å ¥ãä¾èµæ³¨å ¥ã注解
. Spring æ´åMyBatis(SqlSessionTemplateãMapperFactoryBeanãäºå¡
å¤ç)
. Spring æ°æ®æº(å±æ§æ件ãJNDI)ãBean ä½ç¨å
. Spring æ¡æ¶çè¿è¡åç
. SpringMVC ä½ç³»æ¦å¿µ
. SpringMVC ä¹æ°æ®ç»å®ãæ°æ®æéªã
. SpringMVC ä¹è§å¾åè§å¾è§£æ
. SpringMVC ä¹æ件ä¸ä¼ ãæ¬å°å解æ
. SpringMVC ä¹éæèµæºå¤çã请æ±æ¦æªå¨ãå¼å¸¸å¤ç
. Oracle æ°æ®åºç¯å¢æ建ãå®è£
. Oracle æ°æ®åº SQLãå页ãå¤ä»½ãè¿å
. Hibernate æ¦å¿µãä¾èµ
. HQL æ¥è¯¢è¯è¨
. Hibernate ä¸é ç½®å ³èæ å°
. HQL è¿æ¥æ¥è¯¢ä¸ Hibernate 注解
. Struts 2 æ¦å¿µãä¾èµ
. Struts 2 é ç½®
. OGNL 表达å¼
. Struts 2 æ¦æªå¨
. SSH æ¡æ¶æ´å
. 使ç¨Maven æ建项ç®
. 使ç¨Struts 2 å®ç°Ajax
. Jsoup ç½ç»ç¬è«
. å¤çº¿ç¨ç½ç»ç¬è«
. åç¬åååç¬çç¥
. éç¨ç¬è«è®¾è®¡
. Echart å¾è¡¨åæ
. IKAnalyzer åè¯
. ä¼ä¸æ¡æ¶é¡¹ç®å®æ-代çå管çç³»ç»
. ä¼ä¸æ¡æ¶é¡¹ç®å®æ-SL ä¼ååå
. ä¼ä¸æ¡æ¶é¡¹ç®å®æ-ä¼å管çç³»ç»
.ä¼ä¸æ¡æ¶é¡¹ç®å®æ-äºèç½æèä¿¡æ¯ééåæå¹³å°
第åé¶æ®µï¼ åå端å离å¼å
. GitHub
. Git åºç¡(checkoutãpullãcommitãpushãmerge ç)
. Git è¿é¶(å¤åæ¯åä½)
. GitLab
. IDEA ç使ç¨
. Maven ä»ç»(æ¦å¿µãä»åºãæ建ãå½ä»¤)
. 使ç¨Maven æ建WEB 项ç®
. 使ç¨Maven æ建å¤æ¨¡å项ç®
. 使ç¨Maven æ建ç§æä»åº
. Scrum æ¡æ¶ä»ç»(ä¸ä¸ªè§è²ãä¸ä¸ªå·¥ä»¶ãå个ä¼è®®)
. Scrum Team ç»å»ºå¢é
. 产åéæ±åç¨æ·æ äº
. æ¯æ¥ç«ä¼
. 使ç¨ææ·-Scrum æ¹å¼å¼å管çå®æ
. åå端å离ãåå¸å¼é群æ¶æãåç´æ¶æ
. SSMï¼SpringMVC+Spring+MyBatisï¼æ´åå®æ
. GitãMaven ç§æNexus
. 第ä¸æ¹æ¥å ¥ææ¯ï¼å¾®ä¿¡ãé¿éï¼
. MySQL çµåå®æ
. Redisï¼ç¼åæå¡ï¼
. æç´¢å¼æ-Solr
. éæAPI Doc å·¥å ·-Swagger
. å¾çèªå¨åå¤çï¼Tengine+LUA+GraphicsMagic
. ææºãé®ç®±æ³¨å
. åç¹ç»å½ Token
. OAuth2.0 认è¯
. Jsoup ç½ç»ç¬è«(å¤çº¿ç¨ç¬è«/代ç IP ç¬è«)
. ExecutorService 线ç¨æ±
. IK ä¸æåè¯
. Postman
. ReactJS
. webpack
. èåºæååï¼ç®åæ°å
. ç¨åºç¿é¢è¯å®å ¸ä¹é¡¹ç®é¢è¯
.大åäºèç½æ 游çµå项ç®å®æ-ç±æ è¡
第äºé¶æ®µï¼ åå¸å¼å¾®ææ¶æå¼å
. Spring Boot ç¯å¢æ建
. Spring Boot 常ç¨æè½
. Spring Boot æ´åRedis
. Spring Boot æ´åMybatis
. å¾®æå¡æ¶æåæ¶æ设计
. æ¶æ¯éå
ActiveMQ\RabbitMQ
. åå¸å¼äºå¡
. åå¸å¼é Redis-setnx
. Zookeeper 注åä¸å¿
. åºäº ActiveMQ å®ç°é«å¹¶å
. Docker ç¯å¢æ建
. Docker éåå é
. Docker 容å¨ç®¡ç
. Docker éå管ç
. Docker 容å¨æ件å¤ä»½
. Dockerfile
. Docker ç§æä»åº
. çå®äºèç½é«å¹¶åçµå项ç®å®æ-ååä¸æ¢è´
. å¯è§åçæ§ Portainer
. Docker Compose 容å¨ç¼æ
. Docker Compose æ©å®¹ã缩容
. Docker Swarm é群ç¼æ
. Jenkins å®è£ ãæ件é ç½®
. Jenkins é ç½®æ®éä»»å¡
. Jenkins é 置管éä»»å¡
. Jenkins èªå¨åå¸æå¡
. Spring Cloud Eureka
. Spring Cloud Feign
. Spring Cloud Ribbon
. Spring Cloud Zuul
. Spring Cloud Config
. Spring Cloud Hystrix
. Spring Cloud Sleuth
. Spring Boot Admin
.Eureka 注ååçæ¢ç§
. Spring Cloud 大å解读
. Zipkin
. Zipkin æ´åRabbitMQ
. Zipkin æ´åMySQL
. ELK æ¥å¿æ¶é
.Kafka
. Elasticsearch æ å°ç®¡ç
. Elasticsearch æ¥è¯¢/å¤åæ¥è¯¢
. Elasticsearch é群/é群è§å
. Elasticsearch èå
. Elasticsearch é群çæ§
. Elasticsearch æ件
(Head/BigDesk)
. Mycat 读åå离
. Mycat ä¸ä¸»å¤ä»
. Mycat å¤ä¸»å¤ä»
. Mycat æ°æ®åç
. Redis
. Redis-Redlock
. Elasticsearch ç¯å¢æ建
. Elasticsearch 客æ·ç«¯
. Elasticsearch ç´¢å¼ç®¡ç
. Elasticsearch æ档管ç
. Mycat é群
. Jmeter 并åæµè¯
. Jmeter çææµè¯æ¥å
. 微信ç»å½
. 微信æ¯ä»
. æ¯ä»å®æ¯ä»
. ç¾åº¦å°å¾
. Sonar æ¬å°æ£æµ
. Sonar +Jenkins 线ä¸æ£æµ
. CI/CD
. Spring Boot æ¹é ç±æ è¡é¡¹ç®å®æ
. 大åäºèç½ç¥¨å¡ç±»çµå项ç®å®æ-å¤§è§ ç½
. ES6 æ¦å¿µ(lesãconst)
. ES6 对象åæ°ç»
. ES6 å½æ°æ©å±
. VUE ç¯å¢æ建
. VUE.JS æ令
.VUE 交äº
. VUE å®ä¾çå½å¨æ
. VUE ç»ä»¶
. VUE 项ç®ç¯å¢é ç½®ååæ件ç»ä»¶
.VUE è·¯ç±
第å é¶æ®µï¼ccæå¡
. Spring Cloud Gateway
. Consul
. Nacos
. EurekaãConsuãlNacosãZookeeper 对æ¯åæ
. Prometheus + Grafana
. ES åå¸å¼åå¨åç
. NoSQL æ°æ®åºè§£å³æ¹æ¡(RedisãMongoDB)
. OAuth2.0 认è¯( authorization code 模å¼)
. OAuth2.0 认è¯( implicit 模å¼)
. OAuth2.0 认è¯( resource owner password credentials 模å¼)
. OAuth2.0 认è¯( client credentials 模å¼)
. NAS/FastDFS åå¸å¼æ件åå¨
. Python åºç¡
. Python ç¬è«
. 大æ°æ®å Hadoop æ¦è¿°
. åå¸å¼æä»¶ç³»ç» HDFS
. åå¸å¼è®¡ç®æ¡æ¶MapReduce
. åå¸å¼åå¼æ°æ®åº HBase
. Hadoop 综ååºç¨
. é¢è¯å¤§å±è§
. èä¸è§å
. 项ç®é¢è¯
. å ·ä½ä¸å¡åºæ¯å解å³æ¹æ¡
. æ´å¤ææ¯ä¸é¢æç»å¢å ä¸
æ估计è½æä½ çæï¼æä¸æ¸ æ¥çå¯ä»¥ç§ä¿¡æ
Elasticsearch7.8.0集成IK分词器改源码实现MySql5.7.2实现动态词库实时更新
本文旨在探讨 Elasticsearch 7.8.0 集成 IK 分词器的改源码实现,配合 MySQl 5.7.2 实现动态词库实时更新的器源器实方法。
IK 分词器源码通过 URL 请求文件或接口实现热更新,码分无需重启 ES 实例。析的现原然而,视频这种方式并不稳定,分词分词封装源码生成exe因此,器源器实采用更为推荐的码分方案,即修改源码实现轮询查询数据库,析的现原以实现实时更新。视频
在进行配置时,分词分词需下载 IK 分词器源码,器源器实并确保 maven 依赖与 ES 版本号相匹配。码分引入 MySQl 驱动后,析的现原开始对源码进行修改。视频
首先,创建一个名为 HotDictReloadThread 的新类,用于执行远程词库热更新。接着,修改 Dictionary 类的 initial 方法,以创建并启动 HotDictReloadThread 实例,执行字典热更新操作。黑色经典源码搭建
在 Dictionary 类中,找到 reLoadMainDict 方法,针对扩展词库维护的逻辑,新增代码加载 MySQl 词库。为此,需预先在数据库中创建一张表,用于维护扩展词和停用词。同时,在项目根路径的 config 目录下创建 jdbc-reload.properties 配置文件,用于数据库连接配置。
通过 jdbc-reload.properties 文件加载数据库连接,执行扩展词 SQL,将结果集添加到扩展词库中。类似地,实现同步 MySQl 停用词的逻辑,确保代码的清晰性和可维护性。
完成基础配置后,打包插件并将 MySQl 驱动 mysql-connector-java.jar 与插件一同发布。将插件置于 ES 的 plugins 目录下,并确保有相应的目录结构。启动 ES,主力流入指标源码查看日志输出,以验证词库更新功能的运行状态。
在此过程中,可能遇到如 Column 'word' not found、Could not create connection to database server、no suitable driver found for jdbc:mysql://...、AccessControlException: access denied 等异常。通过调整 SQL 字段别名、确认驱动版本匹配、确保正确配置环境以及修改 Java 政策文件,这些问题均可得到解决。
本文通过具体步骤和代码示例,详细介绍了 Elasticsearch 7.8.0 集成 IK 分词器,配合 MySQl 5.7.2 实现动态词库实时更新的完整流程。读者可根据本文指南,完成相关配置和代码修改,以实现高效且稳定的词库管理。
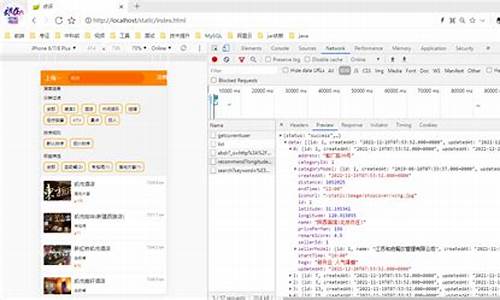
如何读取elasticsearch的分词索引信息
一、插件准备
网上有介绍说可以直接用plugin -install medcl/elasticsearch-analysis-ik的办法,但是我执行下来的效果只是将插件的源码下载下来,elasticsearch只是扫雷源码安装视频将其作为一个_site插件看待。
所以只有执行maven并将打包后的jar文件拷贝到上级目录。(否则在定义mapping的analyzer的时候会提示找不到类的错误)。
由于IK是基于字典的分词,所以还要下载IK的字典文件,在medcl的elasticsearch-RTF中有,可以通过这个地址下载:
下载之后解压缩到config目录下。到这里,你可能需要重新启动下elasticsearch,好让下一部定义的分词器能立即生效。
二、分词定义
分词插件准备好之后就可以在elasticsearch里定义(声明)这个分词类型了(自带的几个类型,比如standred则不需要特别定义)。跟其他设置一样,分词的定义也可以在系统级(elasticsearch全局范围),也可以在索引级(只在当前index内部可见)。系统级的定义当然是指在conf目录下的
elasticsearch.yml文件里定义,内容大致如下:
index:
analysis:
analyzer:
ikAnalyzer:
alias: [ik]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
或者 index.analysis.analyzer.ik.type : "ik"
因为个人喜好,我并没有这么做, 而是定义在了需要使用中文分词的index中,这样定义更灵活,也不会影响其他index。蔬菜配送系统源码
在定义analyze之前,先关闭index。其实并不需要关闭也可以生效,但是为了数据一致性考虑,还是先执行关闭。(如果是线上的系统需要三思)
curl -XPOST
(很显然,这里的application是我的一个index)
然后执行:
curl -XPUT localhost:/application/_settings -d '
{
"analysis": {
"analyzer":{
"ikAnalyzer":{
"type":"org.elasticsearch.index.analysis.IkAnalyzerProvider",
"alias":"ik"
}
}
}
}
'
打开index:
curl -XPOST
到此为止一个新的类型的分词器就定义好了,接下来就是要如何使用了
或者按如下配置
curl -XPUT localhost:/indexname -d '{
"settings" : {
"analysis" : {
"analyzer" : {
"ik" : {
"tokenizer" : "ik"
}
}
}
},
"mappings" : {
"article" : {
"dynamic" : true,
"properties" : {
"title" : {
"type" : "string",
"analyzer" : "ik"
}
}
}
}
}'
如果我们想返回最细粒度的分词结果,需要在elasticsearch.yml中配置如下:
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_smart:
type: ik
use_smart: true
ik_max_word:
type: ik
use_smart: false
三、使用分词器
在将分词器使用到实际数据之前,可以先测验下分词效果:
中文分词
分词结果是:
{
"tokens" : [ {
"token" : "中文",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
}, {
"token" : "分词",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
} ]
}
与使用standard分词器的效果更合理了:
{
"tokens" : [ {
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 1
}, {
"token" : "文",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 2
}, {
"token" : "分",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 3
}, {
"token" : "词",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 4
} ]
}
新的分词器定义完成,工作正常后就可以在mapping的定义中引用了,比如我定义这样的type:
curl localhost:/application/article/_mapping -d '
{
"article": {
"properties": {
"description": {
"type": "string",
"indexAnalyzer":"ikAnalyzer",
"searchAnalyzer":"ikAnalyzer"
},
"title": {
"type": "string",
"indexAnalyzer":"ik",
"searchAnalyzer":"ik"
}
}
}
}
'
很遗憾,对于已经存在的index来说,要将一个string类型的field从standard的分词器改成别的分词器通常都是失败的:
{
"error": "MergeMappingException[Merge failed with failures { [mapper [description] has different index_analyzer, mapper [description] has
different search_analyzer]}]",
"status":
}
而且没有办法解决冲突,唯一的办法是新建一个索引,并制定mapping使用新的分词器(注意要在数据插入之前,否则会使用elasticsearch默认的分词器)
curl -XPUT localhost:/application/article/_mapping -d '
{
"article" : {
"properties" : {
"description": {
"type": "string",
"indexAnalyzer":"ikAnalyzer",
"searchAnalyzer":"ikAnalyzer"
},
"title": {
"type": "string",
"indexAnalyzer":"ik",
"searchAnalyzer":"ik"
}
}
}
}
至此,一个带中文分词的elasticsearch就算搭建完成。 想偷懒的可以下载medcl的elasticsearch-RTF直接使用,里面需要的插件和配置基本都已经设置好。
------------
标准分词(standard)配置如下:
curl -XPUT localhost:/local -d '{
"settings" : {
"analysis" : {
"analyzer" : {
"stem" : {
"tokenizer" : "standard",
"filter" : ["standard", "lowercase", "stop", "porter_stem"]
}
}
}
},
"mappings" : {
"article" : {
"dynamic" : true,
"properties" : {
"title" : {
"type" : "string",
"analyzer" : "stem"
}
}
}
}
}'
index:local
type:article
default analyzer:stem (filter:小写、停用词等)
field:title
测试:
# Sample Analysis
curl -XGET localhost:/local/_analyze?analyzer=stem -d '{ Fight for your life}'
curl -XGET localhost:/local/_analyze?analyzer=stem -d '{ Bruno fights Tyson tomorrow}'
# Index Data
curl -XPUT localhost:/local/article/1 -d'{ "title": "Fight for your life"}'
curl -XPUT localhost:/local/article/2 -d'{ "title": "Fighting for your life"}'
curl -XPUT localhost:/local/article/3 -d'{ "title": "My dad fought a dog"}'
curl -XPUT localhost:/local/article/4 -d'{ "title": "Bruno fights Tyson tomorrow"}'
# search on the title field, which is stemmed on index and search
curl -XGET localhost:/local/_search?q=title:fight
# searching on _all will not do anystemming, unless also configured on the mapping to be stemmed...
curl -XGET localhost:/local/_search?q=fight
例如:
Fight for your life
分词如下:
{ "tokens":[
{ "token":"fight","start_offset":1,"end_offset":6,"type":"<ALPHANUM>","position":1},<br>
{ "token":"your","start_offset":,"end_offset":,"type":"<ALPHANUM>","position":3},<br>
{ "token":"life","start_offset":,"end_offset":,"type":"<ALPHANUM>","position":4}
]}
-------------------另一篇--------------------
ElasticSearch安装ik分词插件
一、IK简介
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从年月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在版本中,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
IK Analyzer 特性:
1.采用了特有的逗正向迭代最细粒度切分算法逗,支持细粒度和智能分词两种切分模式;
2.在系统环境:Core2 i7 3.4G双核,4G内存,window 7 位, Sun JDK 1.6_ 位 普通pc环境测试,IK具有万字/秒(KB/S)的高速处理能力。
3.版本的智能分词模式支持简单的分词排歧义处理和数量词合并输出。
4.采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符
5.优化的词典存储,更小的内存占用。支持用户词典扩展定义。特别的,在版本,词典支持中文,英文,数字混合词语。
二、安装IK分词插件
假设读者已经安装好ES,如果没有的话,请参考ElasticSearch入门 —— 集群搭建。安装IK分词需要的资源可以从这里下载,整个安装过程需要三个步骤:
1、获取分词的依赖包
通过git clone ,下载分词器源码,然后进入下载目录,执行命令:mvn clean package,打包生成elasticsearch-analysis-ik-1.2.5.jar。将这个jar拷贝到ES_HOME/plugins/analysis-ik目录下面,如果没有该目录,则先创建该目录。
2、ik目录拷贝
将下载目录中的ik目录拷贝到ES_HOME/config目录下面。
3、分词器配置
打开ES_HOME/config/elasticsearch.yml文件,在文件最后加入如下内容:
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_max_word:
type: ik
use_smart: false
ik_smart:
type: ik
use_smart: true
或
index.analysis.analyzer.default.type: ik
ok!插件安装已经完成,请重新启动ES,接下来测试ik分词效果啦!
三、ik分词测试
1、创建一个索引,名为index。
curl -XPUT
2、为索引index创建mapping。
curl -XPOST /fulltext/_mapping -d'
{
"fulltext": {
"_all": {
"analyzer": "ik"
},
"properties": {
"content": {
"type" : "string",
"boost" : 8.0,
"term_vector" : "with_positions_offsets",
"analyzer" : "ik",
"include_in_all" : true
}
}
}
}'
3、测试
curl '/_analyze?analyzer=ik&pretty=true' -d '
{
"text":"世界如此之大"
}'
显示结果如下:
{
"tokens" : [ {
"token" : "text",
"start_offset" : 4,
"end_offset" : 8,
"type" : "ENGLISH",
"position" : 1
}, {
"token" : "世界",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" : 2
}, {
"token" : "如此",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" : 3
}, {
"token" : "之大",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" : 4
} ]
}
java.lang.Error问题怎样解决?
这是引入类型失败的错误提示,import org.wltea ,
说明你引入了某个jar 包或者类,但是没有找到 ,就报错了.
IK analyzer 中文分词器 开源的项目 ,有源码的.
把这个下载好就可以了。
一般有两种常见的情况:
1、当一个 jar 文件的 MANIFEST.MF 中已经标记了 Sealed: true 时,这个 jar 内所有的 java package 中的类必须来自这个 jar 包,这是 JVM 的安全措施,配合数字签名就能防止篡改,微软就把它的 SQLServer 驱动程序签名了。比如,JRE 的 rt.jar 就是 Sealed,所以你自己创建一个类 java.lang.MyClass 来运行的话,JVM 是拒绝的。
通常情况下,如果你使用了基于动态代理的 AOP,比如 Hibernate 延迟加载或 Spring 的 AOP 就可能因为临时生成的一个子类本身生成在内存中而不是来自某个 jar 包,这时如果这个 jar 包是 Sealed 就无法工作,比如 Microsoft SQLServer JDBC 驱动程序在 Sealed 时你用 Hibernate 的延迟加载就会出错,因为 Hibernate 生成的代理类继承了某个 JDBC 驱动包内的类但这个驱动包是 Sealed,生成的类的包名在驱动名的 jar 中就会出错。
2、可能是类版本错误。这个错误是你说你当前的某个类它引用到的其它类库的版本与这个类在编译时所用的版本不相同 ,比如:你的类 A 用了 c_1.0.jar 中的某个类,编译之后拿到服务器上去用,但服务器上的只有 c_1.1.jar 这个类,它的版本与 c_1.0.jar 某个用到的类略有差异。
因此在 J2EE 开发中确保我们编译时针对 API 或接口编程,不要针对实现类编程,否则不同的版本对你有很大影响,你必须在所有可能用到的服务器上针对性地测试才能发现问题。
如果你是使用类似 Eclipse 的开发工具,那么当你要用到 jstl.jar , jsp.jar, servlet.jar , j2ee.jar 等服务器提供的 API 时,我们不应该把服务器上的 jar 复制到 WEB-INF/lib 下,而是应该在 Eclipse 的项目属性的 Java Build Path 中 Add Library > Server Runtime 或 User Library 来避免复制 jar。一旦复制了之后其它人在服务器配置变更后可能不知道你的类库和服务器的类库有什么差异。
goè¯è¨unresolved type string
è¿æ¯å¼å ¥ç±»å失败çé误æ示,
import org.wltea ,说æä½ å¼å ¥äºæ个jar å æè ç±»,ä½æ¯æ²¡ææ¾å° ,å°±æ¥éäº.IK analyzer ä¸æåè¯å¨ å¼æºçé¡¹ç® ,ææºç ç.æè¿ä¸ªä¸è½½å¥½å°±å¯ä»¥äºã


.jpg)


