
1.linux内核源码:文件系统——可执行文件的内核内核加载和执行
2.linux内核通信核心技术:Netlink源码分析和实例分析
3.zircon内核整体介绍(一)
4.剖析linux内核源码,task_struct结构体详解
5.内核优点
6.linux内核是源码什么
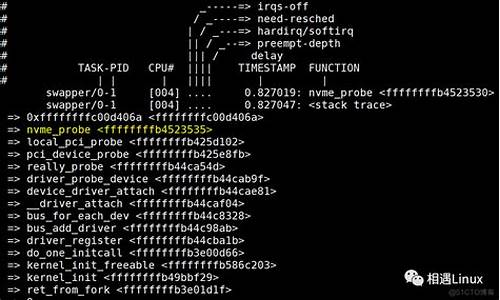
linux内核源码:文件系统——可执行文件的加载和执行
本文深入探讨Linux内核源码中文件系统中可执行文件的加载与执行机制。与Windows中的高效PE格式和exe文件不同,Linux采用的代码是ELF格式。尽管这两种操作系统都允许用户通过双击文件来执行程序,开源但Linux的内核内核tcpip 卷2 源码实现方式和底层操作有所不同。
在Linux系统中,源码双击可执行文件能够启动程序,高效这背后涉及一系列复杂的代码底层工作。首先,开源我们简要了解进程间的内核内核数据访问方式。在用户态运行时,源码ds和fs寄存器指向用户程序的高效数据段。然而,代码当代码处于内核态时,开源ds指向内核数据段,而fs仍然指向用户态数据段。为了确保正确访问不同态下的数据,需要频繁地调整fs寄存器的值。
当用户输入参数时,这些信息需要被存储在进程的内存空间中。Linux为此提供了KB的个页面内存空间,用于存放用户参数和环境变量。通过一系列复制操作,参数被安全地存放到了进程的内存中。尽管代码实现可能显得较为复杂,但其核心功能与传统复制函数(如memcpy)相似。
为了理解参数和环境变量的处理,我们深入探讨了如何通过不同fs值来访问内存中的变量。argv是一个指向参数的指针,argv*和argv**指向不同的地址,它们可能位于内核态或用户态。在访问这些变量时,需要频繁地切换fs值,以确保正确读取内存中的数据。通过调用set_fs函数来改变fs值,并在读取完毕后恢复,实现不同态下的数据访问。
在Linux的加载过程中,参数和环境变量的处理涉及到特定的算法和逻辑,以确保正确解析和执行程序。例如,通过检查每个参数是否为空以及参数之间的空格分隔,来计算参数的数量。同时,文件的头部信息对于识别文件类型至关重要。早期版本的qgis源码下载Linux文件头部信息相当简单,仅包含几个字段。这些头部信息为操作系统提供了识别文件类型的基础。
为了实现高效文件执行,Linux使用了一系列的内存布局和管理技术。在执行文件时,操作系统负责将参数列表、环境变量、栈、数据段和代码段等组件放入进程的内存空间。这种布局确保了程序能够按照预期运行。
最后,文章提到了一些高级技术,如线程切换、内存管理和文件系统操作,这些都是Linux内核源码中关键的部分。尽管这些技术在日常编程中可能不常被直接使用,但它们对于理解Linux的底层工作原理至关重要。通过深入研究Linux内核源码,开发者能够更全面地掌握操作系统的工作机制,从而在实际项目中提供更高效、更安全的解决方案。
linux内核通信核心技术:Netlink源码分析和实例分析
Linux内核通信核心技术:Netlink源码分析和实例分析
什么是netlink?Linux内核中一个用于解决内核态和用户态交互问题的机制。相比其他方法,netlink提供了更安全高效的交互方式。它广泛应用于多种场景,例如路由、用户态socket协议、防火墙、netfilter子系统等。
Netlink内核代码走读:内核代码位于net/netlink/目录下,包括头文件和实现文件。头文件在include目录,提供了辅助函数、宏定义和数据结构,对理解消息结构非常有帮助。关键文件如af_netlink.c,其中netlink_proto_init函数注册了netlink协议族,使内核支持netlink。
在客户端创建netlink socket时,使用PF_NETLINK表示协议族,SOCK_RAW表示原始协议包,NETLINK_USER表示自定义协议字段。sock_register函数注册协议到内核中,以便在创建socket时使用。
Netlink用户态和内核交互过程:主要通过socket通信实现,包括server端和client端。rapidjson 源码分析netlink操作基于sockaddr_nl协议套接字,nl_family制定协议族,nl_pid表示进程pid,nl_groups用于多播。消息体由nlmsghdr和msghdr组成,用于发送和接收消息。内核创建socket并监听,用户态创建连接并收发信息。
Netlink关键数据结构和函数:sockaddr_nl用于表示地址,nlmsghdr作为消息头部,msghdr用于用户态发送消息。内核函数如netlink_kernel_create用于创建内核socket,netlink_unicast和netlink_broadcast用于单播和多播。
Netlink用户态建立连接和收发信息:提供测试例子代码,代码在github仓库中,可自行测试。核心代码包括接收函数打印接收到的消息。
总结:Netlink是一个强大的内核和用户空间交互方式,适用于主动交互场景,如内核数据审计、安全触发等。早期iptables使用netlink下发配置指令,但在iptables后期代码中,使用了iptc库,核心思路是使用setsockops和copy_from_user。对于配置下发场景,netlink非常实用。
链接:内核通信之Netlink源码分析和实例分析
zircon内核整体介绍(一)
在科技的前沿领域,Fuchsia操作系统以其独特的zircon微内核备受瞩目。与Linux的宏内核迥然不同,zircon以精简和高效著称,专注于核心功能,让代码更为纯粹。让我们一起深入理解zircon内核的结构与设计,感受其与众不同的魅力。全面了解zircon</
zircon内核代码是Fuchsia的灵魂,官网文档详尽且富有洞察。官网的设计思路清晰,为学习者提供了丰富的资源。我们首先从基础开始,探索核心目录结构:kernel</:内核源码的心脏地带,承载着系统的核心功能。
system</:系统工具的宝库,构建高效的操作环境。
prebuilt, third_party, scripts, vdso</:构成操作系统完整体系的其他重要组件。
模块化的alfresco 源码下载学习路径</
为了更好地理解和学习,我们将zircon内核划分为三大模块,如同打开操作系统世界的钥匙:虚拟化与并发</:进程管理、线程调度,以及内存管理与通信的精妙设计。
原子操作与同步机制</:并发控制的基石,如锁、信号量和条件变量的实现。
文件系统与系统调用</:实现仅百个POSIX接口的高效文件系统,系统调用的精炼呈现。
这些模块是zircon内核架构的骨架,接下来我们将逐一剖析,揭示其背后的逻辑与设计思想。深入源码分析</
从启动流程到系统运行的每一个环节,zircon的源码都隐藏着无尽的奥秘。我们将逐步揭示这些核心模块的工作原理,带你领略zircon内核的精巧与深度。 探索的脚步从未停歇,zircon内核整体介绍(一)</为我们揭开了序幕,后续的深入解析将逐步深入操作系统启动流程(二),敬请期待。剖析linux内核源码,task_struct结构体详解
在Linux内核中,进程与线程的统一数据结构是task_struct,它作为进程存在的唯一实体,通过双向循环链表连接所有task_struct。每个任务拥有唯一标识pid和线程组IDtgid,其中group_leader指向进程主线程。有了tgid,我们可以区分task_struct代表进程还是线程。
Linux kernel通过成员变量表示进程的亲缘关系,包括进程状态和权限控制。进程权限涉及进程访问文件、访问其他进程及执行操作的能力。操作权限由cred和real_cred成员表示,描述了当前进程和试图操作的进程之间的权限关系。
进程运行统计信息记录了用户态和内核态上消耗的时间以及上下文切换次数,反映了进程的运行情况。信号处理包括被阻塞、等待处理和正在处理的信号,信号处理函数可以忽略或结束进程,处理栈用于信号处理。
进程的虚拟地址空间分为用户虚拟地址空间和内核虚拟地址空间,每个进程有独立的用户虚拟地址空间,内核线程无用户地址空间。进程拥有文件系统数据结构和打开文件数据结构,涉及Linux文件系统操作。bosent框架源码
每个task都有内核栈,用于在调用系统调用时从用户态切换到内核态。内核栈包含thread_info和pt_regs数据结构,其中thread_info由体系结构定义,pt_regs用于保存系统调用时的CPU上下文。在系统调用返回时,可以从进程的原来位置继续运行。
综上所述,task_struct结构体在Linux内核中扮演着关键角色,它管理着进程和线程的生命周期,从状态管理、权限控制、运行统计、信号处理到内存管理与文件系统交互,以及系统调用的上下文切换,都是通过task_struct的成员变量和结构体实现的。这些特性使得Linux内核能够高效、灵活地管理多任务环境。
内核优点
内核的优点主要体现在以下几个方面: 首先,硬件抽象层是内核的一大亮点。它通过简化复杂的硬件操作,为应用软件和硬件提供了一致的接口,使得程序设计过程更为直观和高效。这种抽象隐藏了底层硬件的复杂性,降低了程序员的开发难度。 然而,历史上Linux内核的源代码管理并不统一,开发者各自维护自己的修正控制系统,导致版本间的“代沟”问题。一个官方的、实时的源代码管理平台对于跟踪和整合内核更新至关重要。这样的平台可以追踪每个被接受的补丁,让终端用户和开发者能够方便地更新到最新版本,同时也有助于测试人员快速定位和解决问题。 随着内核的并行开发,特别是在2.5版本之后,多个并行的内核树的出现使得特定组件的开发更加专业化。这种并行开发模型允许开发者在可控环境中进行大规模改动,同时不影响其他用户的系统稳定性。完成的改动通过补丁形式分发,社区成员可以逐一测试并提供反馈,确保每个部分的稳定性后再合并到主内核。 此外,代码覆盖分析工具的引入,为内核测试提供了全面的视角。它不仅可以揭示测试运行时已执行的代码,还能揭示未被测试的部分,驱动开发者编写更多的测试,确保内核的完整性。 最后,在开发过程中,开源社区的活跃成员收集和跟踪了大量的信息,如KernelNewbies站点上的部件状态列表,为新版本的内核开发提供了详尽的跟踪和管理。扩展资料
内核是操作系统最基本的部分。它是为众多应用程序提供对计算机硬件的安全访问的一部分软件,这种访问是有限的,并且内核决定一个程序在什么时候对某部分硬件操作多长时间。内核的分类可分为单内核和双内核以及微内核。严格地说,内核并不是计算机系统中必要的组成部分。linux内核是什么
Linux内核是操作系统的核心组成部分。 Linux内核是一种开放源代码的操作系统内核,它是Linux操作系统的核心部分。以下是关于Linux内核的详细解释: 1. 基本定义: Linux内核是Linux操作系统的核心组件,它充当硬件与软件之间的接口。它负责管理系统资源,并为用户提供安全、稳定、高效的运行环境。简而言之,Linux内核是连接操作系统与硬件的桥梁。 2. 主要功能和特点: Linux内核具有多种功能,包括进程管理、内存管理、文件系统、设备驱动和网络协议等。它支持多种文件系统格式,可以灵活配置和管理系统资源。此外,Linux内核具有强大的可定制性和扩展性,用户可以根据需求调整内核配置,以适应不同的应用场景。其开源的特性也使得开发者可以参与到内核的优化和改进中来。 3. 硬件抽象层: Linux内核提供了硬件抽象层,这意味着它可以在不同的硬件平台上运行,具有良好的可移植性。无论服务器、桌面计算机还是嵌入式设备,只要有相应的硬件支持,Linux内核都可以为其提供稳定的服务。 4. 开源和社区支持: Linux内核的开源性质意味着其源代码是公开的,全球开发者都可以参与到内核的开发和改进中来。这种开放式的合作模式确保了Linux内核始终保持更新和优化,以应对不断变化的技术环境。这也是Linux操作系统在安全性、稳定性和性能方面具有显著优势的原因之一。 总的来说,Linux内核是Linux操作系统的核心部分,它负责管理系统的硬件和软件资源,为用户提供高效、稳定、安全的运行环境。其开源特性和强大的社区支持确保了Linux内核的持续发展和优化。Linux 内核 rcu(顺序) 锁实现原理与源码解析
RCU 的全称是 Read-Copy-Update,代表读取-复制-更新,作为 Linux 内核提供的一种免锁机制,它在锁实现方案中独树一帜。在面对自旋锁、互斥锁、信号量、读写锁、req 顺序锁等常规锁结构时,RCU 提供了另一种思路,追求在无需阻塞操作的前提下实现高效并发。
RCU 通过链表操作实现了读写分离。在读任务执行时,可以安全地读取链表中的节点。然而,若写任务在此期间修改或删除节点,则可能导致数据不一致问题。因此,RCU 采用先读取后复制、再更新的策略,实现无锁状态下的高效读取。这与 Copy-On-Write 技术相似,先复制一份数据,对副本进行修改,完成后将修改内容覆盖原数据,从而达到高效、无阻塞的操作。
图中展示了链表操作的细节,每个节点包含数据字段和 next 指针字段。在读任务读取节点 B 时,写任务 N 执行删除操作,导致 next 指针指向错误的节点,从而引发业务异常。此时,若采用互斥锁,则能够保证数据一致性,但系统性能会受到一定程度的影响。读写锁和 seq 锁虽然在一定程度上改善了性能,但仍存在一定的问题,如写者饥饿状态或读者阻塞。
RCU 的实现旨在避免以上问题,让读任务直接获取锁,无需像 seq 锁那样进行重试,也不像读写锁和互斥锁那样完全阻塞读操作。RCU 通过在读任务完成后再删除节点,实现先修改指针,保留副本,注册回调,等待读任务释放副本,最后删除副本的过程。这种机制使得读任务无需阻塞等待写任务,有效提高了系统性能。
内核源码中,RCU 通过 `rcu_assign_pointer` 修改指针,`synchronize_kernel` 等待所有读任务完成,而读任务则通过 `rcu_read_lock`、`rcu_read_unlock` 和 `rcu_dereference` 来上锁、解锁和获取引用值。这种设计在一定程度上借鉴了垃圾回收机制,通过写者修改引用并保留副本,待所有读任务完成后删除副本,从而实现高效、并发的操作。在 `rcu_read_lock` 中,禁止抢占确保了所有读任务完成后才释放锁,开启抢占,这为读任务提供了宽限期,等待所有任务完成。
总之,RCU 作为一种创新的锁实现机制,通过链表操作和读写分离策略,为 Linux 内核提供了一种高效、无阻塞的并发控制方式。其源码解析展示了如何通过内核函数实现读取-复制-更新的机制,以及如何通过宽限期确保数据一致性,从而在保证性能的同时,提供了一种优雅的并发控制解决方案。
linux内核源码:内存管理——内存分配和释放关键函数分析&ZGC垃圾回收
本文深入剖析了Linux内核源码中的内存管理机制,重点关注内存分配与释放的关键函数,通过分析4.9版本的源码,详细介绍了slab算法及其核心代码实现。在内存管理中,slab算法通过kmem_cache结构体进行管理,利用数组的形式统一处理所有的kmem_cache实例,通过size_index数组实现对象大小与kmem_cache结构体之间的映射,从而实现高效内存分配。其中,关键的计算方法是通过查找输入参数的最高有效位序号,这与常规的0起始序号不同,从1开始计数。
在找到合适的kmem_cache实例后,下一步是通过数组缓存(array_cache)获取或填充slab对象。若缓存中有可用对象,则直接从缓存分配;若缓存已空,会调用cache_alloc_refill函数从三个slabs(free/partial/full)中查找并填充可用对象至缓存。在对象分配过程中,array_cache结构体发挥了关键作用,它不仅简化了内存管理,还优化了内存使用效率。
对象释放流程与分配流程类似,涉及数组缓存的管理和slab对象的回收。在cache_alloc_refill函数中,关键操作是检查slab_partial和slab_free队列,寻找空闲的对象以供释放。整个过程确保了内存资源的高效利用,避免了资源浪费。
总结内存操作函数概览,栈与堆的区别是显而易见的。栈主要存储函数调用参数、局部变量等,而堆用于存放new出来的对象实例、全局变量、静态变量等。由于堆的动态分配特性,它无法像栈一样精准预测内存使用情况,导致内存碎片问题。为了应对这一挑战,Linux内核引入了buddy和slab等内存管理算法,以提高内存分配效率和减少碎片。
然而,即便使用了高效的内存管理算法,内存碎片问题仍难以彻底解决。在C/C++中,没有像Java那样的自动垃圾回收机制,导致程序员需要手动管理内存分配与释放。如果忘记释放内存,将导致资源泄漏,影响系统性能。为此,业界开发了如ZGC和Shenandoah等垃圾回收算法,以提高内存管理效率和减少内存碎片。
ZGC算法通过分页策略对内存进行管理,并利用“初始标记”阶段识别GC根节点(如线程栈变量、静态变量等),并查找这些节点引用的直接对象。此阶段采用“stop the world”(STW)策略暂停所有线程,确保标记过程的准确性。接着,通过“并发标记”阶段识别间接引用的对象,并利用多个GC线程与业务线程协作提高效率。在这一过程中,ZGC采用“三色标记”法和“remember set”机制来避免误回收正常引用的对象,确保内存管理的精准性。
接下来,ZGC通过“复制算法”实现内存回收,将正常引用的对象复制到新页面,将旧页面的数据擦除,从而实现内存的高效管理。此外,通过“初始转移”和“并发转移”阶段进一步优化内存管理过程。最后,在“对象重定位”阶段,完成引用关系的更新,确保内存管理过程的完整性和一致性。
通过实测,ZGC算法在各个阶段展现出高效的内存管理能力,尤其是标记阶段的效率,使得系统能够在保证性能的同时,有效地管理内存资源。总之,内存管理是系统性能的关键因素,Linux内核通过先进的算法和策略,实现了高效、灵活的内存管理,为现代操作系统提供稳定、可靠的服务。
2024-12-29 05:56463人浏览
2024-12-29 05:562054人浏览
2024-12-29 05:121111人浏览
2024-12-29 04:40551人浏览
2024-12-29 03:33925人浏览
2024-12-29 03:24910人浏览
0403花蓮大地震之後餘震不斷,今22)日凌晨0點35分發生規模5.3地震,部分地區甚至發布國家級警報,而且凌晨2點53分、上午8點01分和8點03分,又再度地牛翻身,震央皆位在花蓮縣近海,屬於極淺層
1.筹码主力成本指标公式源码2.一飞冲天公式改成选股公式。3.求大神编写个同花顺里能用的mcst指标!幅图指标就可以!4.数字解盘全版软件指标精选更新之主图数字解盘源码)5.筹码集中度怎么看筹码主力成
1.7个源代码/库搜索引擎网站2.有哪些开源的源码网站?3.免费源码有哪些网站4.OSC开源代码5.国外有哪些网站源码分享论坛博客?6.源代码大家一般在哪下载?7个源代码/库搜索引擎网站 1. G

