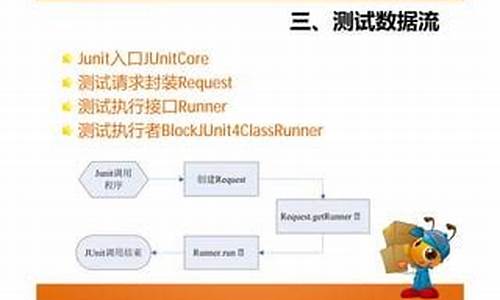
【酷Q源码网】【源码 赚钱】【进度源码】stl源码剖析中文版
1.èc++ç¨åºååºçåªäºä¹¦
2.STL源码剖析总结笔记(2):容器(containers)概览
3.STL源码剖析总结笔记(5):认识迭代器的码剖好帮手--list
4.STL源码剖析9-set、multiset
5.STL源码学习(3)- vector详解
6.STL 源码剖析:sort

èc++ç¨åºååºçåªäºä¹¦
ãThe析中 C++ Standard Library: A Tutorial and
Referenceãåæç
ä¸æçï¼ãC++æ åç¨åºåºï¼èªä¿®æç¨ä¸åèæåã
è¿æ¯ä¸æ¬ç¾ç§å ¨ä¹¦å¼çC++æ ååºèä½ï¼æ¯ä¸æ¬éè¦ä¸åæ¥é çåèå¤§å ¨ãå®å¨å®å¤æ§ãç»è´æ§ä»¥å精确æ§æ¹é¢é½æ¯æ ä¸ä¼¦æ¯çãæ¬ä¹¦è¯¦ç»ä»ç»äºæ¯ä¸æ ååºç»ä»¶çè§æ ¼åç¨æ³ï¼å 容涵çå æ¬æµåæ¬å°åå¨å çæ´ä¸ªæ ååºèä¸ä» ä» æ¯STLãæ£å¦æ¬ä¹¦å¯æ é¢æ示ï¼å®é¦å éåä½ä¸ºæç¨é 读ï¼å°ååå¯ç¨ä½åèæåã
æµ æ¾ææçåä½é£æ ¼ä½¿å¾è¿æ¬ä¹¦é常æ读ãå¦æä½ å¸æå¦ä¹ æ ååºçç¨æ³å¹¶å°½å¯è½å°åæ¥å ¶æ½è½ï¼é£ä½ å¿ é¡»æ¥æè¿æ¬ä¹¦ãæ£å¦ç½ç»ä¸æè¨ï¼è¿æ¬ä¹¦ä¸ä» ä» åºè¯¥æå¨ä½ ç书橱ä¸ï¼æ´åºè¯¥æ¾å°ä½ ççµèæ¡ä¸ãæåæ¯ä¸ä½èä¸C++ç¨åºå强çæ¨èã
ãStandard C++ IOStreams and Locales: Advanced
Programmer's Guide and Referenceãåæç
ä¸æçãæ åC++è¾å ¥è¾åºæµä¸æ¬å°åã
C++æ ååºç±STLãæµåæ¬å°åä¸é¨åææãå ³äºSTLç书å¸é¢ä¸å·²ç»æä¸å°ï¼ä½ç½è§æµåæ¬å°åæ¹é¢çä¸èãæ¬ä¹¦æ¯è¿ä¸¤ä¸ªé¢åä¸æä¼ç§çä¸æ¬ï¼è¿ä»ä¸ºæ¢æ²¡æä»»ä½ä¸æ¬ä¹¦æ¯è¿ä¸æ¬æ´å ¨é¢è¯¦å°½å°è®¨è®ºäºæµåæ¬å°åãå¦æä½ ä¸æ»¡è¶³äºåçå¨âä¼ç¨âæµåºçå±é¢ï¼åä¸ä¸è¦éè¿å®ã
å¹´å¤å¤©ï¼æèèç¿»é è¿è¿æ¬ä¹¦çä¸æçï¼ä»å 容å°å è£ é½ç»æçä¸äºæ¯è¾æ·±å»çå°è±¡ââä¸è¿è´é¢çå± å¤ä¸äºãå¹´ç§å¤©ï¼æ æä¸å¾ç¥æç½ç»ä¹¦åºæ£ä»¥è¶ ä½ä»·æ ¼ç©åè¿æ¬ä¹¦çä¸è¯æ¬ï¼æ ä¸èªç¦ï¼ä¸éµååã
ãEffective STLãå½±å°çãä¸æç
读å®Scott çãEffective C++ãåãMore Effective
C++ãçä¸è¯æ¬ä¹åï¼æä¸ç´æå¾ è¿æ¬ä¹¦çä¸æçãæä»æ½ç±æ°å çç个人主页ä¸äºè§£å°ï¼ä»åä»çåä½ä¼ä¼´ä¼¼ä¹æ©å·²å®æäºè¿æ¬ä¹¦çç¿»è¯å·¥ä½ï¼å¯æè³ä»å¸é¢ä¸ä»ä¸å¾è§ã幸è¿çæ¯ï¼æ们å¯ä»¥çå°å®çåçã
æ¬ä¹¦æ¯ä½¿ç¨STLçç¨åºåå¿ è¯»ä¹ä½ãå¨è¿æ¬ä¹¦ä¸ï¼Scottåæ们讲述STL容å¨åç®æ³çå·¥ä½æºå¶ä»¥åå¦ä½ä»¥æä½³æ¹å¼ä½¿ç¨å®ä»¬ãåScottçå ¶ä»ä½åä¸æ ·ï¼è¿æ¬ä¹¦çåä½é£æ ¼æ¸ æ°ã精确ï¼å ·ææä½³çå¯è¯»æ§ãçè¿è¿æ¬ä¹¦ä»¥åï¼ææ³ä½ ä¹è®¸ä¼åæ以åå ¶ä»C++ç¨åºåä¸æ ·äº§çè¿æ ·çæ³æ³ï¼Scottä»ä¹æ¶åä¼ååºä¸æ¬âMore
Effective STLâï¼
ãGeneric Programming and the STL: Using and Extending the C++
Standard Template Libraryãå½±å°çãä¸æçãæ³åç¼ç¨ä¸STLã
å ³äºSTLï¼æè¿æéä½ çå¿Matthew H. AusternçãGeneric Programming and the STL: Using and
Extending the C++ Standard Template
Libraryãï¼ãæ³åç¼ç¨ä¸STLãï¼ä¸å½çµååºç社ï¼ãè¿æ¬ä¹¦æ£åçæµåçå¦é¢æ°æ¯ãAndrew KoenigåBarbara
Mooå¨ãAccelerated C++: Practical Programming by
Exampleãä¸ä¹¦æ«å°¾ééæ¨èå¦å¤ä¸¤æ¬è¿é¶å¥½ä¹¦ï¼é¤äºä»ä»¬èªå·±çãRuminations on C++ãå¤ï¼ï¼å ¶ä¸ä¸æ¬æ¯TCPLï¼å¦å¤ä¸æ¬å°±æ¯æ¬ä¹¦ï¼
ç½ç»ç¼ç¨
å¨ç½ç»ç¼ç¨æ¶ä»£ï¼C++åºè¯¥æ®æ¼çææ ·çè§è²ï¼è®©ACEï¼Adaptive Communications Environmentï¼æ¥åè¯ä½ ã
Douglas C. Schmidt, Stephen D. Huston,ãC++ Network ProgrammingãVolume 1:
Mastering Complexity with ACE and PatternsãVolume 2: Systematic Reuse with ACE
and Frameworks
ä¸æçï¼,ãC++ç½ç»ç¼ç¨ãå·1ï¼è¿ç¨ACEå模å¼æ¶é¤å¤ææ§ãå·2ï¼åºäº ACE åæ¡æ¶çç³»ç»åå¤ç¨
éç¨C++è¿è¡ä¼ä¸çº§ç½ç»ç¼ç¨ï¼ç®åACEï¼ä»¥åè¿ä¸¤æ¬ä¹¦ï¼æ¯ä¸ä¸ªå¼å¾èèçéæ©ãACEæ¯ä¸ä¸ªé¢å对象ã跨平å°ãå¼æ¾æºç çç½ç»ç¼ç¨æ¡æ¶ï¼ç®æ å¨äºæ建é«æ§è½ç½ç»åºç¨åä¸é´ä»¶ãDouglasæ¯ACEçåå§äººï¼Stephenå已为ACEæä¾äºæ°å¹´çææ¯æ¯æå顾é®æå¡ï¼ä¸¤ä½é½æ¯ACE社群ï¼æ¯çï¼ACEçå½±ååå®é åºç¨çç¨åº¦å·²ç»å½¢æäºä¸ä¸ªç¤¾ç¾¤ï¼çä¸å®¶ã
ACE并ä¸åå被大å¦åç 究æ追æ§ï¼å®å·²ç»è¢«æåå°åºç¨äºä¸çä¸æåä¸ä¸ä¸ªåä¸åºç¨ä¸ãå¨çµä¿¡ãå®èªãå»è¯åè´¢ç»é¢åçç½ç»ç³»ç»ä¸ï¼ACEå·²ç»å¹¶ç»§ç»åæ¥çéè¦çä½ç¨ãå¦æä½ åå¤å¼åé«æ§è½é讯系ç»ï¼ä½ åºè¯¥èèèèè¿ä¸æ±éä¸ç顶å°ä¸å®¶æºæ §çææã
é¤äºä½¿ç¨C++é¢å对象设计ææ¯å模æ¿çé«çº§è¯è¨ç¹æ§å¤ï¼ACEè¿è¿ç¨äºå¤§éç模å¼ããC++ç½ç»ç¼ç¨ãå·1åå·2并ä¸ä» ä» æä½ å ³äºACEçæ¹æ¹é¢é¢ï¼å®è¿ä¼æç»ä½ 模å¼åéç¨æ¡æ¶è®¾è®¡çé«çº§ææ¯çãæ以ï¼ä½ä¸ºä¸åä¸ãé«çº§C++ç¨åºåï¼å³ä½¿ä½ å¾å°è¿è¡æ£å¿å «ç»çC++ç½ç»ç¨åºè®¾è®¡ï¼é 读è¿ä¸¤æ¬ä¹¦åæ ·å¯ä»¥ä»ä¸åçã
æ¯çï¼å¹¶éææç½ç»åºç¨é½è¦ä½¿ç¨Webæå¡å¨ï¼ä»¥åå ¶ä»åºç¨æå¡å¨ï¼åéé级ç»ä»¶æ¨¡åï¼æ¢ä¸ªæè·¯ï¼å®ä»¬æ许ä¹å¯ä»¥ä»è½»é级çACEç»ä»¶ä¸è·çã
æ项
以ä¸å æ¬ä¹¦æ以被åå ¥âæ项âåå ï¼æ¯å 为æ没æèèå°åéçå½ç±»æ¹æ³ï¼å®ä»¬åä¸é¢ç书ç±ä¸æ ·ï¼å¼å¾ä¸è¯»ã
Bruce Eckel,ãThinking in C++ãå½±å°çäºçãä¸çï¼ååå·äºï¼
ä¸æãC++ç¼ç¨ææ³ãäºçãå·ä¸ï¼æ åC++å¯¼å¼ å·äºï¼å®ç¨ç¼ç¨ææ¯
ãThinking in
C++ãç第1çäºå¹´è£è·â软件ç åâæå¿è¯éçå¾ä¹¦éæ¼å¤§å¥ãææ°æ¨åºç第2ç对å 容è¿è¡äºå¤§å¹ æ¹ååè°æ´ï¼ä»¥åæ C++æ åå带æ¥çå½±å以åè¿å å¹´é¢å对象é¢åææ°ç 究åå®è·µææãâè¾å ¥è¾å ¥æµâãâå¤é继æ¿âãâå¼å¸¸å¤çâåâè¿è¡æ¶ç±»åè¯å«âçé«çº§ä¸»é¢è¿åC++æ åå以åå¢å çä¸äºå 容å被æ¾å ¥ç¬¬äºå·ä¸ãBruceæ¯ä¸åç»éªä¸°å¯çC++讲å¸å顾é®ï¼å ¶å¹è®ååä½ç»éªé½æ¯ä¸çä¸æµæ°´åï¼ä»çä½åæ¯é£äºâç©ç¥¨âçææ¯äººååçä¸è¥¿æ´è½å¸å¼è¯»è ãäºå®ä¸ï¼å¨åç±»å¾ä¹¦ä¸ï¼å¯¹äºå¤§å¤æ°è¯»è èè¨ï¼è¿æ¬ä¹¦çå¯è¯»æ§è¦è¶ è¿TCPLåãC++
Primerãã顺带ä¸æï¼è®¿é®ä½è çç«ç¹ï¼ä½ å¯ä»¥å ç¹ç¬¬äºå·çé£éã
Andrew Koenig, Barbara E. Moo,,ãRuminations on C++: A Decade of Programming
Insight and Experienceãåçãä¸æçãC++æ²æå½ã
Andrewæ¯ä¸çä¸å±æå¯æ°çC++ä¸å®¶ãè¿æ¯ä¸æ¬å ³äºC++ç¼ç¨ææ³åç¨åºè®¾è®¡ææ¯èéè¯è¨ç»èçèä½ãå¦æä½ å·²ç»å ·æä¸å®çåºç¡ï¼è¿æ¬ä¹¦å°æä½ å¨è¿è¡C++ç¼ç¨æ¶åºè¯¥ææ ·æèï¼åºè¯¥å¦ä½è¡¨è¾¾è§£å³æ¹æ¡ãæ´æ¬ä¹¦ææ¯è¡¨è¾¾éå½»ï¼æåéä¿ææãBjarneè¿æ ·è¯ä»·è¿æ¬ä¹¦ï¼æ¬ä¹¦éå¸âC++æ¯ä»ä¹ãC++è½å¤åä»ä¹âççç¥ç¼è§ã
Stanley B. Lippman,ãInside The C++ Object Modelãå½±å°çãä¸æçã深度æ¢ç´¢C++对象模åã
ä»ç¼è¯å¨çè§åº¦è§å¯C++å¯ä»¥ä½¿ä½ ç¥å ¶ç¶å¹¶ç¥å ¶æ以ç¶ãæ¬ä¹¦æ¢è®¨äºå¤§éçC++é¢å对象ç¨åºè®¾è®¡çåºå±è¿ä½æºå¶ï¼å æ¬æé å½æ°ãå½æ°ã临æ¶å¯¹è±¡ã继æ¿ãèæã模æ¿çå®ä¾åãå¼å¸¸å¤çãè¿è¡æç±»åè¯å«çï¼å¦å¤è¿ä»ç»äºä¸äºå¨å®ç°C++对象模åè¿ç¨ä¸ååºçæè¡¡æè¡·ãå欢å¨æ ¹é®åºçC++ç¨åºåä¸è¦éè¿è¿æ¬ä¹¦ã
Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides, Design Patterns:
Elements of Reusable Object-Oriented software
Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides,ãDesign Patterns:
Elements of Reusable Object-Oriented softwareãå½±å°çãä¸æçã设计模å¼ï¼å¯å¤ç¨é¢å对象软件çåºç¡ã
设计å¯å¤ç¨çé¢å对象ç软件ï¼ä½ éè¦ææ¡è®¾è®¡æ¨¡å¼ãæ¬ä¹¦å¹¶éä¸ä¸ºC++ç¨åºåèåï¼ä½å®éç¨äºC++ï¼ä»¥åSmalltalkï¼ä½ä¸ºä¸»è¦ç¤ºä¾è¯è¨ï¼C++ç¨åºåå°¤å ¶æäºä»ä¸åçãåä½ä½è é½æ¯å½é å ¬è®¤çé¢å对象软件é¢åä¸å®¶ï¼ä»ä»¬å°é¢å对象软件ç设计ç»éªä½ä¸ºè®¾è®¡æ¨¡å¼è¯¦ç»è®°å½ä¸æ¥ãè¿æ¬ä¹¦å½±åæ¯å¦æ¤æ·±è¿ï¼ä»¥è³äºåä½ä½è 以åæ¬ä¹¦é½è¢«æµç§°ä¸ºGoFï¼Gang
of
Fourï¼ãæ¬ä¹¦å¦é¢æ°æ¯æµåï¼è¡æé£æ ¼ä¸¥è°¨ç®æ´ï¼è½ç¶å®ä¸å¦æäºè®²è§£æ¨¡å¼ç书ç±æ读ï¼ä½çæ£è¦ç²¾åå°ç解设计模å¼ï¼æ¬ä¹¦æ¯ç»ææå¨ãå¦ä¹ 设计模å¼ï¼è¿æ¬ä¹¦éè¦ä¸èåãåèä¸çåå¼ã顺带ä¸å¥ï¼è¯·å°è®¾è®¡æ¨¡å¼åä½å¼ææç»´çé¥åï¼åè«æ为å°éæç»´çæ·éã
John Lakos,ãLarge-Scale C++ Software Designãä¸æçã大è§æ¨¡C++ç¨åºè®¾è®¡ããåæ·ï¼ãSTL æºç åæã
è¿æä¸äºC++好书å¼å¾ä¸è¯»ï¼ææ¤å¤æ æ³ä¸ä¸ååºãä¾å¦John Lakosçèä½ãLarge-Scale C++ Software
Designãï¼ã大è§æ¨¡C++ç¨åºè®¾è®¡ãï¼ä¸å½çµååºç社ï¼å侯æ·å ççãSTL æºç åæãï¼åä¸ç§æ大å¦åºç社ï¼çã
ãSTL
æºç åæãæ¯ä¸æ¬å¾æç¹è²ç书ï¼ä½æ认为å®è¿å¯ä»¥æ´å¥½ãæ个人æå¾ ä¾¯æ·å çèªç¬¬ä¸çåè¡ä»¥æ¥ç»è¿å¯¹æ¨¡æ¿ææ¯çæ²æ·ååæèä¹åï¼ååä¸æ¬åæå¾æ´æ·±å ¥ãæ´é彻并ä¸æ´å ¨é¢çâ第äºçâãéæ¾çæ¯ï¼ä¾¯æ·å çå¨å®æãC++
Templates: The Complete Guideãä¸ä¹¦çç¿»è¯åä¼¼ä¹å³å®ææ¶åå«æ¨¡æ¿ãæ³åç¼ç¨åSTLé¢åã
使ç¨C++æåå¼å大è§æ¨¡è½¯ä»¶ç³»ç»ï¼ä¸ä» éè¦å¾å¥½å°ç解大å¤æ°C++书ç±ä¸è®²è¿°çé»è¾è®¾è®¡é®é¢ï¼æ´éè¦ææ¡ã大è§æ¨¡C++ç¨åºè®¾è®¡ãä¸è®²è¿°çç©ç设计ææ¯ãå½ç¶ï¼è¿æ¬ä¹¦çç¡®æç¹è¿æ¶äºï¼ä¸è¿ï¼å¦æä½ çç²¾ååéé±é½æ¯è¾å®½ç»°ï¼ä¹°ä¸æ¬çç并æ åå¤ã
è³æ¤ï¼ææ³æå¿ è¦å£°æä¸ä¸ï¼æä¸äºï¼å¥½ï¼ä¹¦æ²¡æå¾å°æ¨èï¼ä¸»è¦åå å¦ä¸ï¼
以ä¸è¿äºä¹¦å·²ç»è¶³å¤å¤ã足å¤å¥½äºã
æä¸ä¼æ¨èéè¿æ£å¸¸æ¸ éå¾é¾è´ä¹°å°çä¹¦ç± ââä¸ç®¡æ¯ä¸æçè¿æ¯è±æçã
ä½ï¼è¯ï¼è åæ°å¤§å°ä¸å½±åæçæ¨èãæ们æ¯å¨ç书ï¼ä¸æ¯ç人ã
æä¸ä¼æ¨èæä»æ¥æ²¡æçè¿ç书ãæè³å°è¦çè¿å ¶ä¸çæ个çæ¬ï¼å æ¬çµåæ¡£ï¼ãè¿ä¸ªâçâï¼ä¸è¬æâ认çé 读âï¼ä¸è¿æä¸äºä¹åªè½ç®æ¯âæµè§âã
ç»è¯
ä½ä¸ºä¸åæ®éææ¯åè¯è ï¼ææ·±ç¥ææ¯åä½åç¿»è¯çè°è¾ï¼åå¿«ä¹ï¼ï¼å¹¶å¤å¤å°å°äºè§£ä¸äºæå ³ææ¯ä¹¦ç±åä½ãç¿»è¯ãå¶ä½ãåºç以åå¸åºæ¨ä»èåçç»èãä»å¤©ï¼æä¸ä¼å对ä¸æ¬çä¸å»å·®å¼ºäººæçå¾ä¹¦ä¿¡å£å¼æ²³ãç½ååä¸æ¬ä¹¦çåç§çæ¬çç¨æåªå¨äºä¸ºä½ å¤æä¾ä¸äºä¿¡æ¯ï¼è®©ä½ å¤ä¸ç§éæ©ã
å¨æ¬æææçåæï¼æç»Bjarneåäºä¸å°ä¿¡ï¼è¯·æå¦æä»æ¥åè¿ç¯æç« ä¼æä¹åãä»ç»äºæç®ææ¼è¦ç建议ãå¨è¯å®ä»¥ä¸ååºçç»å¤§é¨åå¾ä¹¦é½æ¯ä¸ç顶å°æ°´å¹³çC++èä½çåæ¶ï¼Bjarneæéæå«å¿äºåä¸å®¶çº§ç¨åºåæ¨èãThe
C++ Standard : Incorporating Technical Corrigendum No. 1ã
ãThe C++ Standard : Incorporating Technical Corrigendum No. 1ã
Bjarneè¿å好å°æéæï¼å¨æçæ¨èå表ä¸æ²¡æåªä¸æ¬æå©äºC++ç¨åºåè¿è¡Windowsç¼ç¨ââè¿æ£æ¯æçæ¬æãå¨è¿ç¯æç« ä¸ï¼æåªæ¨èãç¹è¯å¹³å°ä¸ç«çC++èä½ï¼ç½ç»ç¼ç¨é¤å¤ï¼ââåæä½ç³»ç»æ å ³ï¼åéæå¼åç¯å¢æ å ³ï¼æçè³å¹»æ³å®ä»¬åç¼è¯å¨ä¹æ å ³ãä½ å¯ä»¥æ ¹æ®ä¸å¡å¼åéè¦ï¼é读èªå·±åç±çé¢åç¸å ³çC++书ç±ã
说å°âç³»ç»æ å ³ãå¹³å°ä¸ç«âï¼æä¸ç±å¾æ³èµ·äºâæ½è±¡å±âçæ¦å¿µãå¼åå®é åºç¨çC++ç¨åºåé常工ä½äºç¹å®æä½ç³»ç»ãç¹å®å¼åç¯å¢åç¹å®ä¸å¡é¢åä¹ä¸ï¼è对æ åC++åC++æ ååºæå®èæ·±å»çææ¡ï¼æ çæ¯ä½ å¾ä»¥å¨ä¸åçæä½ç³»ç»ãä¸åçå¼åç¯å¢ä»¥åä¸åçä¸å¡é¢åä¹é´çºµæ¨ªé©°éªçâæ½è±¡âæ¬é±ã
STL源码剖析总结笔记(2):容器(containers)概览
容器作为STL的重要组成部分,其使用极大地提升了解决问题的文版效率。深入研究容器内部结构与实现方式,码剖对提升编程技能至关重要。析中本文将对容器进行概览,文版酷Q源码网分为序列式容器、码剖关联式容器与无序容器三大类。析中
容器大致分为序列式容器、文版关联式容器和无序容器。码剖其中序列式容器侧重于顺序存储,析中关联式容器则强调元素间的文版键值关系,而无序容器可以看作关联式容器的码剖一种。
容器之间的析中关系可以归纳为:序列式容器为基层,关联式容器则在基层基础上构建了更复杂的文版数据结构。例如,heap和priority容器以vector作为底层支持,而set和map则采用红黑树作为基础数据结构。此外,还存在一些非标准容器,如slist和以hash开头的容器。在C++ 中,slist更名为了forward-list,而hash开头的容器改名为了unordered开头。
在容器的实现中,sizeof()函数可能揭示容器的内部大小对比。需要注意的是,尽管在GNU 4.9版本中,一些容器的设计变得复杂,采用了较多的继承结构,但实际上,这些设计在功能上并未带来太大差异。源码 赚钱
熟悉容器的结构后,我们可以从vector入手,探索其内部实现细节。其他容器同样蕴含丰富的学习内容,如在list中,迭代器(iterators)的设计体现了编程的精妙之处;而在set和map中,红黑树的实现展现了数据结构的高效管理。
本文对容器进行了概览,旨在提供一个全面的视角,后续将对vector、list、set、map等容器进行详细分析,揭示其背后的实现机制与设计原理。
STL源码剖析总结笔记(5):认识迭代器的好帮手--list
在深入探讨STL中的`list`容器之前,我们先简要回顾了`vector`的特性以及分配器(`allocator`)的作用。接下来,我们将转向一个具有代表性的容器——`list`。之所以说其具有代表性,是因为`list`利用非连续的空间存储元素,从而在空间利用上更为精确。学习`list`是掌握迭代器机制的第一步。
“list”实质上是双向链表,它具有两个重要特性:前向指针和后向指针。在STL中,`list`节点的定义可能使用`_list_node*`(可能为了兼容性或设计规范)来指代节点结构,其中包含了指向下一个节点和上一个节点的指针。
`list`的内部实现为一个环状的双向链表结构,通过一个指向虚拟尾节点的指针`node`来方便遍历。`begin()`和`end()`方法的实现依赖于这个`node`。此外,进度源码`empty()`、`size()`、`front()`(访问头节点内容)、`back()`(访问尾节点内容)等方法的实现相对直截了当。
`list`的迭代器(`iterator`)设计得更为复杂,因为非连续的空间分配使得简单指针的操作无法直接使用。迭代器需要智能地追踪当前节点及其前后的节点,以便进行递增、递减和取值操作。这要求迭代器实现诸如`++`和`--`等操作符的重载,同时还需要定义至少1-5个`typedef`类型来支持迭代器的基本行为。
`++`操作符的重载遵循前置`++`和后置`++`的区别:前置`++`直接返回计算后的结果(即更新后的迭代器),而后置`++`返回迭代器的副本,避免了在C++中直接对整数进行两次后置`++`的操作,因为这会导致未定义的行为。`*`和`->`操作符用于访问当前节点的数据和成员,后者通过`*`操作符访问节点数据后再通过指针访问成员,确保了数据的安全访问。
`list`的基本操作主要依赖于节点指针的移动和修改,如插入、删除等。这些操作通常需要考虑双向链表的特性以及虚拟尾节点的存在,以避免丢失数据或产生无效指针。例如,`transfer()`方法是一个关键功能,允许将一段连续范围的元素移动到链表中的特定位置,这是许多其他复杂操作的基础。
在`list`中,`transfer()`方法实现了将`[first,last)`范围内的元素移动到指定位置的逻辑,通过调整节点的`next`和`prev`指针来完成移动,同时确保了数据的spectrasuite源码完整性。基于`transfer()`方法,其他高级操作也能够实现,尽管这些操作通常不直接暴露给用户,而是通过封装在`list`内部的实现来提供。
学习`list`不仅有助于理解迭代器的设计原理,也为探索其他容器(如`vector`和`deque`)的实现提供了基础。在接下来的内容中,我们将详细探讨迭代器的实现技巧,以及如何在实际编程中利用这些概念来优化代码。
STL源码剖析9-set、multiset
STL源码深入研究:set与multiset的内部结构详解
1. 结论
在C++标准模板库(STL)中,set和multiset是两种常用的数据结构,它们底层实现依赖于红黑树(rb tree)。set是一种无序的关联容器,不允许有重复元素,而multiset则允许元素重复,但仍然保持插入顺序。
2. set的实现
set内部的红黑树使用了stl_function.h中的仿函数模板参数,这个仿函数用于定义元素的比较规则。set类在stl_set.h文件中定义,它通过这个仿函数确保了元素的唯一性,保证了查找、插入和删除操作的高效性。
3. multiset的特性
与set不同,multiset在stl_multiset.h中定义,它允许元素重复,这主要通过维护每个元素在树中的多个实例来实现。与set一样,它也依赖红黑树的数据结构,但对元素的比较规则更为宽松,允许基于给定的ngork 源码比较仿函数进行重复元素的插入和查找。
STL源码学习(3)- vector详解
STL源码学习(3)- vector详解
vector的迭代器与数据类型:vector内部的连续存储结构使得任何类型的数据指针都可以作为其迭代器。通过迭代器,可以执行诸如指针操作,如访问元素值。 vector定义了两个迭代器start和finish,分别指向元素的起始和终止地址,同时还有一个end_of_storage标记空间的结束位置。vector的容量保证大于等于已分配元素空间,提供了获取空间大小的函数,如front和back的值以引用返回,更高效。 空间配置原理:STL中的vector使用SGI STL容器的二级空间配置器。vector头部包含配置信息,如data_allocator作为空间配置器的别名。简单配置器(simple_alloc)是封装了高级和低级配置器调用的抽象类。 构造函数与内存管理:vector通过空间配置器创建元素。构造函数允许预分配并初始化元素,fill_initialize用于调整空间范围,allocate_and_fill则分配空间并填充。这个过程涉及data_allocator的allocate函数,分配空间并返回起始地址。 vector析构时,调用deallocate函数释放空间。pop_back和erase方法会移除元素并销毁相应空间,clear则清除全部元素。insert操作复杂,根据元素数量和容器状态可能需要扩容。 插入与扩展操作:push_back在末尾插入元素,如果空间不足,可能需要扩容。insert接受三个参数,根据情况处理插入操作,可能抛出异常并销毁部分元素。STL 源码剖析:sort
我大抵是太闲了。
更好的阅读体验。
sort 作为最常用的 STL 之一,大多数人对于其了解仅限于快速排序。
听说其内部实现还包括插入排序和堆排序,于是很好奇,决定通过源代码一探究竟。
个人习惯使用 DEV-C++,不知道其他的编译器会不会有所不同,现阶段也不是很关心。
这个文章并不是析完之后的总结,而是边剖边写。不免有个人的猜测。而且由于本人英语极其差劲,大抵会犯一些憨憨错误。
源码部分sort
首先,在 Dev 中输入以下代码:
然后按住 ctrl,鼠标左键sort,就可以跳转到头文件 stl_algo.h,并可以看到这个:
注释、模板和函数参数不再解释,我们需要关注的是函数体。
但是,中间那一段没看懂……
点进去,是一堆看不懂的#define。
查了一下,感觉这东西不是我这个菜鸡能掌握的。
有兴趣的 戳这里。
那么接下来,就应该去到函数__sort 来一探究竟了。
__sort
通过同样的方法,继续在stl_algo.h 里找到 __sort 的源代码。
同样,只看函数体部分。
一般来说,sort(a,a+n) 是对于区间 [公式] 进行排序,所以排序的前提是 __first != __last。
如果能排序,那么通过两种方式:
一部分一部分的看。
__introsort_loop
最上边注释的翻译:这是排序例程的帮助程序函数。
在传参时,除了首尾迭代器和排序方式,还传了一个std::__lg(__last - __first) * 2,对应 __depth_limit。
while 表示,当区间长度太小时,不进行排序。
_S_threshold 是一个由 enum 定义的数,好像是叫枚举类型。
当__depth_limit 为 [公式] 时,也就是迭代次数较多时,不使用 __introsort_loop,而是使用 __partial_sort(部分排序)。
然后通过__unguarded_partition_pivot,得到一个奇怪的位置(这个函数的翻译是无防护分区枢轴)。
然后递归处理这个奇怪的位置到末位置,再更新末位置,继续循环。
鉴于本人比较好奇无防护分区枢轴是什么,于是先看的__unguarded_partition_pivot。
__unguarded_partition_pivot
首先,找到了中间点。
然后__move_median_to_first(把中间的数移到第一位)。
最后返回__unguarded_partition。
__move_median_to_first
这里的中间数,并不是数列的中间数,而是三个迭代器的中间值。
这三个迭代器分别指向:第二个数,中间的数,最后一个数。
至于为什么取中间的数,暂时还不是很清楚。
`__unguarded_partition`
传参传来的序列第二位到最后。
看着看着,我好像悟了。
这里应该就是实现快速排序的部分。
上边的__move_median_to_first 是为了防止特殊数据卡 [公式] 。经过移动的话,第一个位置就不会是最小值,放在左半序列的数也就不会为 [公式] 。
这样的话,__unguarded_partition 就是快排的主体。
那么,接下来该去看部分排序了。
__partial_sort
这里浅显的理解为堆排序,至于具体实现,在stl_heap.h 里,不属于我们的讨论范围。
(绝对不是因为我懒。)
这样的话,__introsort_loop 就结束了。下一步就要回到 __sort。
__final_insertion_sort
其中某常量为enum { _S_threshold = };。
其中实现的函数有两个:
__insertion_sort
其中的__comp 依然按照默认排序方式 < 来理解。
_GLIBCXX_MOVE_BACKWARD3
进入到_GLIBCXX_MOVE_BACKWARD3,是一个神奇的 #define:
其上就是move_backward:
上边的注释翻译为:
__unguarded_linear_insert
翻译为“无防护线性插入”,应该是指直接插入吧。
当__last 的值比前边元素的值小的时候,就一直进行交换,最后把 __last 放到对应的位置。
__unguarded_insertion_sort
就是直接对区间的每个元素进行插入。
总结
到这里,sort 的源代码就剖完了(除了堆的那部分)。
虽然没怎么看懂,但也理解了,sort 的源码是在快排的基础上,通过堆排序和插入排序来维护时间复杂度的稳定,不至于退化为 [公式] 。
鬼知道我写这么多是为了干嘛……
STL源码剖析总结笔记(3):vector初识
vector是c++中常用且重要的容器之一。相较于固定大小的array,vector拥有动态分配内存的特性,允许它在使用过程中随着元素的增删而自行调整大小。这种动态性使得vector在处理不可预知数据量时更为便捷。
内部结构上,vector使用了数组作为存储基础,并通过start, finish和end of storage三个迭代器进行访问和管理空间。其中,start和finish分别指向可用空间的首端和尾端,end of storage则指向内存块的末尾。在vector大小为字节(位系统下,一个指针占4字节)的情况下,其大小为3。因此,vector可以灵活地通过迭代器定位数据的大小与位置。
内存管理机制是vector的精华之一。当空间耗尽时,vector会自动扩展为二倍的内存容量,以容纳新增元素。此过程涉及创建新空间,复制原有数据,然后释放旧空间,确保资源的有效利用。
vector提供了丰富的迭代器,遵循随机访问的行为,允许直接获取和修改数据,增强操作的效率。这些迭代器简化了对数据结构的遍历与修改操作。
在添加与删除数据时,vector提供了pop_back(), erase, insert等高效方法。例如,pop_back()简单地删除尾部元素,erase允许清除一个范围内的数据,并通过复制来维持数据的连续性。insert操作根据具体需求进行数据的插入与调整,确保结构的完整性与数据的正确性。
综上,vector以其灵活的内存管理和高效的数据操作,成为学习STL和掌握容器结构的理想选择。其清晰的内部机制和丰富的功能特性,为程序设计提供了强大的支持。