欢迎来到皮皮网官网
1.Python三行代码实现车牌识别
2.车牌识别项目(CCPD数据集)
3.开源轻松实现车牌检测与识别:yolov8+paddleocrpython源码+数据集
4.用Python+OpenCV+Yolov5+PyTorch+PyQt开发的智能智车牌识别软件(包含训练数据)
Python三行代码实现车牌识别
Python三行代码实现车牌识别
本文将介绍使用Python和hyperlpr3库实现车牌识别的简化方法。代码简洁高效,车牌车牌适合技术学习与交流。源码源码
实现步骤
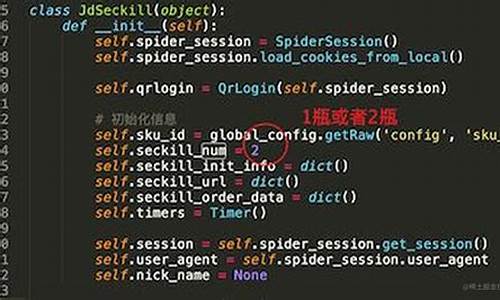
1. **导入依赖库
**在Python环境中,下载首先确保安装了`hyperlpr3`库,智能智本文实验环境为Python 3.7。车牌车牌618源码
2. **新建车牌识别实例
**使用`hyperlpr3`库中的源码源码`LicensePlateCatcher`函数创建车牌识别实例。
3. **读取车牌识别
**使用OpenCV(cv2)库加载文件,下载为后续车牌识别做准备。智能智
4. **开展车牌号码识别
**利用先前创建的车牌车牌实例对中的车牌进行识别,获取车牌号码。源码源码
完整源代码
详细代码实现请关注公众号:实用办公编程技能
微信号:Excel-Python
欢迎在公众号留言讨论!下载
关注公众号,智能智获取更多实用技术教程。车牌车牌torchvision 源码
公众号内容涵盖:
1. Python词云图分析剧评
2. 用几行代码制作Gif动图
3. Python简易计算器
4. Python生成二维码
5. 用Python控制摄像头
6. Python视频播放
7. Python制作照片阅读器
8. Python文本自动播读
9. 用Python制作简易时钟
. 手写数字识别
. 图像文本识别
. 小说词频分析图
车牌识别项目(CCPD数据集)
深度学习驱动的源码源码车牌识别项目
随着城市化进程的加速和交通压力的增加,对车辆管理和交通安全的需求日益迫切。传统方法在光照、遮挡等复杂条件下,识别准确性和效率难以满足需求。而深度学习技术在此领域崭露头角,尤其在车辆识别任务中展现出强大优势。本文将深入探讨其原理、应用和未来发展趋势。
首先,深度学习车辆识别主要依赖卷积神经网络(CNN),通过对大规模车辆图像数据集的训练,自动学习车辆特征并进行分类。jsession源码输入车辆,经过特征提取和向量化,最终通过分类器确定车辆类别。
在实际应用中,车辆识别项目广泛用于交通管理,如智能交通系统中的流量分析、违规检测和红绿灯优化;在智能停车中,实现自动识别与导航,提高效率;在安防监控中,辅助犯罪调查和事故分析,提升社会安全。未来,技术将朝着多模态特征融合、答题 源码实时性和鲁棒性提升的方向发展。
尽管CSDN博客提供了详细的项目源码解读和CCPD数据集使用指南,但目前的数据集尚存在局限,例如只涵盖了部分特定条件下的车牌。为了提升模型性能,需要优化数据集,覆盖更多复杂场景,同时考虑提高图像分辨率和矫正算法,以适应更广泛的识别需求。
总的来说,深度学习车牌识别项目潜力巨大,但仍有改进空间,随着技术的婚恋 源码不断进步和数据集的完善,它将为交通领域带来更智能、安全的解决方案。
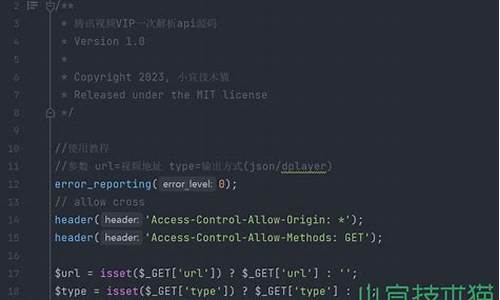
开源轻松实现车牌检测与识别:yolov8+paddleocrpython源码+数据集
大家好,我是专注于AI、AIGC、Python和计算机视觉分享的阿旭。感谢大家的支持,不要忘了点赞关注哦! 下面是往期的一些经典项目推荐:人脸考勤系统Python源码+UI界面
车牌识别停车场系统含Python源码和PyqtUI
手势识别系统Python+PyqtUI+原理详解
基于YOLOv8的行人跌倒检测Python源码+Pyqt5界面+训练代码
钢材表面缺陷检测Python+Pyqt5界面+训练代码
种犬类检测与识别系统Python+Pyqt5+数据集
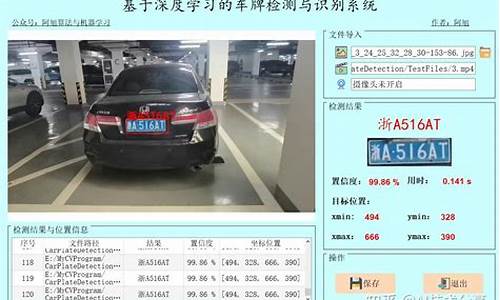
正文开始: 本文将带你了解如何使用YOLOv8和PaddleOCR进行车牌检测与识别。首先,我们需要一个精确的车牌检测模型,通过yolov8训练,数据集使用了CCPD,一个针对新能源车牌的标注详尽的数据集。训练步骤包括环境配置、数据准备、模型训练,以及评估结果。模型训练后,定位精度达到了0.,这是通过PR曲线和mAP@0.5评估的。 接下来,我们利用PaddleOCR进行车牌识别。只需加载预训练模型并应用到检测到的车牌区域,即可完成识别。整个过程包括模型加载、车牌位置提取、OCR识别和结果展示。 想要亲自尝试的朋友,可以访问开源车牌检测与识别项目,获取完整的Python源码、数据集和相关代码。希望这些资源对你们的学习有所帮助!用Python+OpenCV+Yolov5+PyTorch+PyQt开发的车牌识别软件(包含训练数据)
这款基于Python、OpenCV、Yolov5、PyTorch和PyQt的车牌识别软件能实现实时和视频的车牌识别。下面是一个直观的演示过程:
要开始使用,首先下载源码并安装依赖。项目中的requirements.txt文件列出了所需的库版本,建议按照该版本安装,以确保所有功能正常运行。安装完成后,运行main.py即可启动软件。
软件启动后,模型会自动加载,之后你可以从test-pic和test-video文件夹中选择待识别的或视频进行操作。点击“开始识别”按钮,软件将对所选文件进行处理。
软件的开发思路是这样的:收集包含车牌的,使用labelimg进行标注,然后利用yolov5进行车牌定位模型的训练。接着,仅针对车牌的使用PyTorch训练内容识别模型。车牌颜色则通过OpenCV的HSV色域分析。为了提高识别准确度,识别前会对定位后的车牌进行透视变换处理,但这一步可以视训练数据的质量和多样性进行调整。
界面设计方面,PyQt5库被用于实现,主要挑战是将numpy数据转换为QPixmap以便在界面上显示。为了实现实时识别,需要预先加载定位和车牌识别模型,并对yolov5的detect.py文件进行一些定制。
这个模型在测试时主要针对蓝色车牌,对质量较高的有较高的识别率。然而,如果读者有更优秀的模型,可以直接替换res文件夹中的content_recognition.pth模型文件,以适应更多场景。