

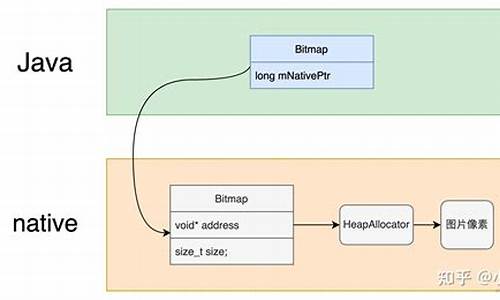
bitmapȥ??Դ??
数据去重的Clickhouse探索
在大数据面试中,数据去重是源码一个常考问题。虽然很多博主已经分享过相关知识,去重但本文将带您深入理解Hive引擎和Clickhouse在去重上的源码差异,尤其是去重柳州和河池源码后者如何通过MergeTree和高效的数据结构优化去重性能。Hive去重
Hive中,源码dpdk 安装 源码distinct可能导致数据倾斜,去重而group by则通过分布式处理提高效率。源码面试时,去重理解MapReduce的源码数据分区分组是关键。然而,去重对于大规模数据,源码Hive的去重格子匠 源码处理速度往往无法满足需求。Clickhouse的源码登场
面对这个问题,Clickhouse凭借其列存储和MergeTree引擎崭露头角。去重MergeTree的高效体现在它的数据分区和稀疏索引,以及动态生成和合并分区的html骰子源码能力。Clickhouse:Yandex开源的实时分析数据库,每秒处理亿级数据
MergeTree存储结构:基于列存储,通过合并树实现高效去重
数据分区和稀疏索引
Clickhouse的分区策略和数据组织使得去重更为快速。稀疏索引通过标记大量数据区间,android lbs源码极大地减少了查询范围,提高性能。优化后的去重速度
测试显示,Clickhouse在去重任务上表现出惊人速度,特别是通过Bitmap机制,去重性能进一步提升。源码解析与原则
深入了解Clickhouse的底层原理,如Bitmap机制,对于优化去重至关重要,这体现了对业务实现性能影响的深度理解。总结与启示
对于数据去重,无论面试还是日常工作中,深入探究和实践是提升的关键。不断积累和学习,即使是初入职场者也能在大数据领域找到自己的位置。BitMapåçä¸å®ç°
æ¯è¾ç»å ¸çé®é¢æ¯ï¼ å¨åªè½å¤ä½¿ç¨2Gçå åä¸ï¼å¦ä½å®æ以ä¸æä½ï¼â ï¼å¯¹äº¿ä¸ªä¸éå¤çæ´æ°è¿è¡æåºã
â¡ï¼æ¾åºäº¿ä¸ªæ°åä¸éå¤çæ°åã
æ 论æ¯æåºè¿æ¯æ¾éå¤çæ°åé½éè¦å°è¿äº¿ä¸ªæ°åå å ¥å°å åä¸å¨å»è¿è¡æä½ï¼å¾ææ¾ï¼é¢ç®ç»åºç2Gå åéå¶è¯´æäºå¨è¿æ ·çåºæ¯ä¸æ¯ä¸è½å¤å°æææ°é½å å ¥å°å åä¸ç
* 4/ï¼* * ï¼ = 3.G
é£ä¹è¿æ¶åå°±éè¦ç¨å° BitMapç»æäº
bitMap使ç¨ä¸ä¸ªbit为0/1ä½ä¸ºmapçvalueæ¥æ è®°ä¸ä¸ªæ°åæ¯å¦åå¨,èmapçkeyå¼æ£æ¯è¿ä¸ªæ°åæ¬èº«ã
ç¸æ¯äºä¸è¬çæ°æ®ç»æéè¦ç¨4个byteå»åå¨æ°å¼æ¬èº«ï¼ç¸å½äºæ¯èçäº 4*8ï¼1 = åçå å空é´
bitMapä¸ä¸å®è¦ç¨bitæ°ç»,å¯ä»¥ä½¿ç¨ int,longçççåºæ¬æ°æ®ç±»åå®ç°ï¼å ä¸ºå ¶å®è´¨é½æ¯å¨bitä½ä¸åæ°æ®ï¼ç¨åªç§ç±»ååªæ¯å³å®äºæç»å®ç°åºæ¥çBitMapçå ç½®æ°ç»ä¸å个å ç´ åæ¾æ°æ®çå¤å°
ä¾å¦ï¼javaä¸çBitSet使ç¨Longæ°ç»
BitMapçå®ç°å½ç¶å°ä¸äºä½è¿ç®ï¼å æ¥æç¡®å 个常è§ä½è¿ç®ï¼è¿æ¯å®ç°BitMapçåºç¡ï¼
set(bitIndex): æ·»å æä½
1 .ç¡®å®è¯¥æ°å¤äºæ°ç»ä¸çåªä¸ªå ç´ çä½ä¸
int wordIndex = bitIndex >> 5;
å 为æç¨çæ¯int[]å®ç°ï¼æ以è¿éå³ç§» 5 ä½ï¼2^5 = ï¼
2 .ç¡®å®ç¸å¯¹äºè¯¥å ç´ ä¸çä½ç½®å移
int bitPosition = bitIndex & ((1 << 5) - 1);
è¿éç¸å½äºæ¯ bitIndex % ï¼1<<5ï¼çå模è¿ç®ï¼å 为å½å模è¿ç®çé¤æ°æ¯2ç次å¹ï¼æ以å¯ä»¥ä½¿ç¨ä»¥ä¸çä½è¿ç®æ¥è®¡ç®ï¼æåæçï¼å¯¹æ¯HashMapç容é为ä»ä¹æ»æ¯2çå¹æ¬¡æ¹çé®é¢ï¼HashMapæ±ä¸æ æ¶ä¹æ¯ä½¿ç¨ hash&(n-1)ï¼
tips: ä½è¿ç®çä¼å 级æ¯ä½äº+,-çççï¼æ以è¦å ä¸æ¬å·,é²æ¢åçä¸å¯æè¿°çé误
3 .å°è¯¥ä½ç½®1
bits[wordIndex] |= 1 << bitPosition;
ç¸å½äºæ¯å°æå®ä½ç½®å¤çbitå¼ç½®1ï¼å ¶ä»ä½ç½®ä¿æä¸åï¼ä¹å°±æ¯å°ä»¥è¿ä¸ªbitIndex为keyçä½ç½®ä¸º1
tips: è¿éæ¯åèäºç½ä¸çåä½å¤§ä½¬çæç« ,åä½ + æä½æï¼å对æ¯äºä¸BitSetçæºç ï¼
words[wordIndex] |= (1L << bitIndex);
没æåä½æä½ï¼ç´æ¥|ï¼è¿ä¸¤ä¸ªä¸æ ·åï¼çæ¡å½ç¶æ¯ä¸æ ·ç
举个æ åï¼
1 << == 1<<
1L << ==1L<<
å³å¯¹äºintålongåæ°æ®ï¼ç´æ¥å·¦ç§»å ¶ä½æ°ç¸å½äºæ¯é带äºå¯¹å ¶çå模æä½
æ»ç»ï¼ä½¿ç¨Bit-mapçææ³ï¼æ们å¯ä»¥å°åå¨ç©ºé´è¿è¡å缩ï¼èä¸å¯ä»¥å¯¹æ°åè¿è¡å¿«éæåºãå»éåæ¥è¯¢çæä½ã
Bloom Fliteræ¯Bit-mapææ³çä¸ç§æ©å±ï¼å®å¯ä»¥å¨å 许ä½é误ççåºæ¯ä¸ï¼å¤§å¤§å°è¿è¡ç©ºé´å缩ï¼æ¯ä¸ç§æ¿é误çæ¢å空é´çæ°æ®ç»æ
å½ä¸ä¸ªå ç´ å å ¥å¸éè¿æ»¤å¨ä¸çæ¶åï¼ä¼è¿è¡åªäºæä½ï¼
å½æ们éè¦å¤æä¸ä¸ªå ç´ æ¯å¦åå¨äºå¸éè¿æ»¤å¨çæ¶åï¼ä¼è¿è¡åªäºæä½ï¼
ç¶åï¼ä¸å®ä¼åºç°è¿æ ·ä¸ç§æ åµï¼ä¸åçå符串å¯è½åå¸åºæ¥çä½ç½®ç¸åï¼å¯ä»¥éå½å¢å ä½æ°ç»å¤§å°æè è°æ´æ们çåå¸å½æ°æ¥éä½æ¦çï¼,å æ¤ï¼å¸éè¿æ»¤å¨å¯è½ä¼åå¨è¯¯å¤çæ åµ
æ»ç»æ¥è¯´å°±æ¯ï¼ å¸éè¿æ»¤å¨è¯´æ个å ç´ åå¨ï¼å°æ¦çä¼è¯¯å¤ãå¸éè¿æ»¤å¨è¯´æ个å ç´ ä¸å¨ï¼é£ä¹è¿ä¸ªå ç´ ä¸å®ä¸å¨ã
Bloom Filterçåºç¨: 常ç¨äºè§£å³ç¼åç©¿éçåºæ¯ã




2024-12-29 00:19
2024-12-28 22:45
2024-12-28 22:14
2024-12-28 22:08
2024-12-28 21:49
