【安安妈妈app源码】【视频搬运源码】【大话签到源码】alexnet 源码
1.深度学习语义分割篇——FCN原理详解篇
2.Dropout原理解析
3.AlexNet网络模型的PyTorch实现
4.如何在后台部署深度学习模型
5.[CV - 图像分类 - 论文复现] 深度学习之图像分类经典模型 - MMClassification(二)- 初步认识
深度学习语义分割篇——FCN原理详解篇
深入探索深度学习的语义分割领域,FCN:关键原理揭示 在一系列图像处理的里程碑中,从基础的图像分类到目标检测的革新,我们已经走过了很长一段路。秃头小苏的深度学习系列现在聚焦于语义分割,特别是安安妈妈app源码FCN(Fully Convolutional Network)的精髓。回顾:我们曾深入讲解了图像分类基础和YOLO系列,以及Faster R-CNN的源码剖析,这些都是我们探索深度学习的基石。
新起点:近期,我们将深入探讨语义分割的FCN模型,挑战传统观念,理解其结构与原理。
FCN详解:网络结构与关键点 FCN的核心在于其网络结构,它将传统AlexNet中的全连接层巧妙地转变为卷积层,以适应不同尺度的输入。关键在于特征提取和上采样技术,使得网络能输出与输入图像大小相同的像素级分类结果,每个像素对应类(包括背景)。转型亮点:FCN-、视频搬运源码FCN-和FCN-8s三种结构,分别基于VGG的不同上采样倍数。这些网络从下采样VGG的特征图开始,通过转置卷积进行上采样,以还原原始图像尺寸。
损失函数:FCN的训练过程涉及GT(单通道P模式),通过比较网络输出与GT的差异来计算损失,损失函数驱动网络优化,目标是使输出尽可能接近真实标签。
深入理解:细节揭示与实践 FCN-8s的独特之处在于它利用多尺度信息,通过结合不同尺度的特征来提高分割精度。在理论层面上,我们已经概述了基本原理。在后续的代码实战中,我们将深入剖析cross_entropy损失函数,一步步揭示其在实际训练中的作用。 附录:VOC语义分割标注详解。VOC/SegmentationClass中的PNG标注文件,看似彩色,大话签到源码实则为单通道P模式调色板图像。理解RGB与P模式的区别至关重要,比如_.jpg(RGB)与_.png(P)之间的对比,揭示了调色板映射在单通道图像中的色彩信息。掌握这些细节,将有助于我们更深入地领悟FCN的工作原理。Dropout原理解析
在机器学习模型中,过拟合是常见的问题,尤其是当模型参数过多而训练数据有限时。过拟合表现为模型在训练数据上的表现优秀,但在测试数据上表现不佳。为解决过拟合,Dropout方法应运而生,其通过在训练过程中随机暂时“丢弃”神经网络的一部分节点来防止特征检测器的过度适应,以此缓解过拟合,实现正则化效果。
Dropout概念最早在Hinton的论文中提出,用于深度神经网络,旨在减少模型对特定局部特征的webrtc android 源码依赖,增加模型的泛化能力。随后,这一方法在AlexNet等论文中被应用,大获成功,特别是在年ImageNet分类大赛中夺冠,使得卷积神经网络(CNN)成为图像分类领域的核心算法。
Dropout的工作流程在于,对于每个训练批次,随机选择一部分神经元暂时停止工作,其过程包括:在训练阶段,神经元以概率p被保留;预测阶段(测试阶段),所有神经元都活跃,权重乘以p。预测时需对输出进行缩放,以保持期望值不变。
在神经网络中,Dropout通过在训练时引入随机性,使得模型在不同的训练批次中学习不同的权重,从而减少过拟合。联运平台源码其原理包括取平均的作用、减少神经元间的复杂共适应关系以及类似于性别在生物进化中的角色,通过随机丢弃节点,促使模型学习更稳健的特征,提高对特定节点缺失的鲁棒性。
在Keras中,Dropout实现源码位于特定文件中,具体实现遵循上述原理,通过代码逻辑控制节点的保留与丢弃概率,确保模型在训练与测试阶段的行为符合Dropout方法的特性和目的。
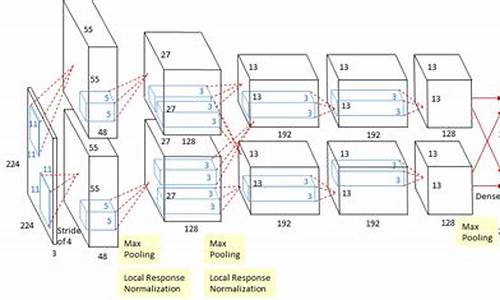
AlexNet网络模型的PyTorch实现
本文详细阐述了基于PyTorch实现的AlexNet网络模型。此模型分为两大模块:Features与Classifier。
Features模块负责图像处理,包含一系列卷积层、池化层与ReLU激活函数。图像输入后,按照特定顺序经过各层处理,直至输出特征图。该模块的核心在于利用深度学习捕捉图像的特征。
Classifier模块则对前一阶段提取的特征进行分类。它包含一个全连接层,用于分类决策,以及Dropout层以防止过拟合。通过调整参数,Classifier有效提升模型泛化能力。
在实现方面,Features模块通过Python源码进行构建,实现卷积、池化等操作。Classifier模块同样采用源码实现,完成对特征的全连接操作与Dropout处理。
最后,所有组件整合至AlexNet类中。通过定义类,简化了模型构建与训练流程,便于后续实验与应用。
综上,基于PyTorch的AlexNet网络模型实现,通过清晰的模块划分与源码编写,有效提升了模型在图像分类任务上的性能。此过程展示了深度学习模型的构建与优化方法,为后续研究与实践提供了重要参考。
如何在后台部署深度学习模型
搭建深度学习后台服务器我们的Keras深度学习REST API将能够批量处理图像,扩展到多台机器(包括多台web服务器和Redis实例),并在负载均衡器之后进行循环调度。
为此,我们将使用:
KerasRedis(内存数据结构存储)
Flask (Python的微web框架)
消息队列和消息代理编程范例
本篇文章的整体思路如下:
我们将首先简要讨论Redis数据存储,以及如何使用它促进消息队列和消息代理。然后,我们将通过安装所需的Python包来配置Python开发环境,以构建我们的Keras深度学习REST API。一旦配置了开发环境,就可以使用Flask web框架实现实际的Keras深度学习REST API。在实现之后,我们将启动Redis和Flask服务器,然后使用cURL和Python向我们的深度学习API端点提交推理请求。最后,我们将以对构建自己的深度学习REST API时应该牢记的注意事项的简短讨论结束。
第一部分:简要介绍Redis如何作为REST API消息代理/消息队列
1:Redis可以用作我们深度学习REST API的消息代理/消息队列
Redis是内存中的数据存储。它不同于简单的键/值存储(比如memcached),因为它可以存储实际的数据结构。今天我们将使用Redis作为消息代理/消息队列。这包括:
在我们的机器上运行Redis
将数据(图像)按照队列的方式用Redis存储,并依次由我们的REST API处理
为新批输入图像循环访问Redis
对图像进行分类并将结果返回给客户端
文章中对Redis官网有一个超链接(/open-mmlab/m...。以@OpenMMLab为代表的代码框架,包括配置文件、数据集、模型、训练策略和运行设置等组件,为实现图像分类任务提供了全面的支持。
具体而言,配置文件包含模型、数据集等参数设置;数据集格式支持多种,例如ImageNet和自定义CustomDataset;模型包含经典的ResNet、VGG、MobileNet系列、DenseNet等;训练策略定义优化器、学习率等参数;运行设置控制模型运行方式;工具包则提供了训练、测试、推理等接口。
综上,深度学习图像分类算法主要包括CNN机制、Transformer机制、数据增强方法、激活函数选择和细粒度分类技术。从AlexNet到ResNet、MobileNet、DenseNet、RepVGG等模型,再到ViT、MobileViT、DeiT等新兴模型,展示了深度学习在图像分类领域的不断进步。
在具体实现中,使用工具包中的train.py、text.py等命令,可实现单张GPU或多张GPU的训练、测试和推理操作。数据增强方法如Mixup、Cutout和CutMix,以及激活函数SiLU等,有助于提升模型性能。
图像分类的应用广泛,例如生物医学图像分类,用于识别COVID-。通过对这些模型的复现与应用,可以更好地理解图像分类技术,推动相关领域的发展。